Note
Click here to download the full example code
Decoding (MVPA)¶
Contents
Design philosophy¶
Decoding (a.k.a. MVPA) in MNE largely follows the machine
learning API of the scikit-learn package.
Each estimator implements fit, transform, fit_transform, and
(optionally) inverse_transform methods. For more details on this design,
visit scikit-learn. For additional theoretical insights into the decoding
framework in MNE 1.
For ease of comprehension, we will denote instantiations of the class using the same name as the class but in small caps instead of camel cases.
Let’s start by loading data for a simple two-class problem:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import mne
from mne.datasets import sample
from mne.decoding import (SlidingEstimator, GeneralizingEstimator, Scaler,
cross_val_multiscore, LinearModel, get_coef,
Vectorizer, CSP)
data_path = sample.data_path()
subjects_dir = data_path + '/subjects'
raw_fname = data_path + '/MEG/sample/sample_audvis_raw.fif'
tmin, tmax = -0.200, 0.500
event_id = {'Auditory/Left': 1, 'Visual/Left': 3} # just use two
raw = mne.io.read_raw_fif(raw_fname, preload=True)
# The subsequent decoding analyses only capture evoked responses, so we can
# low-pass the MEG data. Usually a value more like 40 Hz would be used,
# but here low-pass at 20 so we can more heavily decimate, and allow
# the examlpe to run faster. The 2 Hz high-pass helps improve CSP.
raw.filter(2, 20)
events = mne.find_events(raw, 'STI 014')
# Set up pick list: EEG + MEG - bad channels (modify to your needs)
raw.info['bads'] += ['MEG 2443', 'EEG 053'] # bads + 2 more
# Read epochs
epochs = mne.Epochs(raw, events, event_id, tmin, tmax, proj=True,
picks=('grad', 'eog'), baseline=(None, 0.), preload=True,
reject=dict(grad=4000e-13, eog=150e-6), decim=10)
epochs.pick_types(meg=True, exclude='bads') # remove stim and EOG
del raw
X = epochs.get_data() # MEG signals: n_epochs, n_meg_channels, n_times
y = epochs.events[:, 2] # target: Audio left or right
Out:
Opening raw data file /home/circleci/mne_data/MNE-sample-data/MEG/sample/sample_audvis_raw.fif...
Read a total of 3 projection items:
PCA-v1 (1 x 102) idle
PCA-v2 (1 x 102) idle
PCA-v3 (1 x 102) idle
Range : 25800 ... 192599 = 42.956 ... 320.670 secs
Ready.
Reading 0 ... 166799 = 0.000 ... 277.714 secs...
Filtering raw data in 1 contiguous segment
Setting up band-pass filter from 2 - 20 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 2.00
- Lower transition bandwidth: 2.00 Hz (-6 dB cutoff frequency: 1.00 Hz)
- Upper passband edge: 20.00 Hz
- Upper transition bandwidth: 5.00 Hz (-6 dB cutoff frequency: 22.50 Hz)
- Filter length: 993 samples (1.653 sec)
320 events found
Event IDs: [ 1 2 3 4 5 32]
Not setting metadata
Not setting metadata
145 matching events found
Applying baseline correction (mode: mean)
3 projection items activated
Loading data for 145 events and 421 original time points ...
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
22 bad epochs dropped
Removing projector <Projection | PCA-v1, active : True, n_channels : 102>
Removing projector <Projection | PCA-v2, active : True, n_channels : 102>
Removing projector <Projection | PCA-v3, active : True, n_channels : 102>
Transformation classes¶
Scaler¶
The mne.decoding.Scaler will standardize the data based on channel
scales. In the simplest modes scalings=None or scalings=dict(...),
each data channel type (e.g., mag, grad, eeg) is treated separately and
scaled by a constant. This is the approach used by e.g.,
mne.compute_covariance() to standardize channel scales.
If scalings='mean' or scalings='median', each channel is scaled using
empirical measures. Each channel is scaled independently by the mean and
standand deviation, or median and interquartile range, respectively, across
all epochs and time points during fit
(during training). The transform() method is
called to transform data (training or test set) by scaling all time points
and epochs on a channel-by-channel basis. To perform both the fit and
transform operations in a single call, the
fit_transform() method may be used. To invert the
transform, inverse_transform() can be used. For
scalings='median', scikit-learn version 0.17+ is required.
Note
Using this class is different from directly applying
sklearn.preprocessing.StandardScaler or
sklearn.preprocessing.RobustScaler offered by
scikit-learn. These scale each classification feature, e.g.
each time point for each channel, with mean and standard
deviation computed across epochs, whereas
mne.decoding.Scaler scales each channel using mean and
standard deviation computed across all of its time points
and epochs.
Vectorizer¶
Scikit-learn API provides functionality to chain transformers and estimators
by using sklearn.pipeline.Pipeline. We can construct decoding
pipelines and perform cross-validation and grid-search. However scikit-learn
transformers and estimators generally expect 2D data
(n_samples * n_features), whereas MNE transformers typically output data
with a higher dimensionality
(e.g. n_samples * n_channels * n_frequencies * n_times). A Vectorizer
therefore needs to be applied between the MNE and the scikit-learn steps
like:
# Uses all MEG sensors and time points as separate classification
# features, so the resulting filters used are spatio-temporal
clf = make_pipeline(Scaler(epochs.info),
Vectorizer(),
LogisticRegression(solver='lbfgs'))
scores = cross_val_multiscore(clf, X, y, cv=5, n_jobs=1)
# Mean scores across cross-validation splits
score = np.mean(scores, axis=0)
print('Spatio-temporal: %0.1f%%' % (100 * score,))
Out:
Spatio-temporal: 99.2%
PSDEstimator¶
The mne.decoding.PSDEstimator
computes the power spectral density (PSD) using the multitaper
method. It takes a 3D array as input, converts it into 2D and computes the
PSD.
FilterEstimator¶
The mne.decoding.FilterEstimator filters the 3D epochs data.
Spatial filters¶
Just like temporal filters, spatial filters provide weights to modify the data along the sensor dimension. They are popular in the BCI community because of their simplicity and ability to distinguish spatially-separated neural activity.
Common spatial pattern¶
mne.decoding.CSP is a technique to analyze multichannel data based
on recordings from two classes 2 (see also
https://en.wikipedia.org/wiki/Common_spatial_pattern).
Let \(X \in R^{C\times T}\) be a segment of data with \(C\) channels and \(T\) time points. The data at a single time point is denoted by \(x(t)\) such that \(X=[x(t), x(t+1), ..., x(t+T-1)]\). Common spatial pattern (CSP) finds a decomposition that projects the signal in the original sensor space to CSP space using the following transformation:
where each column of \(W \in R^{C\times C}\) is a spatial filter and each row of \(x_{CSP}\) is a CSP component. The matrix \(W\) is also called the de-mixing matrix in other contexts. Let \(\Sigma^{+} \in R^{C\times C}\) and \(\Sigma^{-} \in R^{C\times C}\) be the estimates of the covariance matrices of the two conditions. CSP analysis is given by the simultaneous diagonalization of the two covariance matrices
where \(\lambda^{C}\) is a diagonal matrix whose entries are the eigenvalues of the following generalized eigenvalue problem
Large entries in the diagonal matrix corresponds to a spatial filter which gives high variance in one class but low variance in the other. Thus, the filter facilitates discrimination between the two classes.
Examples
Note
The winning entry of the Grasp-and-lift EEG competition in Kaggle used
the CSP implementation in MNE and was featured as
a script of the week.
We can use CSP with these data with:
csp = CSP(n_components=3, norm_trace=False)
clf_csp = make_pipeline(csp, LinearModel(LogisticRegression(solver='lbfgs')))
scores = cross_val_multiscore(clf_csp, X, y, cv=5, n_jobs=1)
print('CSP: %0.1f%%' % (100 * scores.mean(),))
Out:
Computing rank from data with rank=None
Using tolerance 4.4e-11 (2.2e-16 eps * 203 dim * 9.7e+02 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 5.2e-11 (2.2e-16 eps * 203 dim * 1.1e+03 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 4.2e-11 (2.2e-16 eps * 203 dim * 9.3e+02 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 5.2e-11 (2.2e-16 eps * 203 dim * 1.2e+03 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 4.2e-11 (2.2e-16 eps * 203 dim * 9.4e+02 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 5.2e-11 (2.2e-16 eps * 203 dim * 1.1e+03 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 4.2e-11 (2.2e-16 eps * 203 dim * 9.4e+02 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 5e-11 (2.2e-16 eps * 203 dim * 1.1e+03 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 4.2e-11 (2.2e-16 eps * 203 dim * 9.3e+02 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 5.2e-11 (2.2e-16 eps * 203 dim * 1.1e+03 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
CSP: 87.0%
Source power comodulation (SPoC)¶
Source Power Comodulation (mne.decoding.SPoC)
3 identifies the composition of
orthogonal spatial filters that maximally correlate with a continuous target.
SPoC can be seen as an extension of the CSP where the target is driven by a continuous variable rather than a discrete variable. Typical applications include extraction of motor patterns using EMG power or audio patterns using sound envelope.
Examples
xDAWN¶
mne.preprocessing.Xdawn is a spatial filtering method designed to
improve the signal to signal + noise ratio (SSNR) of the ERP responses
4. Xdawn was originally
designed for P300 evoked potential by enhancing the target response with
respect to the non-target response. The implementation in MNE-Python is a
generalization to any type of ERP.
Effect-matched spatial filtering¶
The result of mne.decoding.EMS is a spatial filter at each time
point and a corresponding time course 5.
Intuitively, the result gives the similarity between the filter at
each time point and the data vector (sensors) at that time point.
Patterns vs. filters¶
When interpreting the components of the CSP (or spatial filters in general), it is often more intuitive to think about how \(x(t)\) is composed of the different CSP components \(x_{CSP}(t)\). In other words, we can rewrite Equation (1) as follows:
The columns of the matrix \((W^{-1})^T\) are called spatial patterns. This is also called the mixing matrix. The example Linear classifier on sensor data with plot patterns and filters discusses the difference between patterns and filters.
These can be plotted with:
# Fit CSP on full data and plot
csp.fit(X, y)
csp.plot_patterns(epochs.info)
csp.plot_filters(epochs.info, scalings=1e-9)
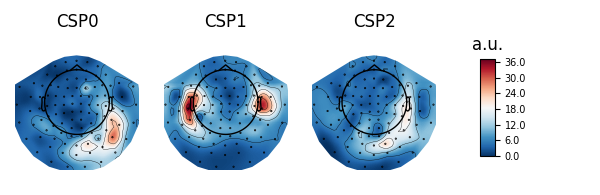
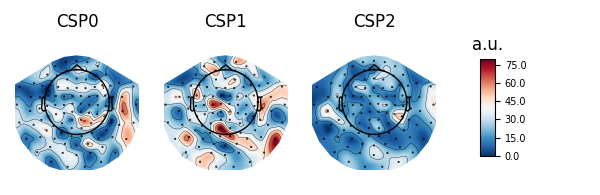
Out:
Computing rank from data with rank=None
Using tolerance 4.8e-11 (2.2e-16 eps * 203 dim * 1.1e+03 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Computing rank from data with rank=None
Using tolerance 5.7e-11 (2.2e-16 eps * 203 dim * 1.3e+03 max singular value)
Estimated rank (mag): 203
MAG: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Decoding over time¶
This strategy consists in fitting a multivariate predictive model on each
time instant and evaluating its performance at the same instant on new
epochs. The mne.decoding.SlidingEstimator will take as input a
pair of features \(X\) and targets \(y\), where \(X\) has
more than 2 dimensions. For decoding over time the data \(X\)
is the epochs data of shape n_epochs x n_channels x n_times. As the
last dimension of \(X\) is the time, an estimator will be fit
on every time instant.
This approach is analogous to SlidingEstimator-based approaches in fMRI, where here we are interested in when one can discriminate experimental conditions and therefore figure out when the effect of interest happens.
When working with linear models as estimators, this approach boils down to estimating a discriminative spatial filter for each time instant.
Temporal decoding¶
We’ll use a Logistic Regression for a binary classification as machine learning model.
# We will train the classifier on all left visual vs auditory trials on MEG
clf = make_pipeline(StandardScaler(), LogisticRegression(solver='lbfgs'))
time_decod = SlidingEstimator(clf, n_jobs=1, scoring='roc_auc', verbose=True)
scores = cross_val_multiscore(time_decod, X, y, cv=5, n_jobs=1)
# Mean scores across cross-validation splits
scores = np.mean(scores, axis=0)
# Plot
fig, ax = plt.subplots()
ax.plot(epochs.times, scores, label='score')
ax.axhline(.5, color='k', linestyle='--', label='chance')
ax.set_xlabel('Times')
ax.set_ylabel('AUC') # Area Under the Curve
ax.legend()
ax.axvline(.0, color='k', linestyle='-')
ax.set_title('Sensor space decoding')
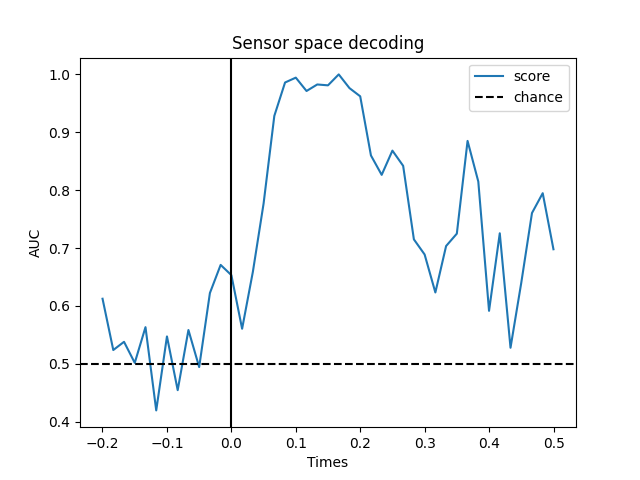
Out:
0%| | Fitting SlidingEstimator : 0/43 [00:00<?, ?it/s]
5%|4 | Fitting SlidingEstimator : 2/43 [00:00<00:00, 49.35it/s]
12%|#1 | Fitting SlidingEstimator : 5/43 [00:00<00:00, 50.13it/s]
19%|#8 | Fitting SlidingEstimator : 8/43 [00:00<00:00, 50.97it/s]
26%|##5 | Fitting SlidingEstimator : 11/43 [00:00<00:00, 51.79it/s]
33%|###2 | Fitting SlidingEstimator : 14/43 [00:00<00:00, 52.66it/s]
40%|###9 | Fitting SlidingEstimator : 17/43 [00:00<00:00, 53.74it/s]
49%|####8 | Fitting SlidingEstimator : 21/43 [00:00<00:00, 55.25it/s]
58%|#####8 | Fitting SlidingEstimator : 25/43 [00:00<00:00, 56.75it/s]
67%|######7 | Fitting SlidingEstimator : 29/43 [00:00<00:00, 57.99it/s]
74%|#######4 | Fitting SlidingEstimator : 32/43 [00:00<00:00, 58.96it/s]
81%|########1 | Fitting SlidingEstimator : 35/43 [00:00<00:00, 59.97it/s]
88%|########8 | Fitting SlidingEstimator : 38/43 [00:00<00:00, 60.95it/s]
95%|#########5| Fitting SlidingEstimator : 41/43 [00:00<00:00, 61.79it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 62.80it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 85.21it/s]
0%| | Fitting SlidingEstimator : 0/43 [00:00<?, ?it/s]
5%|4 | Fitting SlidingEstimator : 2/43 [00:00<00:00, 52.41it/s]
14%|#3 | Fitting SlidingEstimator : 6/43 [00:00<00:00, 53.76it/s]
19%|#8 | Fitting SlidingEstimator : 8/43 [00:00<00:00, 54.01it/s]
28%|##7 | Fitting SlidingEstimator : 12/43 [00:00<00:00, 55.26it/s]
33%|###2 | Fitting SlidingEstimator : 14/43 [00:00<00:00, 55.24it/s]
44%|####4 | Fitting SlidingEstimator : 19/43 [00:00<00:00, 56.93it/s]
53%|#####3 | Fitting SlidingEstimator : 23/43 [00:00<00:00, 58.44it/s]
63%|######2 | Fitting SlidingEstimator : 27/43 [00:00<00:00, 59.82it/s]
70%|######9 | Fitting SlidingEstimator : 30/43 [00:00<00:00, 60.81it/s]
77%|#######6 | Fitting SlidingEstimator : 33/43 [00:00<00:00, 61.74it/s]
86%|########6 | Fitting SlidingEstimator : 37/43 [00:00<00:00, 62.81it/s]
93%|#########3| Fitting SlidingEstimator : 40/43 [00:00<00:00, 63.74it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 64.70it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 90.97it/s]
0%| | Fitting SlidingEstimator : 0/43 [00:00<?, ?it/s]
7%|6 | Fitting SlidingEstimator : 3/43 [00:00<00:00, 80.75it/s]
14%|#3 | Fitting SlidingEstimator : 6/43 [00:00<00:00, 80.80it/s]
19%|#8 | Fitting SlidingEstimator : 8/43 [00:00<00:00, 79.26it/s]
26%|##5 | Fitting SlidingEstimator : 11/43 [00:00<00:00, 79.65it/s]
33%|###2 | Fitting SlidingEstimator : 14/43 [00:00<00:00, 80.07it/s]
40%|###9 | Fitting SlidingEstimator : 17/43 [00:00<00:00, 80.34it/s]
51%|#####1 | Fitting SlidingEstimator : 22/43 [00:00<00:00, 81.91it/s]
60%|###### | Fitting SlidingEstimator : 26/43 [00:00<00:00, 83.18it/s]
70%|######9 | Fitting SlidingEstimator : 30/43 [00:00<00:00, 83.77it/s]
79%|#######9 | Fitting SlidingEstimator : 34/43 [00:00<00:00, 84.26it/s]
86%|########6 | Fitting SlidingEstimator : 37/43 [00:00<00:00, 84.36it/s]
93%|#########3| Fitting SlidingEstimator : 40/43 [00:00<00:00, 84.57it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 85.03it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 92.00it/s]
0%| | Fitting SlidingEstimator : 0/43 [00:00<?, ?it/s]
7%|6 | Fitting SlidingEstimator : 3/43 [00:00<00:00, 75.07it/s]
14%|#3 | Fitting SlidingEstimator : 6/43 [00:00<00:00, 75.14it/s]
19%|#8 | Fitting SlidingEstimator : 8/43 [00:00<00:00, 74.00it/s]
28%|##7 | Fitting SlidingEstimator : 12/43 [00:00<00:00, 75.12it/s]
35%|###4 | Fitting SlidingEstimator : 15/43 [00:00<00:00, 75.21it/s]
44%|####4 | Fitting SlidingEstimator : 19/43 [00:00<00:00, 76.50it/s]
53%|#####3 | Fitting SlidingEstimator : 23/43 [00:00<00:00, 77.88it/s]
63%|######2 | Fitting SlidingEstimator : 27/43 [00:00<00:00, 79.13it/s]
72%|#######2 | Fitting SlidingEstimator : 31/43 [00:00<00:00, 79.79it/s]
79%|#######9 | Fitting SlidingEstimator : 34/43 [00:00<00:00, 80.17it/s]
86%|########6 | Fitting SlidingEstimator : 37/43 [00:00<00:00, 80.56it/s]
93%|#########3| Fitting SlidingEstimator : 40/43 [00:00<00:00, 80.91it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 81.44it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 91.16it/s]
0%| | Fitting SlidingEstimator : 0/43 [00:00<?, ?it/s]
7%|6 | Fitting SlidingEstimator : 3/43 [00:00<00:00, 85.02it/s]
12%|#1 | Fitting SlidingEstimator : 5/43 [00:00<00:00, 83.18it/s]
19%|#8 | Fitting SlidingEstimator : 8/43 [00:00<00:00, 83.42it/s]
26%|##5 | Fitting SlidingEstimator : 11/43 [00:00<00:00, 83.52it/s]
33%|###2 | Fitting SlidingEstimator : 14/43 [00:00<00:00, 83.39it/s]
40%|###9 | Fitting SlidingEstimator : 17/43 [00:00<00:00, 83.64it/s]
51%|#####1 | Fitting SlidingEstimator : 22/43 [00:00<00:00, 85.08it/s]
58%|#####8 | Fitting SlidingEstimator : 25/43 [00:00<00:00, 85.00it/s]
67%|######7 | Fitting SlidingEstimator : 29/43 [00:00<00:00, 86.18it/s]
77%|#######6 | Fitting SlidingEstimator : 33/43 [00:00<00:00, 86.42it/s]
84%|########3 | Fitting SlidingEstimator : 36/43 [00:00<00:00, 86.53it/s]
91%|######### | Fitting SlidingEstimator : 39/43 [00:00<00:00, 85.87it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 87.00it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 91.23it/s]
You can retrieve the spatial filters and spatial patterns if you explicitly use a LinearModel
clf = make_pipeline(StandardScaler(),
LinearModel(LogisticRegression(solver='lbfgs')))
time_decod = SlidingEstimator(clf, n_jobs=1, scoring='roc_auc', verbose=True)
time_decod.fit(X, y)
coef = get_coef(time_decod, 'patterns_', inverse_transform=True)
evoked_time_gen = mne.EvokedArray(coef, epochs.info, tmin=epochs.times[0])
joint_kwargs = dict(ts_args=dict(time_unit='s'),
topomap_args=dict(time_unit='s'))
evoked_time_gen.plot_joint(times=np.arange(0., .500, .100), title='patterns',
**joint_kwargs)
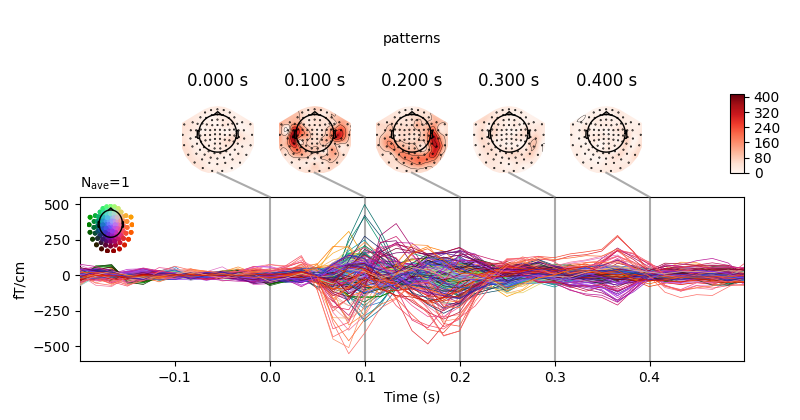
Out:
0%| | Fitting SlidingEstimator : 0/43 [00:00<?, ?it/s]
5%|4 | Fitting SlidingEstimator : 2/43 [00:00<00:01, 29.51it/s]
9%|9 | Fitting SlidingEstimator : 4/43 [00:00<00:01, 30.27it/s]
16%|#6 | Fitting SlidingEstimator : 7/43 [00:00<00:01, 31.29it/s]
21%|## | Fitting SlidingEstimator : 9/43 [00:00<00:01, 32.04it/s]
26%|##5 | Fitting SlidingEstimator : 11/43 [00:00<00:00, 32.53it/s]
33%|###2 | Fitting SlidingEstimator : 14/43 [00:00<00:00, 33.58it/s]
37%|###7 | Fitting SlidingEstimator : 16/43 [00:00<00:00, 34.14it/s]
47%|####6 | Fitting SlidingEstimator : 20/43 [00:00<00:00, 35.32it/s]
56%|#####5 | Fitting SlidingEstimator : 24/43 [00:00<00:00, 36.59it/s]
60%|###### | Fitting SlidingEstimator : 26/43 [00:00<00:00, 37.24it/s]
67%|######7 | Fitting SlidingEstimator : 29/43 [00:00<00:00, 38.19it/s]
74%|#######4 | Fitting SlidingEstimator : 32/43 [00:00<00:00, 39.20it/s]
81%|########1 | Fitting SlidingEstimator : 35/43 [00:00<00:00, 40.32it/s]
86%|########6 | Fitting SlidingEstimator : 37/43 [00:00<00:00, 40.90it/s]
91%|######### | Fitting SlidingEstimator : 39/43 [00:00<00:00, 41.53it/s]
98%|#########7| Fitting SlidingEstimator : 42/43 [00:00<00:00, 42.48it/s]
100%|##########| Fitting SlidingEstimator : 43/43 [00:00<00:00, 69.30it/s]
No projector specified for this dataset. Please consider the method self.add_proj.
Temporal generalization¶
Temporal generalization is an extension of the decoding over time approach. It consists in evaluating whether the model estimated at a particular time instant accurately predicts any other time instant. It is analogous to transferring a trained model to a distinct learning problem, where the problems correspond to decoding the patterns of brain activity recorded at distinct time instants.
The object to for Temporal generalization is
mne.decoding.GeneralizingEstimator. It expects as input \(X\)
and \(y\) (similarly to SlidingEstimator) but
generates predictions from each model for all time instants. The class
GeneralizingEstimator is generic and will treat the
last dimension as the one to be used for generalization testing. For
convenience, here, we refer to it as different tasks. If \(X\)
corresponds to epochs data then the last dimension is time.
This runs the analysis used in 6 and further detailed in 7:
# define the Temporal generalization object
time_gen = GeneralizingEstimator(clf, n_jobs=1, scoring='roc_auc',
verbose=True)
scores = cross_val_multiscore(time_gen, X, y, cv=5, n_jobs=1)
# Mean scores across cross-validation splits
scores = np.mean(scores, axis=0)
# Plot the diagonal (it's exactly the same as the time-by-time decoding above)
fig, ax = plt.subplots()
ax.plot(epochs.times, np.diag(scores), label='score')
ax.axhline(.5, color='k', linestyle='--', label='chance')
ax.set_xlabel('Times')
ax.set_ylabel('AUC')
ax.legend()
ax.axvline(.0, color='k', linestyle='-')
ax.set_title('Decoding MEG sensors over time')
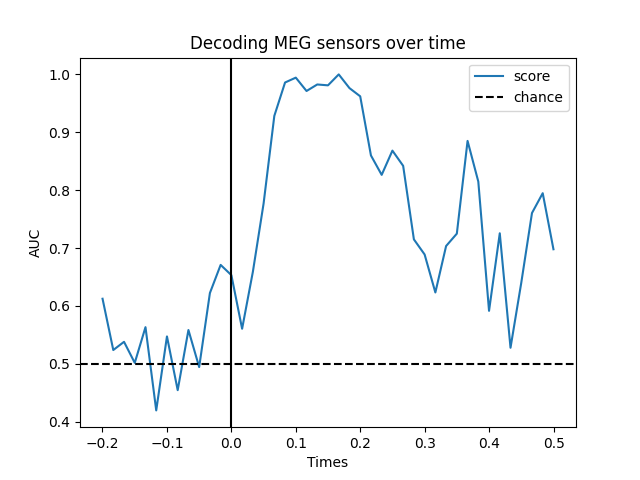
Out:
0%| | Fitting GeneralizingEstimator : 0/43 [00:00<?, ?it/s]
2%|2 | Fitting GeneralizingEstimator : 1/43 [00:00<00:01, 24.72it/s]
9%|9 | Fitting GeneralizingEstimator : 4/43 [00:00<00:01, 25.64it/s]
14%|#3 | Fitting GeneralizingEstimator : 6/43 [00:00<00:01, 26.31it/s]
21%|## | Fitting GeneralizingEstimator : 9/43 [00:00<00:01, 27.16it/s]
28%|##7 | Fitting GeneralizingEstimator : 12/43 [00:00<00:01, 28.12it/s]
35%|###4 | Fitting GeneralizingEstimator : 15/43 [00:00<00:00, 29.11it/s]
42%|####1 | Fitting GeneralizingEstimator : 18/43 [00:00<00:00, 30.07it/s]
51%|#####1 | Fitting GeneralizingEstimator : 22/43 [00:00<00:00, 31.23it/s]
58%|#####8 | Fitting GeneralizingEstimator : 25/43 [00:00<00:00, 32.18it/s]
65%|######5 | Fitting GeneralizingEstimator : 28/43 [00:00<00:00, 33.16it/s]
72%|#######2 | Fitting GeneralizingEstimator : 31/43 [00:00<00:00, 34.23it/s]
77%|#######6 | Fitting GeneralizingEstimator : 33/43 [00:00<00:00, 34.74it/s]
84%|########3 | Fitting GeneralizingEstimator : 36/43 [00:00<00:00, 35.77it/s]
91%|######### | Fitting GeneralizingEstimator : 39/43 [00:00<00:00, 36.78it/s]
98%|#########7| Fitting GeneralizingEstimator : 42/43 [00:00<00:00, 37.85it/s]
100%|##########| Fitting GeneralizingEstimator : 43/43 [00:00<00:00, 76.85it/s]
0%| | Scoring GeneralizingEstimator : 0/1849 [00:00<?, ?it/s]
2%|1 | Scoring GeneralizingEstimator : 35/1849 [00:00<00:01, 1023.98it/s]
4%|3 | Scoring GeneralizingEstimator : 73/1849 [00:00<00:01, 1028.62it/s]
6%|5 | Scoring GeneralizingEstimator : 110/1849 [00:00<00:01, 1031.45it/s]
8%|8 | Scoring GeneralizingEstimator : 148/1849 [00:00<00:01, 1035.64it/s]
10%|# | Scoring GeneralizingEstimator : 185/1849 [00:00<00:01, 1037.92it/s]
12%|#2 | Scoring GeneralizingEstimator : 222/1849 [00:00<00:01, 1040.65it/s]
14%|#4 | Scoring GeneralizingEstimator : 260/1849 [00:00<00:01, 1044.11it/s]
16%|#6 | Scoring GeneralizingEstimator : 298/1849 [00:00<00:01, 1047.87it/s]
18%|#8 | Scoring GeneralizingEstimator : 336/1849 [00:00<00:01, 1051.45it/s]
20%|## | Scoring GeneralizingEstimator : 374/1849 [00:00<00:01, 1054.37it/s]
22%|##2 | Scoring GeneralizingEstimator : 411/1849 [00:00<00:01, 1056.37it/s]
24%|##4 | Scoring GeneralizingEstimator : 449/1849 [00:00<00:01, 1059.29it/s]
26%|##6 | Scoring GeneralizingEstimator : 486/1849 [00:00<00:01, 1060.90it/s]
28%|##8 | Scoring GeneralizingEstimator : 523/1849 [00:00<00:01, 1062.14it/s]
30%|### | Scoring GeneralizingEstimator : 561/1849 [00:00<00:01, 1065.08it/s]
32%|###2 | Scoring GeneralizingEstimator : 599/1849 [00:00<00:01, 1067.81it/s]
34%|###4 | Scoring GeneralizingEstimator : 637/1849 [00:00<00:01, 1070.50it/s]
37%|###6 | Scoring GeneralizingEstimator : 675/1849 [00:00<00:01, 1072.93it/s]
39%|###8 | Scoring GeneralizingEstimator : 714/1849 [00:00<00:01, 1076.03it/s]
41%|#### | Scoring GeneralizingEstimator : 752/1849 [00:00<00:01, 1078.39it/s]
43%|####2 | Scoring GeneralizingEstimator : 790/1849 [00:00<00:00, 1080.64it/s]
45%|####4 | Scoring GeneralizingEstimator : 827/1849 [00:00<00:00, 1081.39it/s]
47%|####6 | Scoring GeneralizingEstimator : 866/1849 [00:00<00:00, 1084.42it/s]
49%|####8 | Scoring GeneralizingEstimator : 904/1849 [00:00<00:00, 1086.38it/s]
51%|##### | Scoring GeneralizingEstimator : 941/1849 [00:00<00:00, 1086.64it/s]
53%|#####2 | Scoring GeneralizingEstimator : 979/1849 [00:00<00:00, 1088.47it/s]
55%|#####4 | Scoring GeneralizingEstimator : 1015/1849 [00:00<00:00, 1086.92it/s]
57%|#####6 | Scoring GeneralizingEstimator : 1052/1849 [00:00<00:00, 1087.27it/s]
59%|#####8 | Scoring GeneralizingEstimator : 1089/1849 [00:00<00:00, 1087.48it/s]
61%|###### | Scoring GeneralizingEstimator : 1127/1849 [00:01<00:00, 1089.20it/s]
63%|######3 | Scoring GeneralizingEstimator : 1165/1849 [00:01<00:00, 1090.65it/s]
65%|######5 | Scoring GeneralizingEstimator : 1203/1849 [00:01<00:00, 1092.07it/s]
67%|######7 | Scoring GeneralizingEstimator : 1241/1849 [00:01<00:00, 1093.45it/s]
69%|######9 | Scoring GeneralizingEstimator : 1279/1849 [00:01<00:00, 1094.83it/s]
71%|#######1 | Scoring GeneralizingEstimator : 1317/1849 [00:01<00:00, 1095.77it/s]
73%|#######3 | Scoring GeneralizingEstimator : 1355/1849 [00:01<00:00, 1096.85it/s]
75%|#######5 | Scoring GeneralizingEstimator : 1393/1849 [00:01<00:00, 1097.75it/s]
77%|#######7 | Scoring GeneralizingEstimator : 1431/1849 [00:01<00:00, 1098.47it/s]
79%|#######9 | Scoring GeneralizingEstimator : 1469/1849 [00:01<00:00, 1099.78it/s]
82%|########1 | Scoring GeneralizingEstimator : 1507/1849 [00:01<00:00, 1101.05it/s]
84%|########3 | Scoring GeneralizingEstimator : 1545/1849 [00:01<00:00, 1102.00it/s]
86%|########5 | Scoring GeneralizingEstimator : 1583/1849 [00:01<00:00, 1102.95it/s]
88%|########7 | Scoring GeneralizingEstimator : 1621/1849 [00:01<00:00, 1103.85it/s]
90%|########9 | Scoring GeneralizingEstimator : 1659/1849 [00:01<00:00, 1104.75it/s]
92%|#########1| Scoring GeneralizingEstimator : 1697/1849 [00:01<00:00, 1105.54it/s]
94%|#########3| Scoring GeneralizingEstimator : 1734/1849 [00:01<00:00, 1105.02it/s]
96%|#########5| Scoring GeneralizingEstimator : 1772/1849 [00:01<00:00, 1105.79it/s]
98%|#########7| Scoring GeneralizingEstimator : 1810/1849 [00:01<00:00, 1105.90it/s]
100%|#########9| Scoring GeneralizingEstimator : 1848/1849 [00:01<00:00, 1106.65it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1111.90it/s]
0%| | Fitting GeneralizingEstimator : 0/43 [00:00<?, ?it/s]
5%|4 | Fitting GeneralizingEstimator : 2/43 [00:00<00:00, 52.93it/s]
12%|#1 | Fitting GeneralizingEstimator : 5/43 [00:00<00:00, 53.79it/s]
19%|#8 | Fitting GeneralizingEstimator : 8/43 [00:00<00:00, 54.56it/s]
26%|##5 | Fitting GeneralizingEstimator : 11/43 [00:00<00:00, 55.32it/s]
33%|###2 | Fitting GeneralizingEstimator : 14/43 [00:00<00:00, 56.26it/s]
40%|###9 | Fitting GeneralizingEstimator : 17/43 [00:00<00:00, 57.27it/s]
49%|####8 | Fitting GeneralizingEstimator : 21/43 [00:00<00:00, 58.71it/s]
58%|#####8 | Fitting GeneralizingEstimator : 25/43 [00:00<00:00, 60.05it/s]
67%|######7 | Fitting GeneralizingEstimator : 29/43 [00:00<00:00, 61.57it/s]
74%|#######4 | Fitting GeneralizingEstimator : 32/43 [00:00<00:00, 62.52it/s]
81%|########1 | Fitting GeneralizingEstimator : 35/43 [00:00<00:00, 63.46it/s]
88%|########8 | Fitting GeneralizingEstimator : 38/43 [00:00<00:00, 64.37it/s]
95%|#########5| Fitting GeneralizingEstimator : 41/43 [00:00<00:00, 65.26it/s]
100%|##########| Fitting GeneralizingEstimator : 43/43 [00:00<00:00, 66.29it/s]
100%|##########| Fitting GeneralizingEstimator : 43/43 [00:00<00:00, 87.61it/s]
0%| | Scoring GeneralizingEstimator : 0/1849 [00:00<?, ?it/s]
2%|2 | Scoring GeneralizingEstimator : 38/1849 [00:00<00:01, 1113.49it/s]
4%|4 | Scoring GeneralizingEstimator : 76/1849 [00:00<00:01, 1113.88it/s]
6%|6 | Scoring GeneralizingEstimator : 114/1849 [00:00<00:01, 1114.26it/s]
8%|8 | Scoring GeneralizingEstimator : 153/1849 [00:00<00:01, 1115.90it/s]
10%|# | Scoring GeneralizingEstimator : 191/1849 [00:00<00:01, 1116.27it/s]
12%|#2 | Scoring GeneralizingEstimator : 230/1849 [00:00<00:01, 1118.12it/s]
15%|#4 | Scoring GeneralizingEstimator : 269/1849 [00:00<00:01, 1119.49it/s]
17%|#6 | Scoring GeneralizingEstimator : 307/1849 [00:00<00:01, 1119.83it/s]
19%|#8 | Scoring GeneralizingEstimator : 346/1849 [00:00<00:01, 1121.32it/s]
21%|## | Scoring GeneralizingEstimator : 384/1849 [00:00<00:01, 1121.29it/s]
23%|##2 | Scoring GeneralizingEstimator : 423/1849 [00:00<00:01, 1122.66it/s]
25%|##4 | Scoring GeneralizingEstimator : 462/1849 [00:00<00:01, 1124.07it/s]
27%|##7 | Scoring GeneralizingEstimator : 500/1849 [00:00<00:01, 1123.50it/s]
29%|##9 | Scoring GeneralizingEstimator : 539/1849 [00:00<00:01, 1124.50it/s]
31%|###1 | Scoring GeneralizingEstimator : 578/1849 [00:00<00:01, 1125.51it/s]
33%|###3 | Scoring GeneralizingEstimator : 616/1849 [00:00<00:01, 1124.92it/s]
35%|###5 | Scoring GeneralizingEstimator : 655/1849 [00:00<00:01, 1125.45it/s]
38%|###7 | Scoring GeneralizingEstimator : 694/1849 [00:00<00:01, 1126.05it/s]
40%|###9 | Scoring GeneralizingEstimator : 733/1849 [00:00<00:00, 1127.39it/s]
42%|####1 | Scoring GeneralizingEstimator : 771/1849 [00:00<00:00, 1127.19it/s]
44%|####3 | Scoring GeneralizingEstimator : 810/1849 [00:00<00:00, 1128.28it/s]
46%|####5 | Scoring GeneralizingEstimator : 848/1849 [00:00<00:00, 1128.13it/s]
48%|####7 | Scoring GeneralizingEstimator : 886/1849 [00:00<00:00, 1127.77it/s]
50%|####9 | Scoring GeneralizingEstimator : 924/1849 [00:00<00:00, 1127.53it/s]
52%|#####2 | Scoring GeneralizingEstimator : 963/1849 [00:00<00:00, 1128.39it/s]
54%|#####4 | Scoring GeneralizingEstimator : 1001/1849 [00:00<00:00, 1127.51it/s]
56%|#####6 | Scoring GeneralizingEstimator : 1039/1849 [00:00<00:00, 1127.38it/s]
58%|#####8 | Scoring GeneralizingEstimator : 1077/1849 [00:00<00:00, 1126.97it/s]
60%|###### | Scoring GeneralizingEstimator : 1116/1849 [00:00<00:00, 1127.77it/s]
62%|######2 | Scoring GeneralizingEstimator : 1154/1849 [00:01<00:00, 1127.55it/s]
64%|######4 | Scoring GeneralizingEstimator : 1192/1849 [00:01<00:00, 1127.32it/s]
67%|######6 | Scoring GeneralizingEstimator : 1231/1849 [00:01<00:00, 1127.99it/s]
69%|######8 | Scoring GeneralizingEstimator : 1270/1849 [00:01<00:00, 1129.04it/s]
71%|####### | Scoring GeneralizingEstimator : 1308/1849 [00:01<00:00, 1128.83it/s]
73%|#######2 | Scoring GeneralizingEstimator : 1347/1849 [00:01<00:00, 1129.81it/s]
75%|#######4 | Scoring GeneralizingEstimator : 1385/1849 [00:01<00:00, 1129.46it/s]
77%|#######6 | Scoring GeneralizingEstimator : 1423/1849 [00:01<00:00, 1129.02it/s]
79%|#######9 | Scoring GeneralizingEstimator : 1461/1849 [00:01<00:00, 1128.67it/s]
81%|########1 | Scoring GeneralizingEstimator : 1500/1849 [00:01<00:00, 1129.95it/s]
83%|########3 | Scoring GeneralizingEstimator : 1538/1849 [00:01<00:00, 1129.70it/s]
85%|########5 | Scoring GeneralizingEstimator : 1576/1849 [00:01<00:00, 1129.40it/s]
87%|########7 | Scoring GeneralizingEstimator : 1615/1849 [00:01<00:00, 1130.23it/s]
89%|########9 | Scoring GeneralizingEstimator : 1653/1849 [00:01<00:00, 1129.63it/s]
91%|#########1| Scoring GeneralizingEstimator : 1691/1849 [00:01<00:00, 1129.37it/s]
94%|#########3| Scoring GeneralizingEstimator : 1729/1849 [00:01<00:00, 1128.73it/s]
96%|#########5| Scoring GeneralizingEstimator : 1767/1849 [00:01<00:00, 1128.32it/s]
98%|#########7| Scoring GeneralizingEstimator : 1806/1849 [00:01<00:00, 1129.49it/s]
100%|#########9| Scoring GeneralizingEstimator : 1844/1849 [00:01<00:00, 1129.22it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1132.23it/s]
0%| | Fitting GeneralizingEstimator : 0/43 [00:00<?, ?it/s]
5%|4 | Fitting GeneralizingEstimator : 2/43 [00:00<00:00, 52.93it/s]
12%|#1 | Fitting GeneralizingEstimator : 5/43 [00:00<00:00, 53.85it/s]
19%|#8 | Fitting GeneralizingEstimator : 8/43 [00:00<00:00, 54.59it/s]
26%|##5 | Fitting GeneralizingEstimator : 11/43 [00:00<00:00, 55.40it/s]
33%|###2 | Fitting GeneralizingEstimator : 14/43 [00:00<00:00, 56.21it/s]
42%|####1 | Fitting GeneralizingEstimator : 18/43 [00:00<00:00, 57.64it/s]
51%|#####1 | Fitting GeneralizingEstimator : 22/43 [00:00<00:00, 59.06it/s]
60%|###### | Fitting GeneralizingEstimator : 26/43 [00:00<00:00, 60.28it/s]
70%|######9 | Fitting GeneralizingEstimator : 30/43 [00:00<00:00, 61.77it/s]
74%|#######4 | Fitting GeneralizingEstimator : 32/43 [00:00<00:00, 61.64it/s]
84%|########3 | Fitting GeneralizingEstimator : 36/43 [00:00<00:00, 63.14it/s]
88%|########8 | Fitting GeneralizingEstimator : 38/43 [00:00<00:00, 62.79it/s]
98%|#########7| Fitting GeneralizingEstimator : 42/43 [00:00<00:00, 64.27it/s]
100%|##########| Fitting GeneralizingEstimator : 43/43 [00:00<00:00, 87.96it/s]
0%| | Scoring GeneralizingEstimator : 0/1849 [00:00<?, ?it/s]
2%|2 | Scoring GeneralizingEstimator : 37/1849 [00:00<00:01, 1090.47it/s]
4%|4 | Scoring GeneralizingEstimator : 74/1849 [00:00<00:01, 1090.45it/s]
6%|6 | Scoring GeneralizingEstimator : 111/1849 [00:00<00:01, 1090.37it/s]
8%|8 | Scoring GeneralizingEstimator : 148/1849 [00:00<00:01, 1089.89it/s]
10%|9 | Scoring GeneralizingEstimator : 184/1849 [00:00<00:01, 1088.24it/s]
12%|#2 | Scoring GeneralizingEstimator : 222/1849 [00:00<00:01, 1089.36it/s]
14%|#4 | Scoring GeneralizingEstimator : 259/1849 [00:00<00:01, 1089.67it/s]
16%|#6 | Scoring GeneralizingEstimator : 298/1849 [00:00<00:01, 1092.68it/s]
18%|#8 | Scoring GeneralizingEstimator : 336/1849 [00:00<00:01, 1094.17it/s]
20%|## | Scoring GeneralizingEstimator : 374/1849 [00:00<00:01, 1095.22it/s]
22%|##2 | Scoring GeneralizingEstimator : 412/1849 [00:00<00:01, 1096.47it/s]
24%|##4 | Scoring GeneralizingEstimator : 451/1849 [00:00<00:01, 1099.01it/s]
26%|##6 | Scoring GeneralizingEstimator : 489/1849 [00:00<00:01, 1100.00it/s]
29%|##8 | Scoring GeneralizingEstimator : 528/1849 [00:00<00:01, 1101.48it/s]
31%|### | Scoring GeneralizingEstimator : 566/1849 [00:00<00:01, 1101.74it/s]
33%|###2 | Scoring GeneralizingEstimator : 604/1849 [00:00<00:01, 1102.72it/s]
35%|###4 | Scoring GeneralizingEstimator : 643/1849 [00:00<00:01, 1104.90it/s]
37%|###6 | Scoring GeneralizingEstimator : 680/1849 [00:00<00:01, 1103.86it/s]
39%|###8 | Scoring GeneralizingEstimator : 718/1849 [00:00<00:01, 1104.16it/s]
41%|#### | Scoring GeneralizingEstimator : 756/1849 [00:00<00:00, 1104.91it/s]
43%|####2 | Scoring GeneralizingEstimator : 795/1849 [00:00<00:00, 1107.04it/s]
45%|####4 | Scoring GeneralizingEstimator : 832/1849 [00:00<00:00, 1106.38it/s]
47%|####7 | Scoring GeneralizingEstimator : 870/1849 [00:00<00:00, 1107.27it/s]
49%|####9 | Scoring GeneralizingEstimator : 909/1849 [00:00<00:00, 1109.34it/s]
51%|#####1 | Scoring GeneralizingEstimator : 947/1849 [00:00<00:00, 1109.93it/s]
53%|#####3 | Scoring GeneralizingEstimator : 985/1849 [00:00<00:00, 1110.56it/s]
55%|#####5 | Scoring GeneralizingEstimator : 1024/1849 [00:00<00:00, 1112.63it/s]
57%|#####7 | Scoring GeneralizingEstimator : 1062/1849 [00:00<00:00, 1113.03it/s]
60%|#####9 | Scoring GeneralizingEstimator : 1101/1849 [00:00<00:00, 1115.02it/s]
62%|######1 | Scoring GeneralizingEstimator : 1139/1849 [00:01<00:00, 1115.40it/s]
64%|######3 | Scoring GeneralizingEstimator : 1178/1849 [00:01<00:00, 1117.02it/s]
66%|######5 | Scoring GeneralizingEstimator : 1216/1849 [00:01<00:00, 1116.98it/s]
68%|######7 | Scoring GeneralizingEstimator : 1255/1849 [00:01<00:00, 1118.66it/s]
70%|######9 | Scoring GeneralizingEstimator : 1293/1849 [00:01<00:00, 1118.95it/s]
72%|#######1 | Scoring GeneralizingEstimator : 1331/1849 [00:01<00:00, 1119.25it/s]
74%|#######4 | Scoring GeneralizingEstimator : 1370/1849 [00:01<00:00, 1120.37it/s]
76%|#######6 | Scoring GeneralizingEstimator : 1408/1849 [00:01<00:00, 1120.58it/s]
78%|#######8 | Scoring GeneralizingEstimator : 1447/1849 [00:01<00:00, 1122.10it/s]
80%|######## | Scoring GeneralizingEstimator : 1485/1849 [00:01<00:00, 1122.27it/s]
82%|########2 | Scoring GeneralizingEstimator : 1522/1849 [00:01<00:00, 1120.66it/s]
84%|########4 | Scoring GeneralizingEstimator : 1561/1849 [00:01<00:00, 1122.30it/s]
86%|########6 | Scoring GeneralizingEstimator : 1598/1849 [00:01<00:00, 1120.27it/s]
88%|########8 | Scoring GeneralizingEstimator : 1636/1849 [00:01<00:00, 1119.51it/s]
91%|######### | Scoring GeneralizingEstimator : 1674/1849 [00:01<00:00, 1119.80it/s]
93%|#########2| Scoring GeneralizingEstimator : 1711/1849 [00:01<00:00, 1118.43it/s]
95%|#########4| Scoring GeneralizingEstimator : 1749/1849 [00:01<00:00, 1118.61it/s]
97%|#########6| Scoring GeneralizingEstimator : 1786/1849 [00:01<00:00, 1117.23it/s]
99%|#########8| Scoring GeneralizingEstimator : 1824/1849 [00:01<00:00, 1117.29it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1117.76it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1119.06it/s]
0%| | Fitting GeneralizingEstimator : 0/43 [00:00<?, ?it/s]
5%|4 | Fitting GeneralizingEstimator : 2/43 [00:00<00:00, 51.86it/s]
12%|#1 | Fitting GeneralizingEstimator : 5/43 [00:00<00:00, 52.65it/s]
19%|#8 | Fitting GeneralizingEstimator : 8/43 [00:00<00:00, 53.47it/s]
26%|##5 | Fitting GeneralizingEstimator : 11/43 [00:00<00:00, 54.44it/s]
33%|###2 | Fitting GeneralizingEstimator : 14/43 [00:00<00:00, 55.48it/s]
40%|###9 | Fitting GeneralizingEstimator : 17/43 [00:00<00:00, 56.51it/s]
49%|####8 | Fitting GeneralizingEstimator : 21/43 [00:00<00:00, 58.02it/s]
58%|#####8 | Fitting GeneralizingEstimator : 25/43 [00:00<00:00, 59.53it/s]
67%|######7 | Fitting GeneralizingEstimator : 29/43 [00:00<00:00, 61.05it/s]
74%|#######4 | Fitting GeneralizingEstimator : 32/43 [00:00<00:00, 62.01it/s]
81%|########1 | Fitting GeneralizingEstimator : 35/43 [00:00<00:00, 62.93it/s]
88%|########8 | Fitting GeneralizingEstimator : 38/43 [00:00<00:00, 63.86it/s]
93%|#########3| Fitting GeneralizingEstimator : 40/43 [00:00<00:00, 63.56it/s]
100%|##########| Fitting GeneralizingEstimator : 43/43 [00:00<00:00, 65.18it/s]
100%|##########| Fitting GeneralizingEstimator : 43/43 [00:00<00:00, 88.61it/s]
0%| | Scoring GeneralizingEstimator : 0/1849 [00:00<?, ?it/s]
2%|2 | Scoring GeneralizingEstimator : 37/1849 [00:00<00:01, 1081.97it/s]
4%|4 | Scoring GeneralizingEstimator : 75/1849 [00:00<00:01, 1083.59it/s]
6%|6 | Scoring GeneralizingEstimator : 113/1849 [00:00<00:01, 1085.60it/s]
8%|8 | Scoring GeneralizingEstimator : 151/1849 [00:00<00:01, 1087.49it/s]
10%|# | Scoring GeneralizingEstimator : 189/1849 [00:00<00:01, 1089.27it/s]
12%|#2 | Scoring GeneralizingEstimator : 228/1849 [00:00<00:01, 1091.75it/s]
14%|#4 | Scoring GeneralizingEstimator : 267/1849 [00:00<00:01, 1094.38it/s]
17%|#6 | Scoring GeneralizingEstimator : 306/1849 [00:00<00:01, 1097.09it/s]
19%|#8 | Scoring GeneralizingEstimator : 345/1849 [00:00<00:01, 1099.68it/s]
21%|## | Scoring GeneralizingEstimator : 384/1849 [00:00<00:01, 1102.14it/s]
23%|##2 | Scoring GeneralizingEstimator : 423/1849 [00:00<00:01, 1103.86it/s]
25%|##4 | Scoring GeneralizingEstimator : 461/1849 [00:00<00:01, 1104.80it/s]
27%|##7 | Scoring GeneralizingEstimator : 500/1849 [00:00<00:01, 1107.21it/s]
29%|##9 | Scoring GeneralizingEstimator : 538/1849 [00:00<00:01, 1107.84it/s]
31%|###1 | Scoring GeneralizingEstimator : 577/1849 [00:00<00:01, 1109.40it/s]
33%|###3 | Scoring GeneralizingEstimator : 616/1849 [00:00<00:01, 1111.58it/s]
35%|###5 | Scoring GeneralizingEstimator : 654/1849 [00:00<00:01, 1112.10it/s]
37%|###7 | Scoring GeneralizingEstimator : 693/1849 [00:00<00:01, 1113.63it/s]
40%|###9 | Scoring GeneralizingEstimator : 732/1849 [00:00<00:01, 1115.02it/s]
42%|####1 | Scoring GeneralizingEstimator : 771/1849 [00:00<00:00, 1116.81it/s]
44%|####3 | Scoring GeneralizingEstimator : 809/1849 [00:00<00:00, 1117.01it/s]
46%|####5 | Scoring GeneralizingEstimator : 847/1849 [00:00<00:00, 1117.10it/s]
48%|####7 | Scoring GeneralizingEstimator : 885/1849 [00:00<00:00, 1117.51it/s]
50%|####9 | Scoring GeneralizingEstimator : 924/1849 [00:00<00:00, 1119.20it/s]
52%|#####2 | Scoring GeneralizingEstimator : 963/1849 [00:00<00:00, 1120.65it/s]
54%|#####4 | Scoring GeneralizingEstimator : 1002/1849 [00:00<00:00, 1122.16it/s]
56%|#####6 | Scoring GeneralizingEstimator : 1040/1849 [00:00<00:00, 1122.24it/s]
58%|#####8 | Scoring GeneralizingEstimator : 1079/1849 [00:00<00:00, 1123.84it/s]
60%|###### | Scoring GeneralizingEstimator : 1117/1849 [00:00<00:00, 1123.89it/s]
63%|######2 | Scoring GeneralizingEstimator : 1156/1849 [00:01<00:00, 1125.32it/s]
65%|######4 | Scoring GeneralizingEstimator : 1194/1849 [00:01<00:00, 1125.26it/s]
67%|######6 | Scoring GeneralizingEstimator : 1233/1849 [00:01<00:00, 1126.30it/s]
69%|######8 | Scoring GeneralizingEstimator : 1272/1849 [00:01<00:00, 1127.62it/s]
71%|####### | Scoring GeneralizingEstimator : 1310/1849 [00:01<00:00, 1127.33it/s]
73%|#######2 | Scoring GeneralizingEstimator : 1349/1849 [00:01<00:00, 1128.69it/s]
75%|#######5 | Scoring GeneralizingEstimator : 1388/1849 [00:01<00:00, 1129.61it/s]
77%|#######7 | Scoring GeneralizingEstimator : 1427/1849 [00:01<00:00, 1130.49it/s]
79%|#######9 | Scoring GeneralizingEstimator : 1466/1849 [00:01<00:00, 1130.78it/s]
81%|########1 | Scoring GeneralizingEstimator : 1504/1849 [00:01<00:00, 1130.22it/s]
83%|########3 | Scoring GeneralizingEstimator : 1543/1849 [00:01<00:00, 1131.21it/s]
86%|########5 | Scoring GeneralizingEstimator : 1582/1849 [00:01<00:00, 1132.27it/s]
88%|########7 | Scoring GeneralizingEstimator : 1621/1849 [00:01<00:00, 1132.76it/s]
90%|########9 | Scoring GeneralizingEstimator : 1659/1849 [00:01<00:00, 1132.30it/s]
92%|#########1| Scoring GeneralizingEstimator : 1698/1849 [00:01<00:00, 1133.05it/s]
94%|#########3| Scoring GeneralizingEstimator : 1737/1849 [00:01<00:00, 1134.07it/s]
96%|#########6| Scoring GeneralizingEstimator : 1776/1849 [00:01<00:00, 1135.06it/s]
98%|#########8| Scoring GeneralizingEstimator : 1814/1849 [00:01<00:00, 1134.42it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1136.37it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1138.20it/s]
0%| | Fitting GeneralizingEstimator : 0/43 [00:00<?, ?it/s]
5%|4 | Fitting GeneralizingEstimator : 2/43 [00:00<00:00, 54.70it/s]
12%|#1 | Fitting GeneralizingEstimator : 5/43 [00:00<00:00, 55.41it/s]
19%|#8 | Fitting GeneralizingEstimator : 8/43 [00:00<00:00, 56.12it/s]
26%|##5 | Fitting GeneralizingEstimator : 11/43 [00:00<00:00, 56.96it/s]
33%|###2 | Fitting GeneralizingEstimator : 14/43 [00:00<00:00, 57.67it/s]
42%|####1 | Fitting GeneralizingEstimator : 18/43 [00:00<00:00, 59.06it/s]
51%|#####1 | Fitting GeneralizingEstimator : 22/43 [00:00<00:00, 60.49it/s]
60%|###### | Fitting GeneralizingEstimator : 26/43 [00:00<00:00, 61.69it/s]
67%|######7 | Fitting GeneralizingEstimator : 29/43 [00:00<00:00, 62.58it/s]
74%|#######4 | Fitting GeneralizingEstimator : 32/43 [00:00<00:00, 63.19it/s]
84%|########3 | Fitting GeneralizingEstimator : 36/43 [00:00<00:00, 64.68it/s]
88%|########8 | Fitting GeneralizingEstimator : 38/43 [00:00<00:00, 64.11it/s]
95%|#########5| Fitting GeneralizingEstimator : 41/43 [00:00<00:00, 65.01it/s]
100%|##########| Fitting GeneralizingEstimator : 43/43 [00:00<00:00, 86.24it/s]
0%| | Scoring GeneralizingEstimator : 0/1849 [00:00<?, ?it/s]
2%|2 | Scoring GeneralizingEstimator : 38/1849 [00:00<00:01, 1122.75it/s]
4%|4 | Scoring GeneralizingEstimator : 77/1849 [00:00<00:01, 1124.02it/s]
6%|6 | Scoring GeneralizingEstimator : 115/1849 [00:00<00:01, 1123.63it/s]
8%|8 | Scoring GeneralizingEstimator : 154/1849 [00:00<00:01, 1124.57it/s]
10%|# | Scoring GeneralizingEstimator : 192/1849 [00:00<00:01, 1123.74it/s]
12%|#2 | Scoring GeneralizingEstimator : 231/1849 [00:00<00:01, 1125.04it/s]
14%|#4 | Scoring GeneralizingEstimator : 268/1849 [00:00<00:01, 1123.55it/s]
16%|#6 | Scoring GeneralizingEstimator : 305/1849 [00:00<00:01, 1122.01it/s]
18%|#8 | Scoring GeneralizingEstimator : 342/1849 [00:00<00:01, 1120.60it/s]
21%|## | Scoring GeneralizingEstimator : 380/1849 [00:00<00:01, 1120.01it/s]
22%|##2 | Scoring GeneralizingEstimator : 416/1849 [00:00<00:01, 1116.45it/s]
25%|##4 | Scoring GeneralizingEstimator : 455/1849 [00:00<00:01, 1118.09it/s]
27%|##6 | Scoring GeneralizingEstimator : 493/1849 [00:00<00:01, 1118.28it/s]
29%|##8 | Scoring GeneralizingEstimator : 531/1849 [00:00<00:01, 1118.26it/s]
31%|### | Scoring GeneralizingEstimator : 569/1849 [00:00<00:01, 1118.13it/s]
33%|###2 | Scoring GeneralizingEstimator : 607/1849 [00:00<00:01, 1118.14it/s]
35%|###4 | Scoring GeneralizingEstimator : 645/1849 [00:00<00:01, 1118.39it/s]
37%|###6 | Scoring GeneralizingEstimator : 683/1849 [00:00<00:01, 1118.33it/s]
39%|###8 | Scoring GeneralizingEstimator : 721/1849 [00:00<00:01, 1118.36it/s]
41%|####1 | Scoring GeneralizingEstimator : 760/1849 [00:00<00:00, 1120.02it/s]
43%|####3 | Scoring GeneralizingEstimator : 798/1849 [00:00<00:00, 1120.15it/s]
45%|####5 | Scoring GeneralizingEstimator : 836/1849 [00:00<00:00, 1120.02it/s]
47%|####7 | Scoring GeneralizingEstimator : 875/1849 [00:00<00:00, 1121.08it/s]
49%|####9 | Scoring GeneralizingEstimator : 913/1849 [00:00<00:00, 1121.15it/s]
51%|#####1 | Scoring GeneralizingEstimator : 951/1849 [00:00<00:00, 1121.03it/s]
53%|#####3 | Scoring GeneralizingEstimator : 989/1849 [00:00<00:00, 1120.93it/s]
56%|#####5 | Scoring GeneralizingEstimator : 1028/1849 [00:00<00:00, 1122.32it/s]
58%|#####7 | Scoring GeneralizingEstimator : 1065/1849 [00:00<00:00, 1120.90it/s]
60%|#####9 | Scoring GeneralizingEstimator : 1103/1849 [00:00<00:00, 1121.09it/s]
62%|######1 | Scoring GeneralizingEstimator : 1141/1849 [00:01<00:00, 1121.02it/s]
64%|######3 | Scoring GeneralizingEstimator : 1179/1849 [00:01<00:00, 1120.98it/s]
66%|######5 | Scoring GeneralizingEstimator : 1218/1849 [00:01<00:00, 1122.15it/s]
68%|######7 | Scoring GeneralizingEstimator : 1256/1849 [00:01<00:00, 1122.05it/s]
70%|######9 | Scoring GeneralizingEstimator : 1293/1849 [00:01<00:00, 1120.64it/s]
72%|#######1 | Scoring GeneralizingEstimator : 1331/1849 [00:01<00:00, 1120.72it/s]
74%|#######3 | Scoring GeneralizingEstimator : 1368/1849 [00:01<00:00, 1119.32it/s]
76%|#######6 | Scoring GeneralizingEstimator : 1406/1849 [00:01<00:00, 1119.11it/s]
78%|#######8 | Scoring GeneralizingEstimator : 1444/1849 [00:01<00:00, 1119.19it/s]
80%|######## | Scoring GeneralizingEstimator : 1482/1849 [00:01<00:00, 1118.91it/s]
82%|########2 | Scoring GeneralizingEstimator : 1520/1849 [00:01<00:00, 1119.05it/s]
84%|########4 | Scoring GeneralizingEstimator : 1558/1849 [00:01<00:00, 1119.27it/s]
86%|########6 | Scoring GeneralizingEstimator : 1597/1849 [00:01<00:00, 1120.44it/s]
88%|########8 | Scoring GeneralizingEstimator : 1635/1849 [00:01<00:00, 1120.63it/s]
91%|######### | Scoring GeneralizingEstimator : 1674/1849 [00:01<00:00, 1122.09it/s]
93%|#########2| Scoring GeneralizingEstimator : 1712/1849 [00:01<00:00, 1121.62it/s]
95%|#########4| Scoring GeneralizingEstimator : 1751/1849 [00:01<00:00, 1123.03it/s]
97%|#########6| Scoring GeneralizingEstimator : 1789/1849 [00:01<00:00, 1122.89it/s]
99%|#########8| Scoring GeneralizingEstimator : 1828/1849 [00:01<00:00, 1124.24it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1124.35it/s]
100%|##########| Scoring GeneralizingEstimator : 1849/1849 [00:01<00:00, 1121.51it/s]
Plot the full (generalization) matrix:
fig, ax = plt.subplots(1, 1)
im = ax.imshow(scores, interpolation='lanczos', origin='lower', cmap='RdBu_r',
extent=epochs.times[[0, -1, 0, -1]], vmin=0., vmax=1.)
ax.set_xlabel('Testing Time (s)')
ax.set_ylabel('Training Time (s)')
ax.set_title('Temporal generalization')
ax.axvline(0, color='k')
ax.axhline(0, color='k')
plt.colorbar(im, ax=ax)
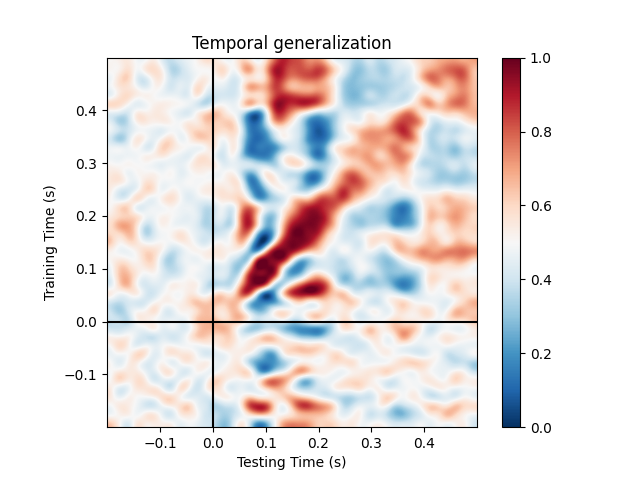
Projecting sensor-space patterns to source space¶
If you use a linear classifier (or regressor) for your data, you can also
project these to source space. For example, using our evoked_time_gen
from before:
cov = mne.compute_covariance(epochs, tmax=0.)
del epochs
fwd = mne.read_forward_solution(
data_path + '/MEG/sample/sample_audvis-meg-eeg-oct-6-fwd.fif')
inv = mne.minimum_norm.make_inverse_operator(
evoked_time_gen.info, fwd, cov, loose=0.)
stc = mne.minimum_norm.apply_inverse(evoked_time_gen, inv, 1. / 9., 'dSPM')
del fwd, inv
Out:
Computing rank from data with rank=None
Using tolerance 3.4e-10 (2.2e-16 eps * 203 dim * 7.6e+03 max singular value)
Estimated rank (grad): 203
GRAD: rank 203 computed from 203 data channels with 0 projectors
Reducing data rank from 203 -> 203
Estimating covariance using EMPIRICAL
Done.
Number of samples used : 1599
[done]
Reading forward solution from /home/circleci/mne_data/MNE-sample-data/MEG/sample/sample_audvis-meg-eeg-oct-6-fwd.fif...
Reading a source space...
Computing patch statistics...
Patch information added...
Distance information added...
[done]
Reading a source space...
Computing patch statistics...
Patch information added...
Distance information added...
[done]
2 source spaces read
Desired named matrix (kind = 3523) not available
Read MEG forward solution (7498 sources, 306 channels, free orientations)
Desired named matrix (kind = 3523) not available
Read EEG forward solution (7498 sources, 60 channels, free orientations)
MEG and EEG forward solutions combined
Source spaces transformed to the forward solution coordinate frame
Computing inverse operator with 203 channels.
203 out of 366 channels remain after picking
Selected 203 channels
Creating the depth weighting matrix...
203 planar channels
limit = 7262/7498 = 10.020866
scale = 2.58122e-08 exp = 0.8
Picked elements from a free-orientation depth-weighting prior into the fixed-orientation one
Average patch normals will be employed in the rotation to the local surface coordinates....
Converting to surface-based source orientations...
[done]
Whitening the forward solution.
Computing rank from covariance with rank=None
Using tolerance 1.6e-13 (2.2e-16 eps * 203 dim * 3.6 max singular value)
Estimated rank (grad): 203
GRAD: rank 203 computed from 203 data channels with 0 projectors
Setting small GRAD eigenvalues to zero (without PCA)
Creating the source covariance matrix
Adjusting source covariance matrix.
Computing SVD of whitened and weighted lead field matrix.
largest singular value = 3.91789
scaling factor to adjust the trace = 6.28301e+18
Preparing the inverse operator for use...
Scaled noise and source covariance from nave = 1 to nave = 1
Created the regularized inverter
The projection vectors do not apply to these channels.
Created the whitener using a noise covariance matrix with rank 203 (0 small eigenvalues omitted)
Computing noise-normalization factors (dSPM)...
[done]
Applying inverse operator to ""...
Picked 203 channels from the data
Computing inverse...
Eigenleads need to be weighted ...
Computing residual...
Explained 76.6% variance
dSPM...
[done]
And this can be visualized using stc.plot:
brain = stc.plot(hemi='split', views=('lat', 'med'), initial_time=0.1,
subjects_dir=subjects_dir)
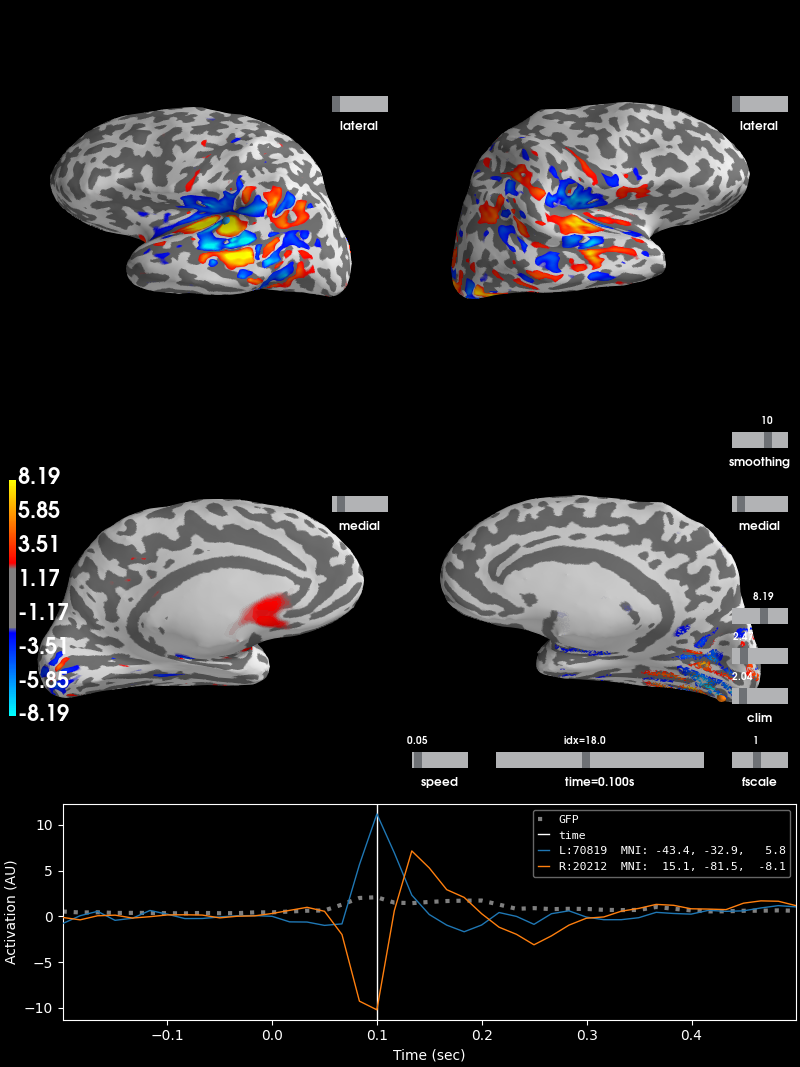
Out:
Using control points [2.03727704 2.4722366 8.19426193]
Source-space decoding¶
Source space decoding is also possible, but because the number of features can be much larger than in the sensor space, univariate feature selection using ANOVA f-test (or some other metric) can be done to reduce the feature dimension. Interpreting decoding results might be easier in source space as compared to sensor space.
Examples
Exercise¶
Explore other datasets from MNE (e.g. Face dataset from SPM to predict Face vs. Scrambled)
References¶
- 1
Jean-Rémi King, Laura Gwilliams, Chris Holdgraf, Jona Sassenhagen, Alexandre Barachant, Denis Engemann, Eric Larson, and Alexandre Gramfort. Encoding and decoding neuronal dynamics: methodological framework to uncover the algorithms of cognition. hal-01848442, 2018. URL: https://hal.archives-ouvertes.fr/hal-01848442.
- 2
Zoltan J. Koles. The quantitative extraction and topographic mapping of the abnormal components in the clinical EEG. Electroencephalography and Clinical Neurophysiology, 79(6):440–447, 1991. doi:10.1016/0013-4694(91)90163-X.
- 3
Sven Dähne, Frank C. Meinecke, Stefan Haufe, Johannes Höhne, Michael Tangermann, Klaus-Robert Müller, and Vadim V. Nikulin. SPoC: a novel framework for relating the amplitude of neuronal oscillations to behaviorally relevant parameters. NeuroImage, 86:111–122, 2014. doi:10.1016/j.neuroimage.2013.07.079.
- 4
Bertrand Rivet, Antoine Souloumiac, Virginie Attina, and Guillaume Gibert. xDAWN algorithm to enhance evoked potentials: application to brain–computer interface. IEEE Transactions on Biomedical Engineering, 56(8):2035–2043, 2009. doi:10.1109/TBME.2009.2012869.
- 5
Aaron Schurger, Sebastien Marti, and Stanislas Dehaene. Reducing multi-sensor data to a single time course that reveals experimental effects. BMC Neuroscience, 2013. doi:10.1186/1471-2202-14-122.
- 6
Jean-Rémi King, Alexandre Gramfort, Aaron Schurger, Lionel Naccache, and Stanislas Dehaene. Two distinct dynamic modes subtend the detection of unexpected sounds. PLoS ONE, 9(1):e85791, 2014. doi:10.1371/journal.pone.0085791.
- 7
Jean-Rémi King and Stanislas Dehaene. Characterizing the dynamics of mental representations: the temporal generalization method. Trends in Cognitive Sciences, 18(4):203–210, 2014. doi:10.1016/j.tics.2014.01.002.
Total running time of the script: ( 0 minutes 48.362 seconds)
Estimated memory usage: 486 MB