mne.decoding.SlidingEstimator#
- class mne.decoding.SlidingEstimator(base_estimator, scoring=None, n_jobs=None, *, verbose=None)[source]#
Search Light.
Fit, predict and score a series of models to each subset of the dataset along the last dimension. Each entry in the last dimension is referred to as a task.
- Parameters:
- base_estimatorobject
The base estimator to iteratively fit on a subset of the dataset.
- scoring
callable()|str|None Score function (or loss function) with signature
score_func(y, y_pred, **kwargs). Note that the “predict” method is automatically identified if scoring is a string (e.g.scoring='roc_auc'callspredict_proba), but is not automatically set ifscoringis a callable (e.g.scoring=sklearn.metrics.roc_auc_score).- n_jobs
int|None The number of jobs to run in parallel. If
-1, it is set to the number of CPU cores. Requires thejoblibpackage.None(default) is a marker for ‘unset’ that will be interpreted asn_jobs=1(sequential execution) unless the call is performed under ajoblib.parallel_backend()context manager that sets another value forn_jobs.- verbose
bool|str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- Attributes:
- estimators_array_like, shape (n_tasks,)
List of fitted scikit-learn estimators (one per task).
Methods
Estimate distances of each data slice to the hyperplanes.
fit(X, y, **fit_params)Fit a series of independent estimators to the dataset.
fit_transform(X, y, **fit_params)Fit and transform a series of independent estimators to the dataset.
get_params([deep])Get parameters for this estimator.
predict(X)Predict each data slice/task with a series of independent estimators.
Predict each data slice with a series of independent estimators.
score(X, y)Score each estimator on each task.
set_params(**params)Set the parameters of this estimator.
transform(X)Transform each data slice/task with a series of independent estimators.
- decision_function(X)[source]#
Estimate distances of each data slice to the hyperplanes.
- Parameters:
- X
array, shape (n_samples, nd_features, n_tasks) The input samples. For each data slice, the corresponding estimator outputs the distance to the hyperplane, e.g.:
[estimators[ii].decision_function(X[..., ii]) for ii in range(n_estimators)]. The feature dimension can be multidimensional e.g. X.shape = (n_samples, n_features_1, n_features_2, n_estimators).
- X
- Returns:
- y_pred
array, shape (n_samples, n_estimators, n_classes * (n_classes-1) // 2) Predicted distances for each estimator/data slice.
- y_pred
Notes
This requires base_estimator to have a
decision_functionmethod.
- fit(X, y, **fit_params)[source]#
Fit a series of independent estimators to the dataset.
- Parameters:
- X
array, shape (n_samples, nd_features, n_tasks) The training input samples. For each data slice, a clone estimator is fitted independently. The feature dimension can be multidimensional e.g. X.shape = (n_samples, n_features_1, n_features_2, n_tasks).
- y
array, shape (n_samples,) | (n_samples, n_targets) The target values.
- **fit_params
dictofstr-> object Parameters to pass to the fit method of the estimator.
- X
- Returns:
- selfobject
Return self.
Examples using
fit:
Decoding sensor space data with generalization across time and conditions
Decoding sensor space data with generalization across time and conditions
- fit_transform(X, y, **fit_params)[source]#
Fit and transform a series of independent estimators to the dataset.
- Parameters:
- X
array, shape (n_samples, nd_features, n_tasks) The training input samples. For each task, a clone estimator is fitted independently. The feature dimension can be multidimensional, e.g.:
X.shape = (n_samples, n_features_1, n_features_2, n_estimators)
- y
array, shape (n_samples,) | (n_samples, n_targets) The target values.
- **fit_params
dictofstr-> object Parameters to pass to the fit method of the estimator.
- X
- Returns:
- y_pred
array, shape (n_samples, n_tasks) | (n_samples, n_tasks, n_targets) The predicted values for each estimator.
- y_pred
- predict(X)[source]#
Predict each data slice/task with a series of independent estimators.
The number of tasks in X should match the number of tasks/estimators given at fit time.
- Parameters:
- X
array, shape (n_samples, nd_features, n_tasks) The input samples. For each data slice, the corresponding estimator makes the sample predictions, e.g.:
[estimators[ii].predict(X[..., ii]) for ii in range(n_estimators)]. The feature dimension can be multidimensional e.g. X.shape = (n_samples, n_features_1, n_features_2, n_tasks).
- X
- Returns:
- y_pred
array, shape (n_samples, n_estimators) | (n_samples, n_tasks, n_targets) Predicted values for each estimator/data slice.
- y_pred
- predict_proba(X)[source]#
Predict each data slice with a series of independent estimators.
The number of tasks in X should match the number of tasks/estimators given at fit time.
- Parameters:
- X
array, shape (n_samples, nd_features, n_tasks) The input samples. For each data slice, the corresponding estimator makes the sample probabilistic predictions, e.g.:
[estimators[ii].predict_proba(X[..., ii]) for ii in range(n_estimators)]. The feature dimension can be multidimensional e.g. X.shape = (n_samples, n_features_1, n_features_2, n_tasks).
- X
- Returns:
- y_pred
array, shape (n_samples, n_tasks, n_classes) Predicted probabilities for each estimator/data slice/task.
- y_pred
- score(X, y)[source]#
Score each estimator on each task.
The number of tasks in X should match the number of tasks/estimators given at fit time, i.e. we need
X.shape[-1] == len(self.estimators_).- Parameters:
- X
array, shape (n_samples, nd_features, n_tasks) The input samples. For each data slice, the corresponding estimator scores the prediction, e.g.:
[estimators[ii].score(X[..., ii], y) for ii in range(n_estimators)]. The feature dimension can be multidimensional e.g. X.shape = (n_samples, n_features_1, n_features_2, n_tasks).- y
array, shape (n_samples,) | (n_samples, n_targets) The target values.
- X
- Returns:
- score
array, shape (n_samples, n_estimators) Score for each estimator/task.
- score
Examples using
score:
Decoding sensor space data with generalization across time and conditions
Decoding sensor space data with generalization across time and conditions
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **params
dict Parameters.
- **params
- Returns:
- instinstance
The object.
- transform(X)[source]#
Transform each data slice/task with a series of independent estimators.
The number of tasks in X should match the number of tasks/estimators given at fit time.
- Parameters:
- X
array, shape (n_samples, nd_features, n_tasks) The input samples. For each data slice/task, the corresponding estimator makes a transformation of the data, e.g.
[estimators[ii].transform(X[..., ii]) for ii in range(n_estimators)]. The feature dimension can be multidimensional e.g. X.shape = (n_samples, n_features_1, n_features_2, n_tasks).
- X
- Returns:
- Xt
array, shape (n_samples, n_estimators) The transformed values generated by each estimator.
- Xt
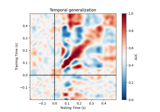
Examples using mne.decoding.SlidingEstimator#
Decoding sensor space data with generalization across time and conditions