Note
Go to the end to download the full example code
Compute and visualize ERDS maps#
This example calculates and displays ERDS maps of event-related EEG data. ERDS (sometimes also written as ERD/ERS) is short for event-related desynchronization (ERD) and event-related synchronization (ERS) [1]. Conceptually, ERD corresponds to a decrease in power in a specific frequency band relative to a baseline. Similarly, ERS corresponds to an increase in power. An ERDS map is a time/frequency representation of ERD/ERS over a range of frequencies [2]. ERDS maps are also known as ERSP (event-related spectral perturbation) [3].
In this example, we use an EEG BCI data set containing two different motor imagery tasks (imagined hand and feet movement). Our goal is to generate ERDS maps for each of the two tasks.
First, we load the data and create epochs of 5s length. The data set contains multiple channels, but we will only consider C3, Cz, and C4. We compute maps containing frequencies ranging from 2 to 35Hz. We map ERD to red color and ERS to blue color, which is customary in many ERDS publications. Finally, we perform cluster-based permutation tests to estimate significant ERDS values (corrected for multiple comparisons within channels).
# Authors: Clemens Brunner <clemens.brunner@gmail.com>
# Felix Klotzsche <klotzsche@cbs.mpg.de>
#
# License: BSD-3-Clause
# Copyright the MNE-Python contributors.
As usual, we import everything we need.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib.colors import TwoSlopeNorm
import mne
from mne.datasets import eegbci
from mne.io import concatenate_raws, read_raw_edf
from mne.stats import permutation_cluster_1samp_test as pcluster_test
from mne.time_frequency import tfr_multitaper
First, we load and preprocess the data. We use runs 6, 10, and 14 from subject 1 (these runs contains hand and feet motor imagery).
fnames = eegbci.load_data(subject=1, runs=(6, 10, 14))
raw = concatenate_raws([read_raw_edf(f, preload=True) for f in fnames])
raw.rename_channels(lambda x: x.strip(".")) # remove dots from channel names
events, _ = mne.events_from_annotations(raw, event_id=dict(T1=2, T2=3))
Extracting EDF parameters from /home/circleci/mne_data/MNE-eegbci-data/files/eegmmidb/1.0.0/S001/S001R06.edf...
EDF file detected
Setting channel info structure...
Creating raw.info structure...
Reading 0 ... 19999 = 0.000 ... 124.994 secs...
Extracting EDF parameters from /home/circleci/mne_data/MNE-eegbci-data/files/eegmmidb/1.0.0/S001/S001R10.edf...
EDF file detected
Setting channel info structure...
Creating raw.info structure...
Reading 0 ... 19999 = 0.000 ... 124.994 secs...
Extracting EDF parameters from /home/circleci/mne_data/MNE-eegbci-data/files/eegmmidb/1.0.0/S001/S001R14.edf...
EDF file detected
Setting channel info structure...
Creating raw.info structure...
Reading 0 ... 19999 = 0.000 ... 124.994 secs...
Used Annotations descriptions: ['T1', 'T2']
Now we can create 5-second epochs around events of interest.
Not setting metadata
45 matching events found
No baseline correction applied
0 projection items activated
Using data from preloaded Raw for 45 events and 961 original time points ...
0 bad epochs dropped
Here we set suitable values for computing ERDS maps. Note especially the
cnorm variable, which sets up an asymmetric colormap where the middle
color is mapped to zero, even though zero is not the middle value of the
colormap range. This does two things: it ensures that zero values will be
plotted in white (given that below we select the RdBu colormap), and it
makes synchronization and desynchronization look equally prominent in the
plots, even though their extreme values are of different magnitudes.
freqs = np.arange(2, 36) # frequencies from 2-35Hz
vmin, vmax = -1, 1.5 # set min and max ERDS values in plot
baseline = (-1, 0) # baseline interval (in s)
cnorm = TwoSlopeNorm(vmin=vmin, vcenter=0, vmax=vmax) # min, center & max ERDS
kwargs = dict(
n_permutations=100, step_down_p=0.05, seed=1, buffer_size=None, out_type="mask"
) # for cluster test
Finally, we perform time/frequency decomposition over all epochs.
tfr = tfr_multitaper(
epochs,
freqs=freqs,
n_cycles=freqs,
use_fft=True,
return_itc=False,
average=False,
decim=2,
)
tfr.crop(tmin, tmax).apply_baseline(baseline, mode="percent")
for event in event_ids:
# select desired epochs for visualization
tfr_ev = tfr[event]
fig, axes = plt.subplots(
1, 4, figsize=(12, 4), gridspec_kw={"width_ratios": [10, 10, 10, 1]}
)
for ch, ax in enumerate(axes[:-1]): # for each channel
# positive clusters
_, c1, p1, _ = pcluster_test(tfr_ev.data[:, ch], tail=1, **kwargs)
# negative clusters
_, c2, p2, _ = pcluster_test(tfr_ev.data[:, ch], tail=-1, **kwargs)
# note that we keep clusters with p <= 0.05 from the combined clusters
# of two independent tests; in this example, we do not correct for
# these two comparisons
c = np.stack(c1 + c2, axis=2) # combined clusters
p = np.concatenate((p1, p2)) # combined p-values
mask = c[..., p <= 0.05].any(axis=-1)
# plot TFR (ERDS map with masking)
tfr_ev.average().plot(
[ch],
cmap="RdBu",
cnorm=cnorm,
axes=ax,
colorbar=False,
show=False,
mask=mask,
mask_style="mask",
)
ax.set_title(epochs.ch_names[ch], fontsize=10)
ax.axvline(0, linewidth=1, color="black", linestyle=":") # event
if ch != 0:
ax.set_ylabel("")
ax.set_yticklabels("")
fig.colorbar(axes[0].images[-1], cax=axes[-1]).ax.set_yscale("linear")
fig.suptitle(f"ERDS ({event})")
plt.show()
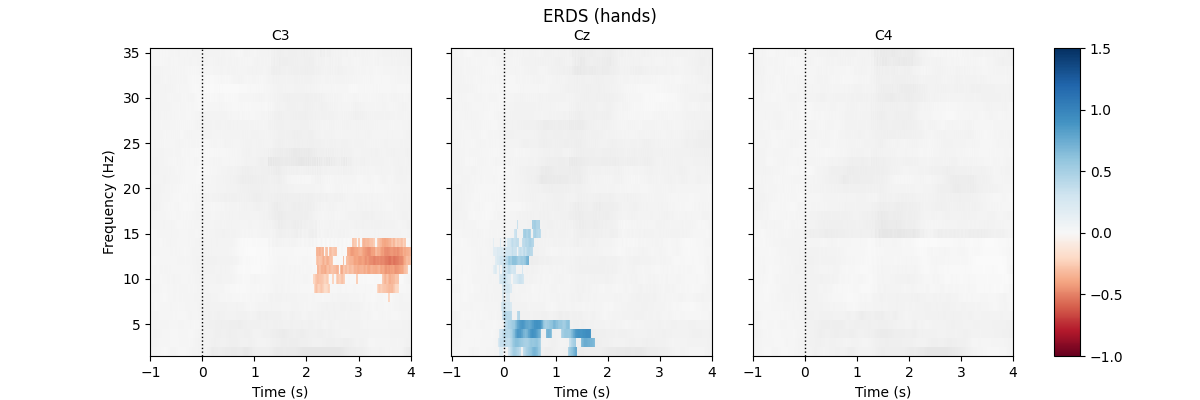
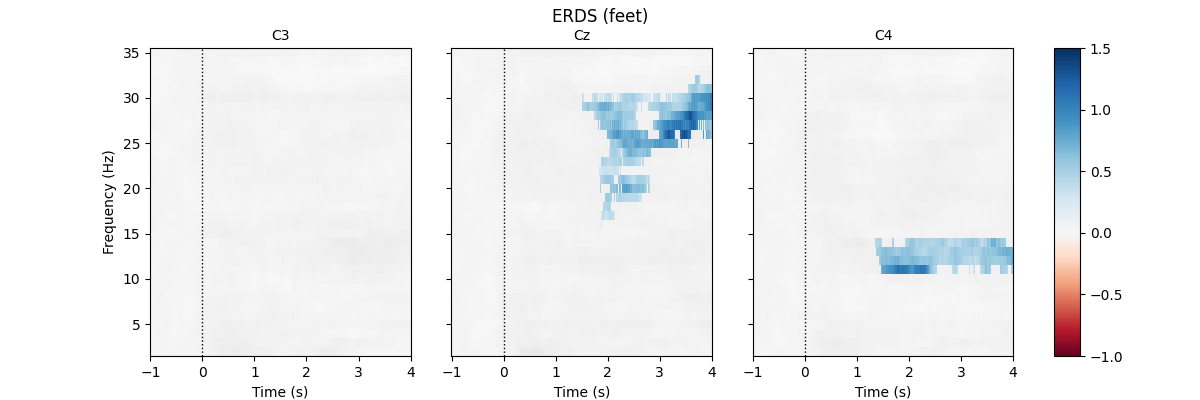
Not setting metadata
Applying baseline correction (mode: percent)
Using a threshold of 1.724718
stat_fun(H1): min=-8.552076 max=3.183231
Running initial clustering …
Found 80 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
9%|▉ | Permuting : 9/99 [00:00<00:00, 261.12it/s]
20%|██ | Permuting : 20/99 [00:00<00:00, 293.57it/s]
31%|███▏ | Permuting : 31/99 [00:00<00:00, 304.83it/s]
43%|████▎ | Permuting : 43/99 [00:00<00:00, 318.16it/s]
57%|█████▋ | Permuting : 56/99 [00:00<00:00, 332.79it/s]
69%|██████▊ | Permuting : 68/99 [00:00<00:00, 337.05it/s]
81%|████████ | Permuting : 80/99 [00:00<00:00, 340.03it/s]
94%|█████████▍| Permuting : 93/99 [00:00<00:00, 346.63it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 337.14it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 334.91it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
Using a threshold of -1.724718
stat_fun(H1): min=-8.552076 max=3.183231
Running initial clustering …
Found 67 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
9%|▉ | Permuting : 9/99 [00:00<00:00, 266.17it/s]
19%|█▉ | Permuting : 19/99 [00:00<00:00, 281.14it/s]
28%|██▊ | Permuting : 28/99 [00:00<00:00, 276.05it/s]
37%|███▋ | Permuting : 37/99 [00:00<00:00, 273.26it/s]
46%|████▋ | Permuting : 46/99 [00:00<00:00, 271.59it/s]
56%|█████▌ | Permuting : 55/99 [00:00<00:00, 270.64it/s]
66%|██████▌ | Permuting : 65/99 [00:00<00:00, 274.89it/s]
75%|███████▍ | Permuting : 74/99 [00:00<00:00, 273.62it/s]
85%|████████▍ | Permuting : 84/99 [00:00<00:00, 276.56it/s]
96%|█████████▌| Permuting : 95/99 [00:00<00:00, 282.59it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 281.98it/s]
Step-down-in-jumps iteration #1 found 1 cluster to exclude from subsequent iterations
0%| | Permuting : 0/99 [00:00<?, ?it/s]
11%|█ | Permuting : 11/99 [00:00<00:00, 324.80it/s]
22%|██▏ | Permuting : 22/99 [00:00<00:00, 324.83it/s]
33%|███▎ | Permuting : 33/99 [00:00<00:00, 325.25it/s]
45%|████▌ | Permuting : 45/99 [00:00<00:00, 333.40it/s]
57%|█████▋ | Permuting : 56/99 [00:00<00:00, 331.46it/s]
68%|██████▊ | Permuting : 67/99 [00:00<00:00, 330.30it/s]
79%|███████▉ | Permuting : 78/99 [00:00<00:00, 329.55it/s]
90%|████████▉ | Permuting : 89/99 [00:00<00:00, 328.96it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 328.85it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 328.46it/s]
Step-down-in-jumps iteration #2 found 0 additional clusters to exclude from subsequent iterations
No baseline correction applied
Using a threshold of 1.724718
stat_fun(H1): min=-4.528367 max=3.706422
Running initial clustering …
Found 88 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
10%|█ | Permuting : 10/99 [00:00<00:00, 295.10it/s]
21%|██ | Permuting : 21/99 [00:00<00:00, 310.22it/s]
32%|███▏ | Permuting : 32/99 [00:00<00:00, 315.75it/s]
43%|████▎ | Permuting : 43/99 [00:00<00:00, 318.46it/s]
55%|█████▍ | Permuting : 54/99 [00:00<00:00, 320.09it/s]
65%|██████▍ | Permuting : 64/99 [00:00<00:00, 315.61it/s]
76%|███████▌ | Permuting : 75/99 [00:00<00:00, 317.33it/s]
86%|████████▌ | Permuting : 85/99 [00:00<00:00, 314.23it/s]
97%|█████████▋| Permuting : 96/99 [00:00<00:00, 315.69it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 314.16it/s]
Step-down-in-jumps iteration #1 found 1 cluster to exclude from subsequent iterations
0%| | Permuting : 0/99 [00:00<?, ?it/s]
10%|█ | Permuting : 10/99 [00:00<00:00, 295.18it/s]
22%|██▏ | Permuting : 22/99 [00:00<00:00, 326.03it/s]
33%|███▎ | Permuting : 33/99 [00:00<00:00, 325.89it/s]
45%|████▌ | Permuting : 45/99 [00:00<00:00, 333.71it/s]
58%|█████▊ | Permuting : 57/99 [00:00<00:00, 338.37it/s]
69%|██████▊ | Permuting : 68/99 [00:00<00:00, 335.82it/s]
80%|███████▉ | Permuting : 79/99 [00:00<00:00, 334.13it/s]
92%|█████████▏| Permuting : 91/99 [00:00<00:00, 337.27it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 337.02it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 335.70it/s]
Step-down-in-jumps iteration #2 found 0 additional clusters to exclude from subsequent iterations
Using a threshold of -1.724718
stat_fun(H1): min=-4.528367 max=3.706422
Running initial clustering …
Found 58 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
11%|█ | Permuting : 11/99 [00:00<00:00, 324.75it/s]
21%|██ | Permuting : 21/99 [00:00<00:00, 309.46it/s]
32%|███▏ | Permuting : 32/99 [00:00<00:00, 315.09it/s]
42%|████▏ | Permuting : 42/99 [00:00<00:00, 309.96it/s]
53%|█████▎ | Permuting : 52/99 [00:00<00:00, 306.62it/s]
64%|██████▎ | Permuting : 63/99 [00:00<00:00, 310.07it/s]
75%|███████▍ | Permuting : 74/99 [00:00<00:00, 312.52it/s]
86%|████████▌ | Permuting : 85/99 [00:00<00:00, 314.38it/s]
96%|█████████▌| Permuting : 95/99 [00:00<00:00, 311.77it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 314.29it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
No baseline correction applied
Using a threshold of 1.724718
stat_fun(H1): min=-6.581589 max=3.346448
Running initial clustering …
Found 67 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
8%|▊ | Permuting : 8/99 [00:00<00:00, 235.96it/s]
19%|█▉ | Permuting : 19/99 [00:00<00:00, 281.28it/s]
25%|██▌ | Permuting : 25/99 [00:00<00:00, 244.75it/s]
35%|███▌ | Permuting : 35/99 [00:00<00:00, 258.52it/s]
44%|████▍ | Permuting : 44/99 [00:00<00:00, 260.10it/s]
53%|█████▎ | Permuting : 52/99 [00:00<00:00, 255.75it/s]
61%|██████ | Permuting : 60/99 [00:00<00:00, 252.60it/s]
70%|██████▉ | Permuting : 69/99 [00:00<00:00, 254.63it/s]
80%|███████▉ | Permuting : 79/99 [00:00<00:00, 260.15it/s]
90%|████████▉ | Permuting : 89/99 [00:00<00:00, 264.55it/s]
99%|█████████▉| Permuting : 98/99 [00:00<00:00, 264.79it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 262.93it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
Using a threshold of -1.724718
stat_fun(H1): min=-6.581589 max=3.346448
Running initial clustering …
Found 69 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
9%|▉ | Permuting : 9/99 [00:00<00:00, 265.57it/s]
20%|██ | Permuting : 20/99 [00:00<00:00, 296.20it/s]
29%|██▉ | Permuting : 29/99 [00:00<00:00, 285.62it/s]
39%|███▉ | Permuting : 39/99 [00:00<00:00, 288.15it/s]
48%|████▊ | Permuting : 48/99 [00:00<00:00, 283.23it/s]
59%|█████▊ | Permuting : 58/99 [00:00<00:00, 285.61it/s]
69%|██████▊ | Permuting : 68/99 [00:00<00:00, 287.38it/s]
79%|███████▉ | Permuting : 78/99 [00:00<00:00, 288.70it/s]
89%|████████▉ | Permuting : 88/99 [00:00<00:00, 289.71it/s]
99%|█████████▉| Permuting : 98/99 [00:00<00:00, 290.55it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 290.75it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
No baseline correction applied
Using a threshold of 1.713872
stat_fun(H1): min=-3.754759 max=3.360704
Running initial clustering …
Found 71 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
9%|▉ | Permuting : 9/99 [00:00<00:00, 265.67it/s]
18%|█▊ | Permuting : 18/99 [00:00<00:00, 266.03it/s]
28%|██▊ | Permuting : 28/99 [00:00<00:00, 276.63it/s]
37%|███▋ | Permuting : 37/99 [00:00<00:00, 273.82it/s]
47%|████▋ | Permuting : 47/99 [00:00<00:00, 278.61it/s]
57%|█████▋ | Permuting : 56/99 [00:00<00:00, 276.33it/s]
64%|██████▎ | Permuting : 63/99 [00:00<00:00, 264.90it/s]
71%|███████ | Permuting : 70/99 [00:00<00:00, 256.33it/s]
80%|███████▉ | Permuting : 79/99 [00:00<00:00, 257.71it/s]
90%|████████▉ | Permuting : 89/99 [00:00<00:00, 262.51it/s]
99%|█████████▉| Permuting : 98/99 [00:00<00:00, 262.93it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 264.83it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
Using a threshold of -1.713872
stat_fun(H1): min=-3.754759 max=3.360704
Running initial clustering …
Found 80 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
8%|▊ | Permuting : 8/99 [00:00<00:00, 235.75it/s]
18%|█▊ | Permuting : 18/99 [00:00<00:00, 266.49it/s]
28%|██▊ | Permuting : 28/99 [00:00<00:00, 276.85it/s]
38%|███▊ | Permuting : 38/99 [00:00<00:00, 281.94it/s]
48%|████▊ | Permuting : 48/99 [00:00<00:00, 285.10it/s]
58%|█████▊ | Permuting : 57/99 [00:00<00:00, 281.45it/s]
68%|██████▊ | Permuting : 67/99 [00:00<00:00, 283.84it/s]
78%|███████▊ | Permuting : 77/99 [00:00<00:00, 285.67it/s]
88%|████████▊ | Permuting : 87/99 [00:00<00:00, 287.03it/s]
98%|█████████▊| Permuting : 97/99 [00:00<00:00, 288.12it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 285.30it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
No baseline correction applied
Using a threshold of 1.713872
stat_fun(H1): min=-4.992503 max=5.416450
Running initial clustering …
Found 103 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
10%|█ | Permuting : 10/99 [00:00<00:00, 295.52it/s]
20%|██ | Permuting : 20/99 [00:00<00:00, 295.29it/s]
30%|███ | Permuting : 30/99 [00:00<00:00, 295.65it/s]
40%|████ | Permuting : 40/99 [00:00<00:00, 295.57it/s]
51%|█████ | Permuting : 50/99 [00:00<00:00, 295.63it/s]
60%|█████▉ | Permuting : 59/99 [00:00<00:00, 290.09it/s]
70%|██████▉ | Permuting : 69/99 [00:00<00:00, 291.05it/s]
80%|███████▉ | Permuting : 79/99 [00:00<00:00, 291.79it/s]
90%|████████▉ | Permuting : 89/99 [00:00<00:00, 292.41it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 292.93it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 292.54it/s]
Step-down-in-jumps iteration #1 found 1 cluster to exclude from subsequent iterations
0%| | Permuting : 0/99 [00:00<?, ?it/s]
9%|▉ | Permuting : 9/99 [00:00<00:00, 265.59it/s]
20%|██ | Permuting : 20/99 [00:00<00:00, 296.19it/s]
31%|███▏ | Permuting : 31/99 [00:00<00:00, 306.60it/s]
43%|████▎ | Permuting : 43/99 [00:00<00:00, 319.80it/s]
55%|█████▍ | Permuting : 54/99 [00:00<00:00, 321.01it/s]
67%|██████▋ | Permuting : 66/99 [00:00<00:00, 327.48it/s]
79%|███████▉ | Permuting : 78/99 [00:00<00:00, 332.05it/s]
90%|████████▉ | Permuting : 89/99 [00:00<00:00, 331.06it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 330.28it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 328.25it/s]
Step-down-in-jumps iteration #2 found 0 additional clusters to exclude from subsequent iterations
Using a threshold of -1.713872
stat_fun(H1): min=-4.992503 max=5.416450
Running initial clustering …
Found 67 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
9%|▉ | Permuting : 9/99 [00:00<00:00, 265.17it/s]
19%|█▉ | Permuting : 19/99 [00:00<00:00, 279.41it/s]
31%|███▏ | Permuting : 31/99 [00:00<00:00, 305.80it/s]
41%|████▏ | Permuting : 41/99 [00:00<00:00, 303.17it/s]
53%|█████▎ | Permuting : 52/99 [00:00<00:00, 308.17it/s]
63%|██████▎ | Permuting : 62/99 [00:00<00:00, 305.66it/s]
73%|███████▎ | Permuting : 72/99 [00:00<00:00, 303.91it/s]
83%|████████▎ | Permuting : 82/99 [00:00<00:00, 302.78it/s]
93%|█████████▎| Permuting : 92/99 [00:00<00:00, 301.87it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 301.23it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 300.89it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
No baseline correction applied
Using a threshold of 1.713872
stat_fun(H1): min=-6.044340 max=4.070444
Running initial clustering …
Found 92 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
7%|▋ | Permuting : 7/99 [00:00<00:00, 206.01it/s]
15%|█▌ | Permuting : 15/99 [00:00<00:00, 221.68it/s]
25%|██▌ | Permuting : 25/99 [00:00<00:00, 247.49it/s]
35%|███▌ | Permuting : 35/99 [00:00<00:00, 260.33it/s]
43%|████▎ | Permuting : 43/99 [00:00<00:00, 255.16it/s]
55%|█████▍ | Permuting : 54/99 [00:00<00:00, 268.33it/s]
65%|██████▍ | Permuting : 64/99 [00:00<00:00, 272.97it/s]
74%|███████▎ | Permuting : 73/99 [00:00<00:00, 272.03it/s]
83%|████████▎ | Permuting : 82/99 [00:00<00:00, 271.21it/s]
92%|█████████▏| Permuting : 91/99 [00:00<00:00, 270.49it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 274.39it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 271.67it/s]
Step-down-in-jumps iteration #1 found 1 cluster to exclude from subsequent iterations
0%| | Permuting : 0/99 [00:00<?, ?it/s]
8%|▊ | Permuting : 8/99 [00:00<00:00, 234.77it/s]
17%|█▋ | Permuting : 17/99 [00:00<00:00, 250.72it/s]
26%|██▋ | Permuting : 26/99 [00:00<00:00, 256.16it/s]
37%|███▋ | Permuting : 37/99 [00:00<00:00, 274.82it/s]
45%|████▌ | Permuting : 45/99 [00:00<00:00, 266.33it/s]
56%|█████▌ | Permuting : 55/99 [00:00<00:00, 271.73it/s]
67%|██████▋ | Permuting : 66/99 [00:00<00:00, 280.63it/s]
77%|███████▋ | Permuting : 76/99 [00:00<00:00, 282.91it/s]
86%|████████▌ | Permuting : 85/99 [00:00<00:00, 280.56it/s]
94%|█████████▍| Permuting : 93/99 [00:00<00:00, 275.05it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 276.76it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 275.58it/s]
Step-down-in-jumps iteration #2 found 0 additional clusters to exclude from subsequent iterations
Using a threshold of -1.713872
stat_fun(H1): min=-6.044340 max=4.070444
Running initial clustering …
Found 51 clusters
0%| | Permuting : 0/99 [00:00<?, ?it/s]
10%|█ | Permuting : 10/99 [00:00<00:00, 295.53it/s]
21%|██ | Permuting : 21/99 [00:00<00:00, 310.82it/s]
32%|███▏ | Permuting : 32/99 [00:00<00:00, 315.74it/s]
43%|████▎ | Permuting : 43/99 [00:00<00:00, 318.46it/s]
55%|█████▍ | Permuting : 54/99 [00:00<00:00, 320.06it/s]
66%|██████▌ | Permuting : 65/99 [00:00<00:00, 321.18it/s]
77%|███████▋ | Permuting : 76/99 [00:00<00:00, 321.88it/s]
89%|████████▉ | Permuting : 88/99 [00:00<00:00, 326.74it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 328.14it/s]
100%|██████████| Permuting : 99/99 [00:00<00:00, 326.22it/s]
Step-down-in-jumps iteration #1 found 0 clusters to exclude from subsequent iterations
No baseline correction applied
Similar to Epochs objects, we can also export data from
EpochsTFR and AverageTFR objects
to a Pandas DataFrame. By default, the time
column of the exported data frame is in milliseconds. Here, to be consistent
with the time-frequency plots, we want to keep it in seconds, which we can
achieve by setting time_format=None:
df = tfr.to_data_frame(time_format=None)
df.head()
This allows us to use additional plotting functions like
seaborn.lineplot() to plot confidence bands:
df = tfr.to_data_frame(time_format=None, long_format=True)
# Map to frequency bands:
freq_bounds = {"_": 0, "delta": 3, "theta": 7, "alpha": 13, "beta": 35, "gamma": 140}
df["band"] = pd.cut(
df["freq"], list(freq_bounds.values()), labels=list(freq_bounds)[1:]
)
# Filter to retain only relevant frequency bands:
freq_bands_of_interest = ["delta", "theta", "alpha", "beta"]
df = df[df.band.isin(freq_bands_of_interest)]
df["band"] = df["band"].cat.remove_unused_categories()
# Order channels for plotting:
df["channel"] = df["channel"].cat.reorder_categories(("C3", "Cz", "C4"), ordered=True)
g = sns.FacetGrid(df, row="band", col="channel", margin_titles=True)
g.map(sns.lineplot, "time", "value", "condition", n_boot=10)
axline_kw = dict(color="black", linestyle="dashed", linewidth=0.5, alpha=0.5)
g.map(plt.axhline, y=0, **axline_kw)
g.map(plt.axvline, x=0, **axline_kw)
g.set(ylim=(None, 1.5))
g.set_axis_labels("Time (s)", "ERDS")
g.set_titles(col_template="{col_name}", row_template="{row_name}")
g.add_legend(ncol=2, loc="lower center")
g.fig.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.08)
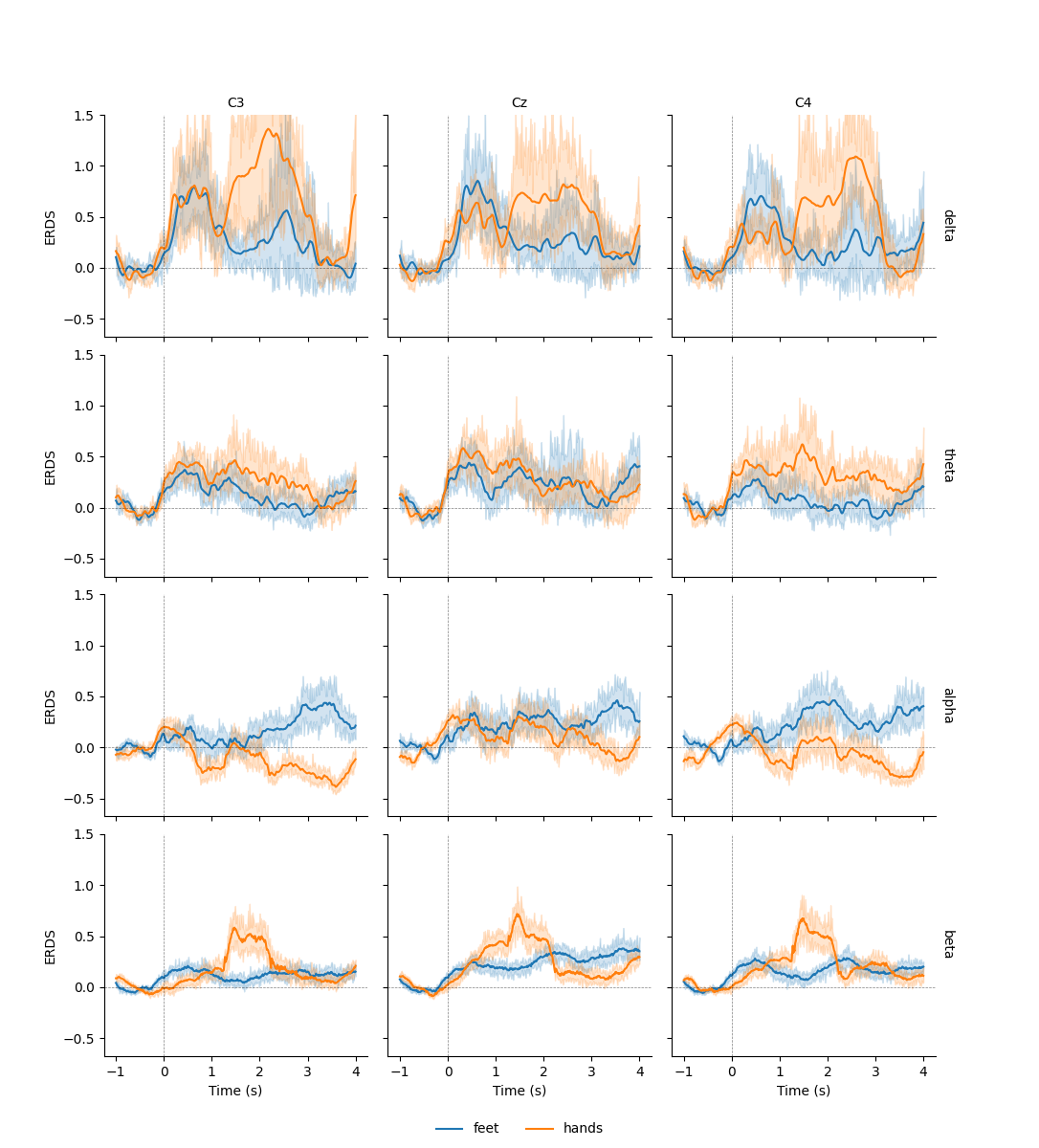
Converting "condition" to "category"...
Converting "epoch" to "category"...
Converting "channel" to "category"...
Converting "ch_type" to "category"...
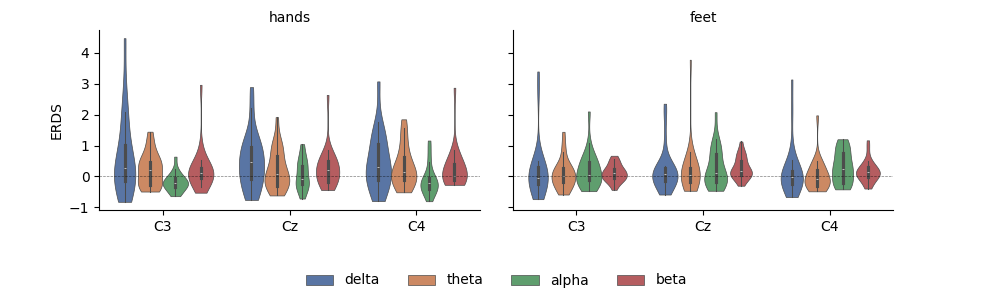
Having the data as a DataFrame also facilitates subsetting, grouping, and other transforms. Here, we use seaborn to plot the average ERDS in the motor imagery interval as a function of frequency band and imagery condition:
df_mean = (
df.query("time > 1")
.groupby(["condition", "epoch", "band", "channel"], observed=False)[["value"]]
.mean()
.reset_index()
)
g = sns.FacetGrid(
df_mean, col="condition", col_order=["hands", "feet"], margin_titles=True
)
g = g.map(
sns.violinplot,
"channel",
"value",
"band",
cut=0,
palette="deep",
order=["C3", "Cz", "C4"],
hue_order=freq_bands_of_interest,
linewidth=0.5,
).add_legend(ncol=4, loc="lower center")
g.map(plt.axhline, **axline_kw)
g.set_axis_labels("", "ERDS")
g.set_titles(col_template="{col_name}", row_template="{row_name}")
g.fig.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.3)
References#
Total running time of the script: (0 minutes 34.571 seconds)
Estimated memory usage: 158 MB