mne_connectivity.spectral_connectivity_time#
- mne_connectivity.spectral_connectivity_time(data, freqs=None, method='coh', average=False, indices=None, sfreq=None, *, fmin=None, fmax=None, fskip=None, fdecim=None, faverage=False, sm_times=0.0, sm_freqs=1, sm_kernel='hanning', padding=0.0, mode='cwt_morlet', mt_bandwidth=None, n_cycles=7.0, gc_n_lags=40, rank=None, n_components=1, decim=1, n_jobs=1, verbose=None)[source]#
Compute time-frequency-domain connectivity measures.
This function computes spectral connectivity over time from epoched data. The data may consist of a single epoch.
The connectivity method(s) are specified using the
methodparameter. All methods are based on time-resolved estimates of the cross- and power spectral densities (CSD/PSD) Sxy and Sxx, Syy.- Parameters:
- dataarray_like, shape (n_epochs, n_signals, n_times) |
Epochs|EpochsTFR The data from which to compute connectivity. Can be epoched time series data as an array-like or
mne.Epochsobject, or Fourier coefficients for each epoch as anmne.time_frequency.EpochsTFRobject. If time series data, the spectral information will be computed according to the spectral estimation mode (see themodeparameter). If anmne.time_frequency.EpochsTFRobject, existing spectral information will be used and themodeparameter will be ignored.Changed in version 0.8: Fourier coefficients stored in an
mne.time_frequency.EpochsTFRobject can also be passed in as data. Storing multitaper weights inmne.time_frequency.EpochsTFRobjects requiresmne >= 1.10.- freqsarray_like |
None Array-like of frequencies of interest for time-frequency decomposition. Only the frequencies within the range specified by
fminandfmaxare used. Ifdatais an array-like ormne.Epochsobject, the frequencies must be specified. Ifdatais anmne.time_frequency.EpochsTFRobject,data.freqsis used and this parameter is ignored.- method
str|listofstr Connectivity measure(s) to compute. These can be
['coh', 'cohy', 'cacoh', 'mic', 'mim', 'plv', 'ciplv', 'pli', 'wpli', 'gc', 'gc_tr']. These are:‘coh’ : Coherence
‘cohy’ : Coherency
‘cacoh’ : Canonical Coherency (CaCoh)
‘mic’ : Maximised Imaginary part of Coherency (MIC)
‘mim’ : Multivariate Interaction Measure (MIM)
‘plv’ : Phase-Locking Value (PLV)
‘ciplv’ : Corrected Imaginary PLV (ciPLV)
‘pli’ : Phase Lag Index (PLI)
‘wpli’ : Weighted PLI (WPLI)
‘gc’ : State-space Granger Causality (GC)
‘gc_tr’ : State-space GC on time-reversed signals
Multivariate methods (
['cacoh', 'mic', 'mim', 'gc', 'gc_tr']) cannot be called with the other methods.- averagebool
Average connectivity scores over epochs. If
True, output will be an instance ofSpectralConnectivity, otherwiseEpochSpectralConnectivity.- indices
tupleof array_like |None Two array-likes with indices of connections for which to compute connectivity. If a bivariate method is called, each array for the seeds and targets should contain the channel indices for the each bivariate connection. If a multivariate method is called, each array for the seeds and targets should consist of nested arrays containing the channel indices for each multivariate connection. If
None, connections between all channels are computed, unless a Granger causality method is called, in which case an error is raised.- sfreq
float|None The sampling frequency. Required if
datais not anmne.Epochsormne.time_frequency.EpochsTFRobject.- fmin
float|tupleoffloat|None The lower frequency of interest. Multiple bands are defined using a tuple, e.g.,
(8., 20.)for two bands with 8 Hz and 20 Hz lower bounds. IfNone, the lowest frequency infreqsis used.- fmax
float|tupleoffloat|None The upper frequency of interest. Multiple bands are defined using a tuple, e.g.
(13., 30.)for two band with 13 Hz and 30 Hz upper bounds. IfNone, the highest frequency infreqsis used.- fskip
int|None Omit every “(fskip + 1)-th” frequency bin to decimate in frequency domain. If
None(default) or 0, no frequency bins are skipped.Deprecated since version 0.8:
fskipis deprecated and will be removed in 0.9. To reduce the number of frequency bins, usefdeciminstead, which offers more standard decimation behaviour.- fdecim
int|None Decimation factor in the frequency domain. Selects every Nth frequency bin from the (time-)frequency decomposition (where N is the value of
fdecim). IfNone(default) or 1, no decimation occurs. The default value will change to 1 in version 0.9.Added in version 0.8.
- faveragebool
Average connectivity scores for each frequency band. If
True, the outputfreqswill be an array of the average frequencies of each band.- sm_times
float Amount of time to consider for the temporal smoothing in seconds. If 0, no temporal smoothing is applied.
- sm_freqs
int Number of points for frequency smoothing. By default, 1 is used which is equivalent to no smoothing.
- sm_kernel
'square'|'hanning' Smoothing kernel type. For
'hanning', seenumpy.hanning().- padding
float Amount of time to consider as padding at the beginning and end of each epoch in seconds. See Notes for more information.
- mode
'multitaper'|'cwt_morlet' Time-frequency decomposition method. See
mne.time_frequency.tfr_array_multitaper()andmne.time_frequency.tfr_array_morlet()for reference. Ignored ifdatais anmne.time_frequency.EpochsTFRobject.- mt_bandwidth
float|None Product between the temporal window length (in seconds) and the full frequency bandwidth (in Hz). This product can be seen as the surface of the window on the time/frequency plane and controls the frequency bandwidth (thus the frequency resolution) and the number of good tapers. See
mne.time_frequency.tfr_array_multitaper()documentation. Ignored ifdatais anmne.time_frequency.EpochsTFRobject.- n_cycles
float| array_like Number of cycles in the wavelet, either a fixed number or one per frequency. The number of cycles
n_cyclesand the frequencies of interestfreqsdefine the temporal window length. For details, seemne.time_frequency.tfr_array_multitaper()andmne.time_frequency.tfr_array_morlet()documentation. Ignored ifdatais anmne.time_frequency.EpochsTFRobject.- gc_n_lags
int Number of lags to use for the vector autoregressive model when computing Granger causality. Higher values increase computational cost, but reduce the degree of spectral smoothing in the results. Only used if
methodcontains any of['gc', 'gc_tr'].- rank
tupleof array_like |None Two array-likes with the rank to project the seed and target data to, respectively, using singular value decomposition. If
None, the rank of the data is computed and projected to. Only used ifmethodcontains any of['cacoh', 'mic', 'mim', 'gc', 'gc_tr'].- n_components
int|None Number of connectivity components to extract from the data. If an int, the number of components must be <= the minimum rank of the seeds and targets. E.g., if the seed channels had a rank of 5 and the target channels had a rank of 3,
n_componentsmust be <= 3. IfNone, the number of components equal to the minimum rank of the seeds and targets is extracted (see therankparameter). Only used ifmethodcontains any of['cacoh', 'mic'].Added in version 0.8.
- decim
int Decimation factor in the time domain. Selects every Nth time bin from the time-frequency decomposition (where N is the value of
decim). If 1 (default), no decimation occurs.- n_jobs
int Number of connections to compute in parallel. Memory mapping must be activated. Please see the Notes section for details.
- verbosebool |
str|int|None If not
None, override default verbose level (seemne.verbose()for more info). If used, it should be passed as a keyword-argument only.
- dataarray_like, shape (n_epochs, n_signals, n_times) |
- Returns:
- coninstance of
EpochSpectralConnectivityorSpectralConnectivity|list Computed connectivity measure(s). An instance of
EpochSpectralConnectivity,SpectralConnectivity, or a list of instances corresponding to connectivity measures if several connectivity measures are specified. The shape of each connectivity dataset is([n_epochs,] n_cons, [n_comps,] n_freqs):n_compsis present for valid multivariate methods ifn_components > 1When
indicesisNoneand a bivariate method is called,n_cons = n_signals ** 2, or if a multivariate method is calledn_cons = 1When
indicesis specified,n_con = len(indices[0])for bivariate and multivariate methods.
- coninstance of
See also
Notes
Please note that the interpretation of the measures in this function depends on the data and underlying assumptions and does not necessarily reflect a causal relationship between brain regions.
The connectivity measures are computed over time within each epoch and optionally averaged over epochs. High connectivity values indicate that the phase coupling (interpreted as estimated connectivity) differences between signals stay consistent over time.
The spectral densities can be estimated using a multitaper method with digital prolate spheroidal sequence (DPSS) windows, or a continuous wavelet transform using Morlet wavelets. The spectral estimation mode is specified using the
modeparameter.When using the multitaper spectral estimation method, the cross-spectral density is computed separately for each taper and aggregated using a weighted average, where the weights correspond to the concentration ratios between the DPSS windows.
Spectral estimation using multitaper or Morlet wavelets introduces edge effects that depend on the length of the wavelet. To remove edge effects, the parameter
paddingcan be used to prune the edges of the signal. Please see the documentation ofmne.time_frequency.tfr_array_multitaper()andmne.time_frequency.tfr_array_morlet()for details on wavelet length (i.e., time window length).Complex multitaper, or Morlet coefficients can also be passed in as data in the form of
mne.time_frequency.EpochsTFRobjects.By default, the connectivity between all signals is computed (only connections corresponding to the lower-triangular part of the connectivity matrix). If one is only interested in the connectivity between some signals, the
indicesparameter can be used. For example, to compute the connectivity between the signal with index 0 and signals “2, 3, 4” (a total of 3 connections) one can use the following:indices = (np.array([0, 0, 0]), # row indices np.array([2, 3, 4])) # col indices con = spectral_connectivity_time(data, method='coh', indices=indices, ...)
In this case
con.get_data().shape = (3, n_freqs). The connectivity scores are in the same order as defined indices.For multivariate methods, this is handled differently. If
indicesisNone, connectivity between all signals will be computed and a single connectivity spectrum will be returned (this is not possible if a Granger causality method is called). Ifindicesis specified, seed and target indices for each connection should be specified as nested array-likes. For example, to compute the connectivity between signals (0, 1) -> (2, 3) and (0, 1) -> (4, 5), indices should be specified as:indices = (np.array([[0, 1], [0, 1]]), # seeds np.array([[2, 3], [4, 5]])) # targets
More information on working with multivariate indices and handling connections where the number of seeds and targets are not equal can be found in the Working with ragged indices for multivariate connectivity example.
Supported Connectivity Measures
The connectivity method(s) is specified using the
methodparameter. The following methods are supported (note:E[]denotes average over epochs). Multiple measures can be computed at once by using a list/tuple, e.g.,['coh', 'pli']to compute coherence and PLI.‘coh’ : Coherence given by:
| E[Sxy] | C = --------------------- sqrt(E[Sxx] * E[Syy])
‘cohy’ : Coherency given by:
E[Sxy] C = --------------------- sqrt(E[Sxx] * E[Syy])
‘cacoh’ : Canonical Coherency (CaCoh) [1] given by:
\(\textrm{CaCoh}=\Large{\frac{\boldsymbol{a}^T\boldsymbol{D} (\Phi)\boldsymbol{b}}{\sqrt{\boldsymbol{a}^T\boldsymbol{a} \boldsymbol{b}^T\boldsymbol{b}}}}\)
where: \(\boldsymbol{D}(\Phi)\) is the cross-spectral density between seeds and targets transformed for a given phase angle \(\Phi\); and \(\boldsymbol{a}\) and \(\boldsymbol{b}\) are eigenvectors for the seeds and targets, such that \(\boldsymbol{a}^T\boldsymbol{D}(\Phi) \boldsymbol{b}\) maximises coherency between the seeds and targets. Taking the absolute value of the results gives maximised coherence.
‘mic’ : Maximised Imaginary part of Coherency (MIC) [2] given by:
\(\textrm{MIC}=\Large{\frac{\boldsymbol{\alpha}^T \boldsymbol{E \beta}}{\parallel\boldsymbol{\alpha}\parallel \parallel\boldsymbol{\beta}\parallel}}\)
where: \(\boldsymbol{E}\) is the imaginary part of the transformed cross-spectral density between seeds and targets; and \(\boldsymbol{\alpha}\) and \(\boldsymbol{\beta}\) are eigenvectors for the seeds and targets, such that \(\boldsymbol{\alpha}^T \boldsymbol{E \beta}\) maximises the imaginary part of coherency between the seeds and targets.
‘mim’ : Multivariate Interaction Measure (MIM) [2] given by:
\(\textrm{MIM}=tr(\boldsymbol{EE}^T)\)
where \(\boldsymbol{E}\) is the imaginary part of the transformed cross-spectral density between seeds and targets.
‘plv’ : Phase-Locking Value (PLV) [3] given by:
PLV = |E[Sxy/|Sxy|]|
‘ciplv’ : Corrected imaginary PLV (ciPLV) [4] given by:
|E[Im(Sxy/|Sxy|)]| ciPLV = ------------------------------------ sqrt(1 - |E[real(Sxy/|Sxy|)]| ** 2)
‘pli’ : Phase Lag Index (PLI) [5] given by:
PLI = |E[sign(Im(Sxy))]|
‘wpli’ : Weighted Phase Lag Index (WPLI) [6] given by:
|E[Im(Sxy)]| WPLI = ------------------ E[|Im(Sxy)|]
‘gc’ : State-space Granger Causality (GC) [7] given by:
\(GC = ln\Large{(\frac{\lvert\boldsymbol{S}_{tt}\rvert}{\lvert \boldsymbol{S}_{tt}-\boldsymbol{H}_{ts}\boldsymbol{\Sigma}_{ss \lvert t}\boldsymbol{H}_{ts}^*\rvert}})\)
where: \(s\) and \(t\) represent the seeds and targets, respectively; \(\boldsymbol{H}\) is the spectral transfer function; \(\boldsymbol{\Sigma}\) is the residuals matrix of the autoregressive model; and \(\boldsymbol{S}\) is \(\boldsymbol{\Sigma}\) transformed by \(\boldsymbol{H}\).
‘gc_tr’ : State-space GC on time-reversed signals [7][8] given by the same equation as for
'gc', but where the autocovariance sequence from which the autoregressive model is produced is transposed to mimic the reversal of the original signal in time [9].Parallel computation can be activated by setting the
n_jobsparameter. Under the hood, this utilizes thejobliblibrary. For effective parallelization, you should activate memory mapping in MNE-Python by settingMNE_MEMMAP_MIN_SIZEandMNE_CACHE_DIR. Activating memory mapping will makejoblibstore arrays greater than the minimum size on disc, and forego direct RAM access for more efficient processing. For example, in your code, run:mne.set_config('MNE_MEMMAP_MIN_SIZE', '10M') mne.set_config('MNE_CACHE_DIR', '/dev/shm')
When
MNE_MEMMAP_MIN_SIZE=None, the underlyingjoblibimplementation results in pickling and unpickling the whole array each time a pair of indices is accessed, which is slow, compared to memory mapping the array.This function is based on the
frites.conn.conn_specimplementation in Frites.Added in version 0.3.
References
Examples using mne_connectivity.spectral_connectivity_time#
Comparing spectral connectivity computed over time or over trials
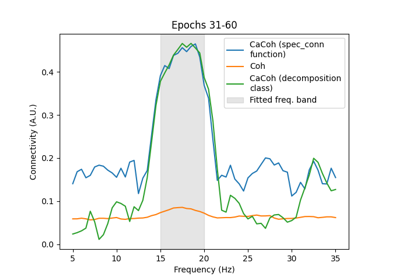
Multivariate decomposition for efficient connectivity analysis