Note
Go to the end to download the full example code
Spectro-temporal receptive field (STRF) estimation on continuous data#
This demonstrates how an encoding model can be fit with multiple continuous inputs. In this case, we simulate the model behind a spectro-temporal receptive field (or STRF). First, we create a linear filter that maps patterns in spectro-temporal space onto an output, representing neural activity. We fit a receptive field model that attempts to recover the original linear filter that was used to create this data.
# Authors: Chris Holdgraf <choldgraf@gmail.com>
# Eric Larson <larson.eric.d@gmail.com>
#
# License: BSD-3-Clause
import numpy as np
import matplotlib.pyplot as plt
import mne
from mne.decoding import ReceptiveField, TimeDelayingRidge
from scipy.stats import multivariate_normal
from scipy.io import loadmat
from sklearn.preprocessing import scale
rng = np.random.RandomState(1337) # To make this example reproducible
Load audio data#
We’ll read in the audio data from [1] in order to simulate a response.
In addition, we’ll downsample the data along the time dimension in order to speed up computation. Note that depending on the input values, this may not be desired. For example if your input stimulus varies more quickly than 1/2 the sampling rate to which we are downsampling.
# Read in audio that's been recorded in epochs.
path_audio = mne.datasets.mtrf.data_path()
data = loadmat(str(path_audio / "speech_data.mat"))
audio = data["spectrogram"].T
sfreq = float(data["Fs"][0, 0])
n_decim = 2
audio = mne.filter.resample(audio, down=n_decim, npad="auto")
sfreq /= n_decim
Create a receptive field#
We’ll simulate a linear receptive field for a theoretical neural signal. This defines how the signal will respond to power in this receptive field space.
n_freqs = 20
tmin, tmax = -0.1, 0.4
# To simulate the data we'll create explicit delays here
delays_samp = np.arange(np.round(tmin * sfreq), np.round(tmax * sfreq) + 1).astype(int)
delays_sec = delays_samp / sfreq
freqs = np.linspace(50, 5000, n_freqs)
grid = np.array(np.meshgrid(delays_sec, freqs))
# We need data to be shaped as n_epochs, n_features, n_times, so swap axes here
grid = grid.swapaxes(0, -1).swapaxes(0, 1)
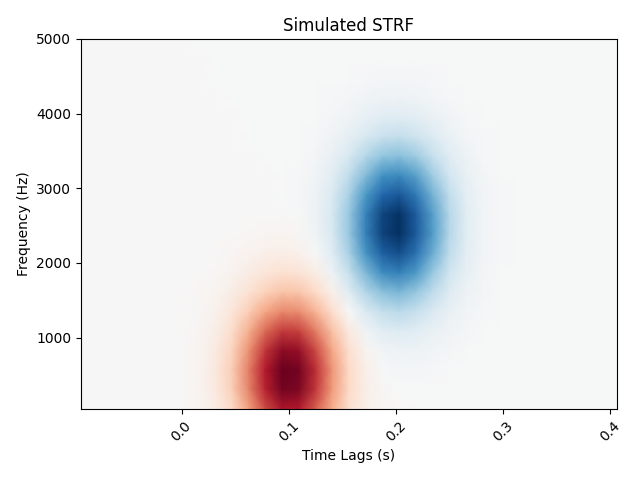
# Simulate a temporal receptive field with a Gabor filter
means_high = [0.1, 500]
means_low = [0.2, 2500]
cov = [[0.001, 0], [0, 500000]]
gauss_high = multivariate_normal.pdf(grid, means_high, cov)
gauss_low = -1 * multivariate_normal.pdf(grid, means_low, cov)
weights = gauss_high + gauss_low # Combine to create the "true" STRF
kwargs = dict(
vmax=np.abs(weights).max(),
vmin=-np.abs(weights).max(),
cmap="RdBu_r",
shading="gouraud",
)
fig, ax = plt.subplots()
ax.pcolormesh(delays_sec, freqs, weights, **kwargs)
ax.set(title="Simulated STRF", xlabel="Time Lags (s)", ylabel="Frequency (Hz)")
plt.setp(ax.get_xticklabels(), rotation=45)
plt.autoscale(tight=True)
mne.viz.tight_layout()
Simulate a neural response#
Using this receptive field, we’ll create an artificial neural response to a stimulus.
To do this, we’ll create a time-delayed version of the receptive field, and then calculate the dot product between this and the stimulus. Note that this is effectively doing a convolution between the stimulus and the receptive field. See here for more information.
# Reshape audio to split into epochs, then make epochs the first dimension.
n_epochs, n_seconds = 16, 5
audio = audio[:, : int(n_seconds * sfreq * n_epochs)]
X = audio.reshape([n_freqs, n_epochs, -1]).swapaxes(0, 1)
n_times = X.shape[-1]
# Delay the spectrogram according to delays so it can be combined w/ the STRF
# Lags will now be in axis 1, then we reshape to vectorize
delays = np.arange(np.round(tmin * sfreq), np.round(tmax * sfreq) + 1).astype(int)
# Iterate through indices and append
X_del = np.zeros((len(delays),) + X.shape)
for ii, ix_delay in enumerate(delays):
# These arrays will take/put particular indices in the data
take = [slice(None)] * X.ndim
put = [slice(None)] * X.ndim
if ix_delay > 0:
take[-1] = slice(None, -ix_delay)
put[-1] = slice(ix_delay, None)
elif ix_delay < 0:
take[-1] = slice(-ix_delay, None)
put[-1] = slice(None, ix_delay)
X_del[ii][tuple(put)] = X[tuple(take)]
# Now set the delayed axis to the 2nd dimension
X_del = np.rollaxis(X_del, 0, 3)
X_del = X_del.reshape([n_epochs, -1, n_times])
n_features = X_del.shape[1]
weights_sim = weights.ravel()
# Simulate a neural response to the sound, given this STRF
y = np.zeros((n_epochs, n_times))
for ii, iep in enumerate(X_del):
# Simulate this epoch and add random noise
noise_amp = 0.002
y[ii] = np.dot(weights_sim, iep) + noise_amp * rng.randn(n_times)
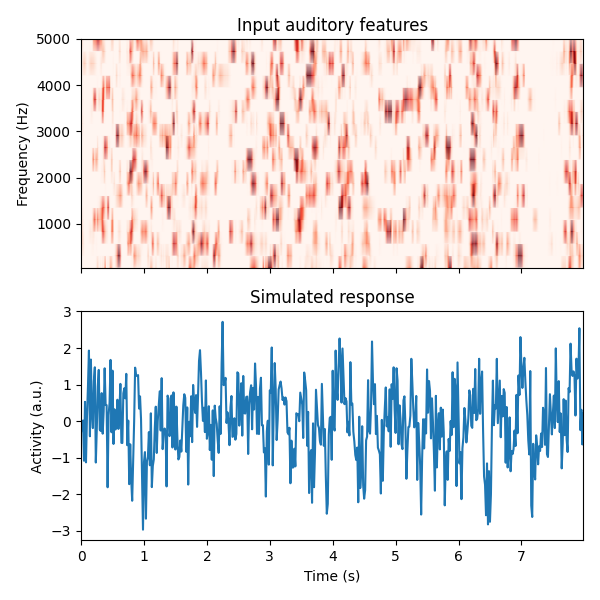
# Plot the first 2 trials of audio and the simulated electrode activity
X_plt = scale(np.hstack(X[:2]).T).T
y_plt = scale(np.hstack(y[:2]))
time = np.arange(X_plt.shape[-1]) / sfreq
_, (ax1, ax2) = plt.subplots(2, 1, figsize=(6, 6), sharex=True)
ax1.pcolormesh(time, freqs, X_plt, vmin=0, vmax=4, cmap="Reds", shading="gouraud")
ax1.set_title("Input auditory features")
ax1.set(ylim=[freqs.min(), freqs.max()], ylabel="Frequency (Hz)")
ax2.plot(time, y_plt)
ax2.set(
xlim=[time.min(), time.max()],
title="Simulated response",
xlabel="Time (s)",
ylabel="Activity (a.u.)",
)
mne.viz.tight_layout()
Fit a model to recover this receptive field#
Finally, we’ll use the mne.decoding.ReceptiveField class to recover
the linear receptive field of this signal. Note that properties of the
receptive field (e.g. smoothness) will depend on the autocorrelation in the
inputs and outputs.
# Create training and testing data
train, test = np.arange(n_epochs - 1), n_epochs - 1
X_train, X_test, y_train, y_test = X[train], X[test], y[train], y[test]
X_train, X_test, y_train, y_test = [
np.rollaxis(ii, -1, 0) for ii in (X_train, X_test, y_train, y_test)
]
# Model the simulated data as a function of the spectrogram input
alphas = np.logspace(-3, 3, 7)
scores = np.zeros_like(alphas)
models = []
for ii, alpha in enumerate(alphas):
rf = ReceptiveField(tmin, tmax, sfreq, freqs, estimator=alpha)
rf.fit(X_train, y_train)
# Now make predictions about the model output, given input stimuli.
scores[ii] = rf.score(X_test, y_test)
models.append(rf)
times = rf.delays_ / float(rf.sfreq)
# Choose the model that performed best on the held out data
ix_best_alpha = np.argmax(scores)
best_mod = models[ix_best_alpha]
coefs = best_mod.coef_[0]
best_pred = best_mod.predict(X_test)[:, 0]
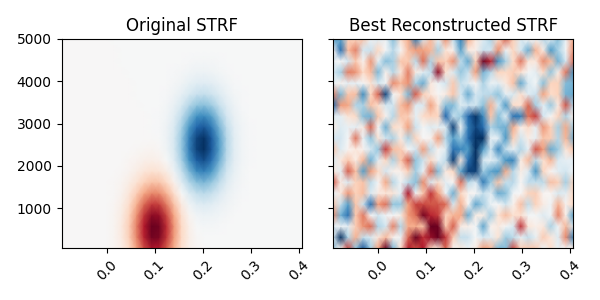
# Plot the original STRF, and the one that we recovered with modeling.
_, (ax1, ax2) = plt.subplots(1, 2, figsize=(6, 3), sharey=True, sharex=True)
ax1.pcolormesh(delays_sec, freqs, weights, **kwargs)
ax2.pcolormesh(times, rf.feature_names, coefs, **kwargs)
ax1.set_title("Original STRF")
ax2.set_title("Best Reconstructed STRF")
plt.setp([iax.get_xticklabels() for iax in [ax1, ax2]], rotation=45)
plt.autoscale(tight=True)
mne.viz.tight_layout()
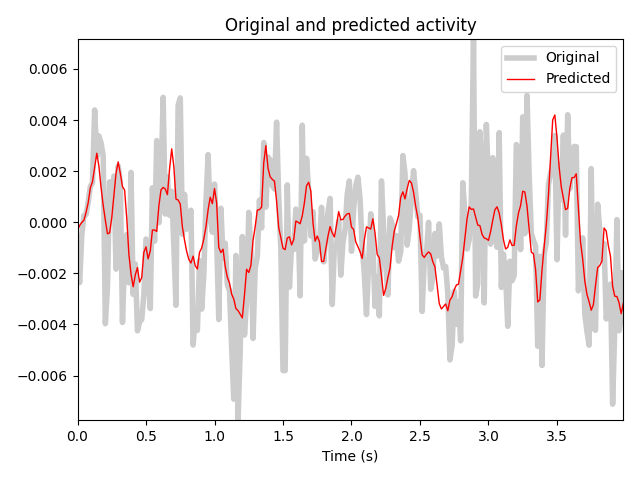
# Plot the actual response and the predicted response on a held out stimulus
time_pred = np.arange(best_pred.shape[0]) / sfreq
fig, ax = plt.subplots()
ax.plot(time_pred, y_test, color="k", alpha=0.2, lw=4)
ax.plot(time_pred, best_pred, color="r", lw=1)
ax.set(title="Original and predicted activity", xlabel="Time (s)")
ax.legend(["Original", "Predicted"])
plt.autoscale(tight=True)
mne.viz.tight_layout()
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
0%| | Sample : 1/3450 [00:08<8:08:32, 8.50s/it]
5%|5 | Sample : 174/3450 [00:08<02:32, 21.50it/s]
10%|# | Sample : 361/3450 [00:08<01:07, 45.74it/s]
16%|#5 | Sample : 535/3450 [00:08<00:42, 69.37it/s]
21%|##1 | Sample : 726/3450 [00:08<00:28, 96.56it/s]
26%|##6 | Sample : 909/3450 [00:08<00:20, 123.85it/s]
32%|###1 | Sample : 1088/3450 [00:08<00:15, 151.81it/s]
37%|###6 | Sample : 1267/3450 [00:08<00:12, 181.08it/s]
42%|####1 | Sample : 1445/3450 [00:08<00:09, 211.55it/s]
47%|####6 | Sample : 1621/3450 [00:08<00:07, 243.07it/s]
52%|#####1 | Sample : 1791/3450 [00:08<00:06, 274.91it/s]
57%|#####7 | Sample : 1979/3450 [00:08<00:04, 311.82it/s]
62%|######2 | Sample : 2153/3450 [00:08<00:03, 347.48it/s]
68%|######7 | Sample : 2330/3450 [00:08<00:02, 385.41it/s]
73%|#######3 | Sample : 2521/3450 [00:08<00:02, 428.30it/s]
78%|#######8 | Sample : 2693/3450 [00:08<00:01, 468.48it/s]
83%|########3 | Sample : 2874/3450 [00:08<00:01, 512.73it/s]
88%|########8 | Sample : 3047/3450 [00:08<00:00, 556.78it/s]
94%|#########3| Sample : 3232/3450 [00:08<00:00, 606.11it/s]
99%|#########8| Sample : 3413/3450 [00:08<00:00, 656.39it/s]
100%|##########| Sample : 3450/3450 [00:08<00:00, 391.72it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
5%|5 | Sample : 179/3450 [00:00<00:00, 11141.49it/s]
10%|# | Sample : 354/3450 [00:00<00:00, 11035.65it/s]
16%|#5 | Sample : 542/3450 [00:00<00:00, 11278.96it/s]
21%|## | Sample : 713/3450 [00:00<00:00, 11107.73it/s]
27%|##6 | Sample : 916/3450 [00:00<00:00, 11446.30it/s]
32%|###1 | Sample : 1094/3450 [00:00<00:00, 11385.64it/s]
37%|###6 | Sample : 1272/3450 [00:00<00:00, 11336.79it/s]
42%|####2 | Sample : 1450/3450 [00:00<00:00, 11298.70it/s]
47%|####7 | Sample : 1629/3450 [00:00<00:00, 11280.59it/s]
52%|#####2 | Sample : 1805/3450 [00:00<00:00, 11245.64it/s]
57%|#####7 | Sample : 1976/3450 [00:00<00:00, 11181.03it/s]
62%|######2 | Sample : 2143/3450 [00:00<00:00, 11098.62it/s]
67%|######7 | Sample : 2314/3450 [00:00<00:00, 11051.09it/s]
72%|#######1 | Sample : 2483/3450 [00:00<00:00, 11002.42it/s]
77%|#######7 | Sample : 2659/3450 [00:00<00:00, 10999.11it/s]
83%|########2 | Sample : 2848/3450 [00:00<00:00, 11067.87it/s]
88%|########7 | Sample : 3030/3450 [00:00<00:00, 11093.45it/s]
93%|#########3| Sample : 3216/3450 [00:00<00:00, 11134.71it/s]
98%|#########8| Sample : 3388/3450 [00:00<00:00, 11100.10it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 11140.69it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
5%|5 | Sample : 187/3450 [00:00<00:00, 11673.39it/s]
11%|# | Sample : 376/3450 [00:00<00:00, 11730.79it/s]
16%|#6 | Sample : 560/3450 [00:00<00:00, 11644.13it/s]
21%|##1 | Sample : 738/3450 [00:00<00:00, 11489.84it/s]
27%|##6 | Sample : 921/3450 [00:00<00:00, 11437.91it/s]
32%|###1 | Sample : 1100/3450 [00:00<00:00, 11389.67it/s]
37%|###7 | Sample : 1285/3450 [00:00<00:00, 11416.38it/s]
43%|####3 | Sample : 1486/3450 [00:00<00:00, 11582.64it/s]
48%|####8 | Sample : 1665/3450 [00:00<00:00, 11526.85it/s]
54%|#####4 | Sample : 1866/3450 [00:00<00:00, 11649.45it/s]
59%|#####9 | Sample : 2049/3450 [00:00<00:00, 11618.76it/s]
65%|######5 | Sample : 2244/3450 [00:00<00:00, 11679.34it/s]
70%|####### | Sample : 2424/3450 [00:00<00:00, 11633.37it/s]
76%|#######5 | Sample : 2611/3450 [00:00<00:00, 11635.59it/s]
81%|########1 | Sample : 2807/3450 [00:00<00:00, 11689.03it/s]
87%|########6 | Sample : 2986/3450 [00:00<00:00, 11641.80it/s]
92%|#########1| Sample : 3173/3450 [00:00<00:00, 11644.36it/s]
98%|#########8| Sample : 3389/3450 [00:00<00:00, 11793.99it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 11767.40it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
6%|6 | Sample : 219/3450 [00:00<00:00, 13680.74it/s]
13%|#2 | Sample : 435/3450 [00:00<00:00, 13571.99it/s]
19%|#8 | Sample : 650/3450 [00:00<00:00, 13517.40it/s]
25%|##5 | Sample : 868/3450 [00:00<00:00, 13538.65it/s]
32%|###1 | Sample : 1087/3450 [00:00<00:00, 13568.33it/s]
38%|###7 | Sample : 1307/3450 [00:00<00:00, 13595.70it/s]
44%|####4 | Sample : 1529/3450 [00:00<00:00, 13634.39it/s]
51%|##### | Sample : 1750/3450 [00:00<00:00, 13659.83it/s]
57%|#####7 | Sample : 1967/3450 [00:00<00:00, 13642.21it/s]
63%|######3 | Sample : 2186/3450 [00:00<00:00, 13639.98it/s]
70%|######9 | Sample : 2404/3450 [00:00<00:00, 13635.07it/s]
76%|#######5 | Sample : 2619/3450 [00:00<00:00, 13609.54it/s]
82%|########2 | Sample : 2840/3450 [00:00<00:00, 13629.56it/s]
89%|########8 | Sample : 3061/3450 [00:00<00:00, 13643.20it/s]
95%|#########5| Sample : 3281/3450 [00:00<00:00, 13650.72it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 13636.05it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
6%|6 | Sample : 219/3450 [00:00<00:00, 13639.91it/s]
13%|#2 | Sample : 438/3450 [00:00<00:00, 13662.49it/s]
19%|#8 | Sample : 654/3450 [00:00<00:00, 13604.66it/s]
25%|##5 | Sample : 871/3450 [00:00<00:00, 13583.98it/s]
32%|###1 | Sample : 1090/3450 [00:00<00:00, 13601.86it/s]
38%|###8 | Sample : 1311/3450 [00:00<00:00, 13636.12it/s]
44%|####4 | Sample : 1531/3450 [00:00<00:00, 13649.00it/s]
51%|##### | Sample : 1749/3450 [00:00<00:00, 13639.20it/s]
58%|#####7 | Sample : 1993/3450 [00:00<00:00, 13854.52it/s]
64%|######4 | Sample : 2224/3450 [00:00<00:00, 13924.22it/s]
71%|####### | Sample : 2444/3450 [00:00<00:00, 13898.97it/s]
77%|#######7 | Sample : 2666/3450 [00:00<00:00, 13892.11it/s]
84%|########3 | Sample : 2889/3450 [00:00<00:00, 13890.29it/s]
90%|######### | Sample : 3113/3450 [00:00<00:00, 13896.64it/s]
97%|#########7| Sample : 3359/3450 [00:00<00:00, 14028.90it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 13993.33it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
8%|7 | Sample : 272/3450 [00:00<00:00, 16994.90it/s]
16%|#5 | Sample : 546/3450 [00:00<00:00, 17054.55it/s]
23%|##3 | Sample : 804/3450 [00:00<00:00, 16717.53it/s]
32%|###1 | Sample : 1090/3450 [00:00<00:00, 17022.38it/s]
40%|###9 | Sample : 1365/3450 [00:00<00:00, 17046.55it/s]
48%|####8 | Sample : 1668/3450 [00:00<00:00, 17395.99it/s]
58%|#####8 | Sample : 2009/3450 [00:00<00:00, 18043.18it/s]
68%|######8 | Sample : 2351/3450 [00:00<00:00, 18535.70it/s]
78%|#######8 | Sample : 2692/3450 [00:00<00:00, 18906.56it/s]
88%|########7 | Sample : 3034/3450 [00:00<00:00, 19211.76it/s]
96%|#########5| Sample : 3303/3450 [00:00<00:00, 18931.49it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 18827.04it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
9%|9 | Sample : 324/3450 [00:00<00:00, 20208.40it/s]
16%|#5 | Sample : 550/3450 [00:00<00:00, 17058.87it/s]
22%|##2 | Sample : 763/3450 [00:00<00:00, 15739.62it/s]
29%|##8 | Sample : 985/3450 [00:00<00:00, 15223.13it/s]
35%|###4 | Sample : 1206/3450 [00:00<00:00, 14904.36it/s]
41%|####1 | Sample : 1426/3450 [00:00<00:00, 14674.10it/s]
51%|##### | Sample : 1754/3450 [00:00<00:00, 15633.28it/s]
60%|###### | Sample : 2073/3450 [00:00<00:00, 16268.58it/s]
70%|######9 | Sample : 2403/3450 [00:00<00:00, 16855.61it/s]
79%|#######8 | Sample : 2720/3450 [00:00<00:00, 17216.79it/s]
87%|########7 | Sample : 3013/3450 [00:00<00:00, 17341.63it/s]
97%|#########6| Sample : 3335/3450 [00:00<00:00, 17642.25it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 17352.62it/s]
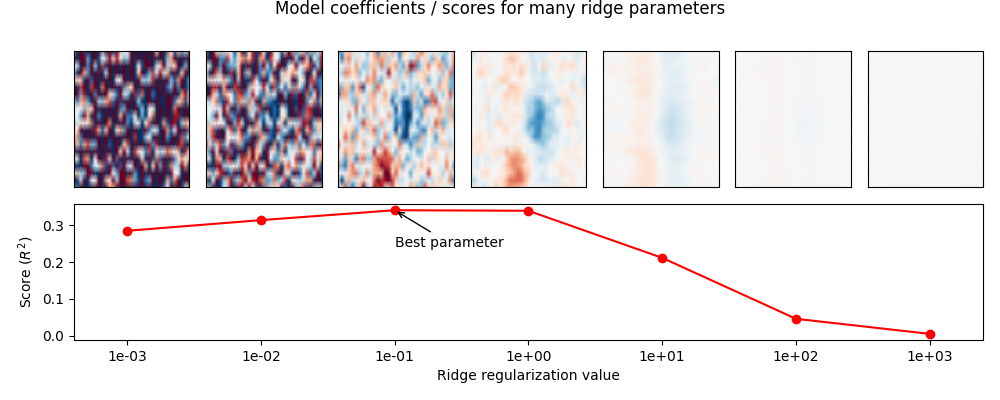
Visualize the effects of regularization#
Above we fit a mne.decoding.ReceptiveField model for one of many
values for the ridge regularization parameter. Here we will plot the model
score as well as the model coefficients for each value, in order to
visualize how coefficients change with different levels of regularization.
These issues as well as the STRF pipeline are described in detail
in [2][3][4].
# Plot model score for each ridge parameter
fig = plt.figure(figsize=(10, 4))
ax = plt.subplot2grid([2, len(alphas)], [1, 0], 1, len(alphas))
ax.plot(np.arange(len(alphas)), scores, marker="o", color="r")
ax.annotate(
"Best parameter",
(ix_best_alpha, scores[ix_best_alpha]),
(ix_best_alpha, scores[ix_best_alpha] - 0.1),
arrowprops={"arrowstyle": "->"},
)
plt.xticks(np.arange(len(alphas)), ["%.0e" % ii for ii in alphas])
ax.set(
xlabel="Ridge regularization value",
ylabel="Score ($R^2$)",
xlim=[-0.4, len(alphas) - 0.6],
)
mne.viz.tight_layout()
# Plot the STRF of each ridge parameter
for ii, (rf, i_alpha) in enumerate(zip(models, alphas)):
ax = plt.subplot2grid([2, len(alphas)], [0, ii], 1, 1)
ax.pcolormesh(times, rf.feature_names, rf.coef_[0], **kwargs)
plt.xticks([], [])
plt.yticks([], [])
plt.autoscale(tight=True)
fig.suptitle("Model coefficients / scores for many ridge parameters", y=1)
mne.viz.tight_layout()
Using different regularization types#
In addition to the standard ridge regularization, the
mne.decoding.TimeDelayingRidge class also exposes
Laplacian regularization
term as:
This imposes a smoothness constraint of nearby time samples and/or features. Quoting [1] :
Tikhonov [identity] regularization (Equation 5) reduces overfitting by smoothing the TRF estimate in a way that is insensitive to the amplitude of the signal of interest. However, the Laplacian approach (Equation 6) reduces off-sample error whilst preserving signal amplitude (Lalor et al., 2006). As a result, this approach usually leads to an improved estimate of the system’s response (as indexed by MSE) compared to Tikhonov regularization.
scores_lap = np.zeros_like(alphas)
models_lap = []
for ii, alpha in enumerate(alphas):
estimator = TimeDelayingRidge(tmin, tmax, sfreq, reg_type="laplacian", alpha=alpha)
rf = ReceptiveField(tmin, tmax, sfreq, freqs, estimator=estimator)
rf.fit(X_train, y_train)
# Now make predictions about the model output, given input stimuli.
scores_lap[ii] = rf.score(X_test, y_test)
models_lap.append(rf)
ix_best_alpha_lap = np.argmax(scores_lap)
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
9%|9 | Sample : 318/3450 [00:00<00:00, 19849.52it/s]
19%|#8 | Sample : 647/3450 [00:00<00:00, 20200.25it/s]
28%|##8 | Sample : 978/3450 [00:00<00:00, 20352.10it/s]
37%|###7 | Sample : 1292/3450 [00:00<00:00, 20129.79it/s]
47%|####6 | Sample : 1616/3450 [00:00<00:00, 20145.04it/s]
56%|#####6 | Sample : 1945/3450 [00:00<00:00, 20222.41it/s]
65%|######5 | Sample : 2252/3450 [00:00<00:00, 20047.52it/s]
75%|#######4 | Sample : 2578/3450 [00:00<00:00, 20093.77it/s]
84%|########4 | Sample : 2899/3450 [00:00<00:00, 20084.53it/s]
94%|#########3| Sample : 3232/3450 [00:00<00:00, 20172.25it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 20213.74it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
8%|7 | Sample : 264/3450 [00:00<00:00, 16422.15it/s]
13%|#3 | Sample : 465/3450 [00:00<00:00, 14442.43it/s]
21%|##1 | Sample : 726/3450 [00:00<00:00, 15071.89it/s]
30%|### | Sample : 1041/3450 [00:00<00:00, 16312.30it/s]
40%|#### | Sample : 1384/3450 [00:00<00:00, 17433.25it/s]
50%|##### | Sample : 1725/3450 [00:00<00:00, 18158.18it/s]
60%|#####9 | Sample : 2066/3450 [00:00<00:00, 18674.72it/s]
69%|######9 | Sample : 2382/3450 [00:00<00:00, 18828.24it/s]
78%|#######8 | Sample : 2704/3450 [00:00<00:00, 18999.55it/s]
88%|########8 | Sample : 3053/3450 [00:00<00:00, 19347.61it/s]
98%|#########8| Sample : 3394/3450 [00:00<00:00, 19574.48it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 19259.82it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
5%|5 | Sample : 180/3450 [00:00<00:00, 11204.73it/s]
10%|# | Sample : 360/3450 [00:00<00:00, 11225.32it/s]
16%|#5 | Sample : 541/3450 [00:00<00:00, 11250.90it/s]
21%|## | Sample : 721/3450 [00:00<00:00, 11243.03it/s]
27%|##6 | Sample : 921/3450 [00:00<00:00, 11471.74it/s]
33%|###2 | Sample : 1123/3450 [00:00<00:00, 11683.25it/s]
39%|###9 | Sample : 1351/3450 [00:00<00:00, 12099.26it/s]
46%|####5 | Sample : 1581/3450 [00:00<00:00, 12430.45it/s]
55%|#####5 | Sample : 1902/3450 [00:00<00:00, 13456.53it/s]
64%|######4 | Sample : 2224/3450 [00:00<00:00, 14283.59it/s]
73%|#######3 | Sample : 2534/3450 [00:00<00:00, 14867.20it/s]
82%|########2 | Sample : 2839/3450 [00:00<00:00, 15321.81it/s]
91%|#########1| Sample : 3153/3450 [00:00<00:00, 15755.24it/s]
99%|#########8| Sample : 3413/3450 [00:00<00:00, 15801.20it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 15193.26it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
5%|5 | Sample : 189/3450 [00:00<00:00, 11803.15it/s]
11%|# | Sample : 379/3450 [00:00<00:00, 11809.93it/s]
16%|#6 | Sample : 565/3450 [00:00<00:00, 11729.44it/s]
22%|##1 | Sample : 757/3450 [00:00<00:00, 11788.72it/s]
28%|##7 | Sample : 957/3450 [00:00<00:00, 11941.22it/s]
38%|###7 | Sample : 1305/3450 [00:00<00:00, 13787.23it/s]
47%|####7 | Sample : 1628/3450 [00:00<00:00, 14844.84it/s]
56%|#####6 | Sample : 1944/3450 [00:00<00:00, 15567.57it/s]
65%|######4 | Sample : 2242/3450 [00:00<00:00, 15975.83it/s]
73%|#######3 | Sample : 2531/3450 [00:00<00:00, 16220.26it/s]
83%|########2 | Sample : 2853/3450 [00:00<00:00, 16667.97it/s]
92%|#########1| Sample : 3158/3450 [00:00<00:00, 16924.97it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 16669.99it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
6%|5 | Sample : 198/3450 [00:00<00:00, 12356.01it/s]
13%|#3 | Sample : 457/3450 [00:00<00:00, 14301.16it/s]
22%|##2 | Sample : 762/3450 [00:00<00:00, 15965.14it/s]
31%|###1 | Sample : 1083/3450 [00:00<00:00, 17064.94it/s]
41%|#### | Sample : 1399/3450 [00:00<00:00, 17653.79it/s]
50%|##### | Sample : 1733/3450 [00:00<00:00, 18257.21it/s]
59%|#####9 | Sample : 2042/3450 [00:00<00:00, 18425.21it/s]
68%|######8 | Sample : 2355/3450 [00:00<00:00, 18588.94it/s]
78%|#######7 | Sample : 2686/3450 [00:00<00:00, 18865.52it/s]
87%|########7 | Sample : 3017/3450 [00:00<00:00, 19087.02it/s]
97%|#########6| Sample : 3343/3450 [00:00<00:00, 19232.20it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 19003.93it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
10%|9 | Sample : 336/3450 [00:00<00:00, 20958.73it/s]
20%|#9 | Sample : 674/3450 [00:00<00:00, 21033.30it/s]
29%|##8 | Sample : 993/3450 [00:00<00:00, 20637.75it/s]
38%|###8 | Sample : 1323/3450 [00:00<00:00, 20631.00it/s]
48%|####8 | Sample : 1660/3450 [00:00<00:00, 20715.97it/s]
58%|#####7 | Sample : 1987/3450 [00:00<00:00, 20650.59it/s]
67%|######6 | Sample : 2295/3450 [00:00<00:00, 20416.73it/s]
75%|#######5 | Sample : 2588/3450 [00:00<00:00, 20091.20it/s]
84%|########4 | Sample : 2908/3450 [00:00<00:00, 20077.91it/s]
94%|#########3| Sample : 3229/3450 [00:00<00:00, 20071.15it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 20166.02it/s]
Fitting 15 epochs, 20 channels
0%| | Sample : 0/3450 [00:00<?, ?it/s]
6%|5 | Sample : 205/3450 [00:00<00:00, 12759.05it/s]
12%|#1 | Sample : 409/3450 [00:00<00:00, 12745.07it/s]
18%|#7 | Sample : 618/3450 [00:00<00:00, 12839.94it/s]
24%|##3 | Sample : 827/3450 [00:00<00:00, 12886.62it/s]
30%|### | Sample : 1037/3450 [00:00<00:00, 12927.53it/s]
36%|###6 | Sample : 1245/3450 [00:00<00:00, 12941.10it/s]
42%|####2 | Sample : 1452/3450 [00:00<00:00, 12939.83it/s]
48%|####8 | Sample : 1662/3450 [00:00<00:00, 12959.92it/s]
54%|#####4 | Sample : 1875/3450 [00:00<00:00, 13002.70it/s]
60%|###### | Sample : 2083/3450 [00:00<00:00, 12998.08it/s]
66%|######6 | Sample : 2288/3450 [00:00<00:00, 12974.73it/s]
72%|#######2 | Sample : 2497/3450 [00:00<00:00, 12980.60it/s]
78%|#######8 | Sample : 2704/3450 [00:00<00:00, 12969.18it/s]
84%|########4 | Sample : 2909/3450 [00:00<00:00, 12952.91it/s]
90%|######### | Sample : 3120/3450 [00:00<00:00, 12969.36it/s]
97%|#########6| Sample : 3334/3450 [00:00<00:00, 13002.70it/s]
100%|##########| Sample : 3450/3450 [00:00<00:00, 12990.40it/s]
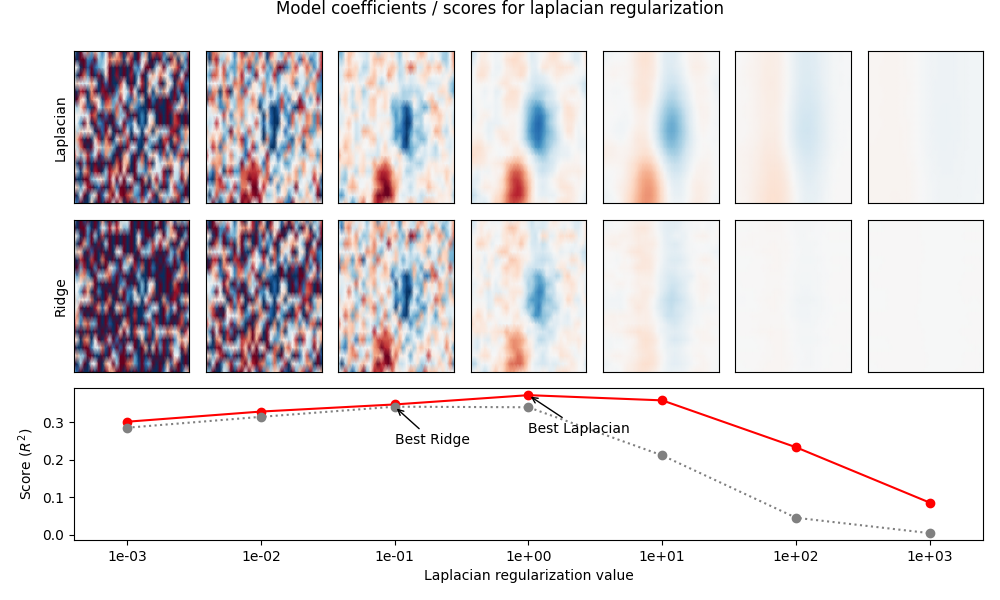
Compare model performance#
Below we visualize the model performance of each regularization method (ridge vs. Laplacian) for different levels of alpha. As you can see, the Laplacian method performs better in general, because it imposes a smoothness constraint along the time and feature dimensions of the coefficients. This matches the “true” receptive field structure and results in a better model fit.
fig = plt.figure(figsize=(10, 6))
ax = plt.subplot2grid([3, len(alphas)], [2, 0], 1, len(alphas))
ax.plot(np.arange(len(alphas)), scores_lap, marker="o", color="r")
ax.plot(np.arange(len(alphas)), scores, marker="o", color="0.5", ls=":")
ax.annotate(
"Best Laplacian",
(ix_best_alpha_lap, scores_lap[ix_best_alpha_lap]),
(ix_best_alpha_lap, scores_lap[ix_best_alpha_lap] - 0.1),
arrowprops={"arrowstyle": "->"},
)
ax.annotate(
"Best Ridge",
(ix_best_alpha, scores[ix_best_alpha]),
(ix_best_alpha, scores[ix_best_alpha] - 0.1),
arrowprops={"arrowstyle": "->"},
)
plt.xticks(np.arange(len(alphas)), ["%.0e" % ii for ii in alphas])
ax.set(
xlabel="Laplacian regularization value",
ylabel="Score ($R^2$)",
xlim=[-0.4, len(alphas) - 0.6],
)
mne.viz.tight_layout()
# Plot the STRF of each ridge parameter
xlim = times[[0, -1]]
for ii, (rf_lap, rf, i_alpha) in enumerate(zip(models_lap, models, alphas)):
ax = plt.subplot2grid([3, len(alphas)], [0, ii], 1, 1)
ax.pcolormesh(times, rf_lap.feature_names, rf_lap.coef_[0], **kwargs)
ax.set(xticks=[], yticks=[], xlim=xlim)
if ii == 0:
ax.set(ylabel="Laplacian")
ax = plt.subplot2grid([3, len(alphas)], [1, ii], 1, 1)
ax.pcolormesh(times, rf.feature_names, rf.coef_[0], **kwargs)
ax.set(xticks=[], yticks=[], xlim=xlim)
if ii == 0:
ax.set(ylabel="Ridge")
fig.suptitle("Model coefficients / scores for laplacian regularization", y=1)
mne.viz.tight_layout()
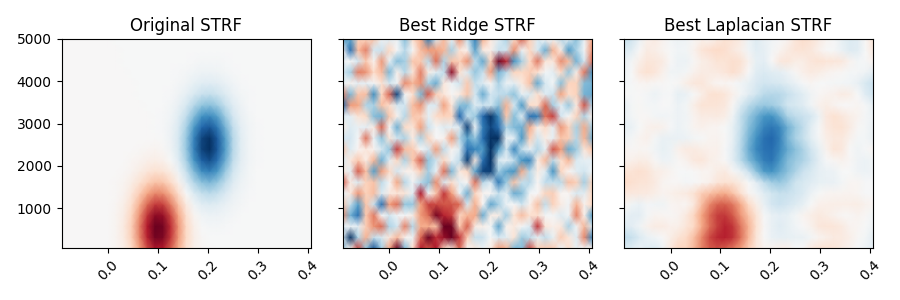
Plot the original STRF, and the one that we recovered with modeling.
rf = models[ix_best_alpha]
rf_lap = models_lap[ix_best_alpha_lap]
_, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(9, 3), sharey=True, sharex=True)
ax1.pcolormesh(delays_sec, freqs, weights, **kwargs)
ax2.pcolormesh(times, rf.feature_names, rf.coef_[0], **kwargs)
ax3.pcolormesh(times, rf_lap.feature_names, rf_lap.coef_[0], **kwargs)
ax1.set_title("Original STRF")
ax2.set_title("Best Ridge STRF")
ax3.set_title("Best Laplacian STRF")
plt.setp([iax.get_xticklabels() for iax in [ax1, ax2, ax3]], rotation=45)
plt.autoscale(tight=True)
mne.viz.tight_layout()
References#
Total running time of the script: ( 0 minutes 28.413 seconds)
Estimated memory usage: 10 MB