Note
Go to the end to download the full example code.
Construct a model RDM#
This example shows how to create RDMs from arbitrary data. A common use case for this is to construct a “model” RDM to RSA against the brain data. In this example, we will create a RDM based on the length of the words shown during an EEG experiment.
# Import required packages
import mne
import mne_rsa
MNE-Python contains a built-in data loader for the kiloword dataset, which is used
here as an example dataset. Since we only need the words shown during the experiment,
which are in the metadata, we can pass preload=False to prevent MNE-Python from
loading the EEG data, which is a nice speed gain.
data_path = mne.datasets.kiloword.data_path(verbose=True)
epochs = mne.read_epochs(data_path / "kword_metadata-epo.fif", preload=False)
# Show the metadata of 10 random epochs
print(epochs.metadata.sample(10))
Reading /home/runner/mne_data/MNE-kiloword-data/kword_metadata-epo.fif ...
Isotrak not found
Found the data of interest:
t = -100.00 ... 920.00 ms
0 CTF compensation matrices available
Adding metadata with 8 columns
960 matching events found
No baseline correction applied
0 projection items activated
WORD Concreteness ... ConsonantVowelProportion VisualComplexity
943 disposal 4.45 ... 0.625000 66.746396
168 courage 1.90 ... 0.428571 69.928589
144 purpose 2.40 ... 0.571429 70.606155
64 uncle 5.60 ... 0.600000 61.525668
779 voice 3.90 ... 0.400000 62.184962
733 term 3.95 ... 0.750000 65.811350
448 conflict 3.75 ... 0.750000 54.200787
98 common 2.80 ... 0.666667 75.608379
545 truck 6.40 ... 0.800000 56.602296
809 broil 4.70 ... 0.600000 55.141335
[10 rows x 8 columns]
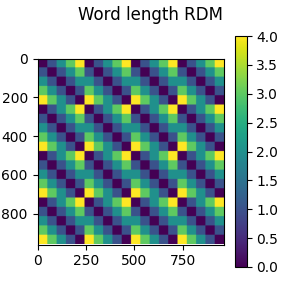
Now we are ready to create the “model” RDM, which will encode the difference in length between the words shown during the experiment.
rdm = mne_rsa.compute_rdm(epochs.metadata.NumberOfLetters, metric="euclidean")
# Plot the RDM
fig = mne_rsa.plot_rdms(rdm, title="Word length RDM")
fig.set_size_inches(3, 3) # Make figure a little bigger to show axis properly
Total running time of the script: (0 minutes 0.212 seconds)