Note
Go to the end to download the full example code. or to run this example in your browser via Binder
GLM Analysis (Simulated)#
In this example we simulate a block design functional near-infrared spectroscopy (fNIRS) experiment and analyse the simulated signal. We investigate the effect additive noise and measurement length has on response amplitude estimates.
# sphinx_gallery_thumbnail_number = 3
# Authors: Robert Luke <mail@robertluke.net>
#
# License: BSD (3-clause)
import matplotlib.pylab as plt
import mne
import numpy as np
from nilearn.plotting import plot_design_matrix
import mne_nirs
from mne_nirs.experimental_design import make_first_level_design_matrix
from mne_nirs.statistics import run_glm
np.random.seed(1)
Simulate noise free NIRS data#
First we simulate some noise free data. We simulate 5 minutes of data with a block design. The inter stimulus interval of the stimuli is uniformly selected between 15 and 45 seconds. The amplitude of the simulated signal is 4 uMol and the sample rate is 3 Hz. The simulated signal is plotted below.
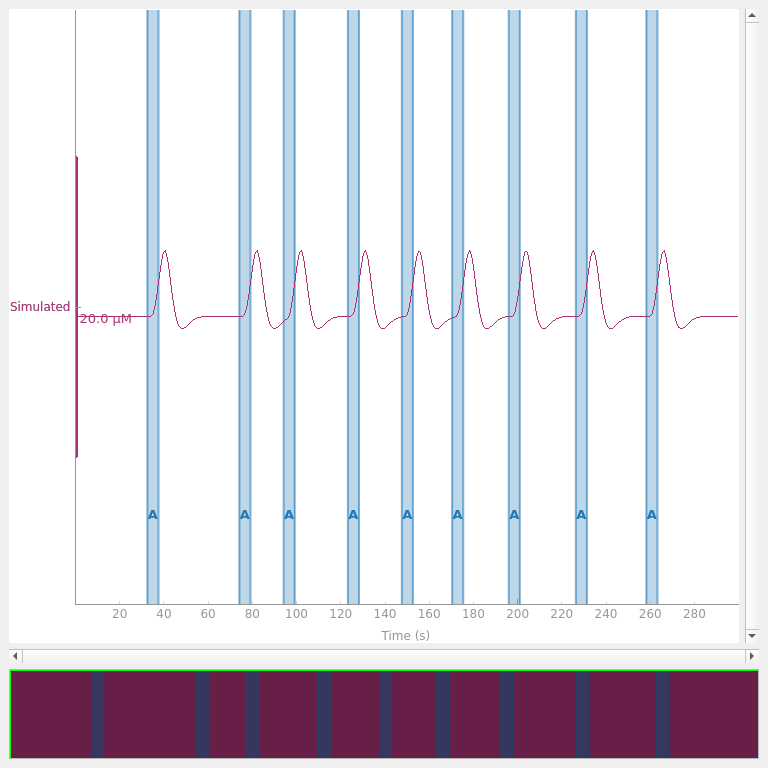
<mne_qt_browser._pg_figure.MNEQtBrowser object at 0x7fdb288a3b50>
Create design matrix#
Next we create a design matrix based on the annotation times in the simulated data. We use the nilearn plotting function to visualise the design matrix. For more details on this procedure see GLM Analysis (Measured).
design_matrix = make_first_level_design_matrix(
raw, stim_dur=5.0, drift_order=1, drift_model="polynomial"
)
fig, ax1 = plt.subplots(figsize=(10, 6), constrained_layout=True)
fig = plot_design_matrix(design_matrix, ax=ax1)
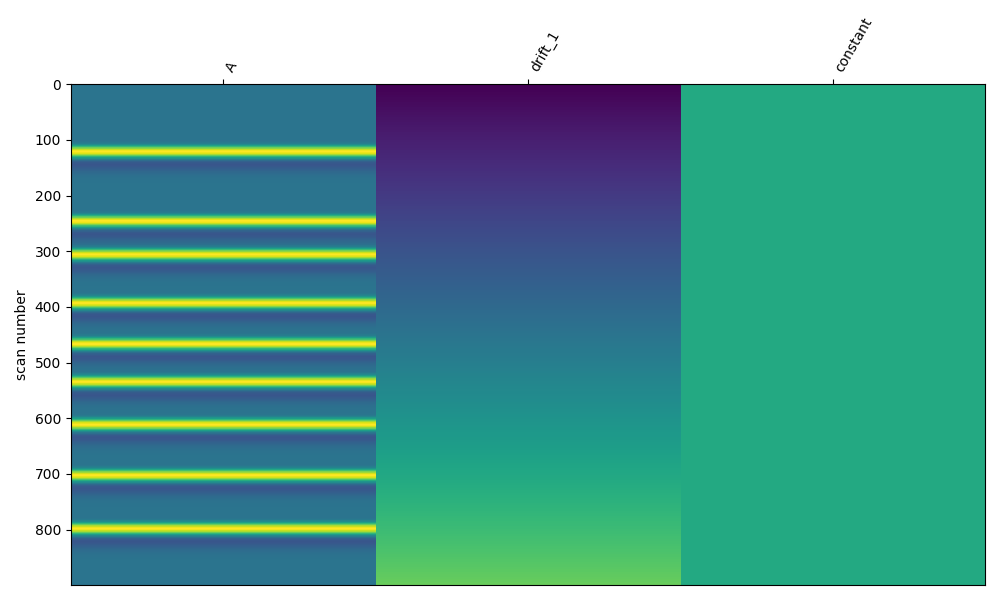
Estimate response on clean data#
Here we run the GLM analysis on the clean data. The design matrix had three columns, so we get an estimate for our simulated event, the first order drift, and the constant. We see that the estimate of the first component is 4e-6 (4 uM), which was the amplitude we used in the simulation. We also see that the mean square error of the model fit is close to zero.
glm_est = run_glm(raw, design_matrix)
def print_results(glm_est, truth):
"""Print the results of GLM estimate."""
print(
"Estimate:",
glm_est.theta()[0][0],
" MSE:",
glm_est.MSE()[0],
" Error (uM):",
1e6 * (glm_est.theta()[0][0] - truth * 1e-6),
)
print_results(glm_est, amp)
Estimate: [4.e-06] MSE: 4.437545829889748e-43 Error (uM): [0.]
Simulate noisy NIRS data (white)#
Real data has noise. Here we add white noise, this noise is not realistic but serves as a reference point for evaluating the estimation process. We run the GLM analysis exactly as in the previous section and plot the noisy data and the GLM fitted model. We print the response estimate and see that is close, but not exactly correct, we observe the mean square error is similar to the added noise. Note that the clean data plot is so similar to the GLM estimate that it is hard to see unless zoomed in.
# First take a copy of noise free data for comparison
raw_noise_free = raw.copy()
raw._data += np.random.normal(0, np.sqrt(1e-11), raw._data.shape)
glm_est = run_glm(raw, design_matrix)
fig, ax = plt.subplots(constrained_layout=True)
ax.plot(raw.times, raw_noise_free.get_data().T * 1e6)
ax.plot(raw.times, raw.get_data().T * 1e6, alpha=0.3)
ax.plot(raw.times, glm_est.theta()[0][0] * design_matrix["A"].values * 1e6)
ax.set(xlabel="Time (s)", ylabel="Haemoglobin (μM)")
ax.legend(["Clean Data", "Noisy Data", "GLM Estimate"])
print_results(glm_est, amp)
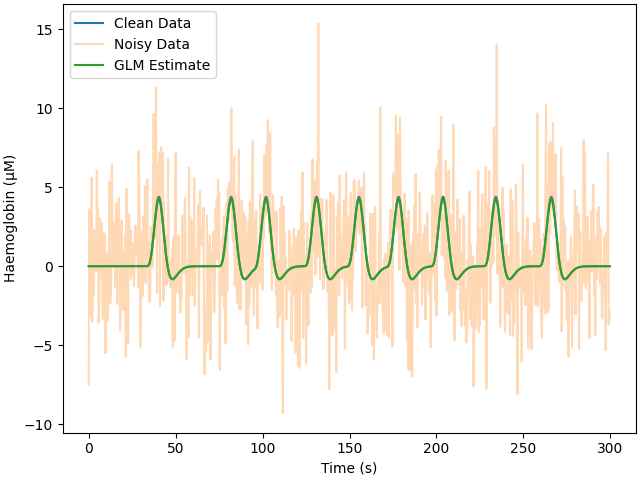
Estimate: [3.86092845e-06] MSE: 9.408292113143683e-12 Error (uM): [-0.13907155]
Simulate noisy NIRS data (colored)#
Here we add colored noise which better matches what is seen with real data. Again, the same GLM procedure is run. The estimate is reported below, and even though the signal was difficult to observe in the raw data, the GLM analysis has extracted an accurate estimate. However, the error is greater for the colored than white noise.
raw = raw_noise_free.copy()
cov = mne.Covariance(
np.ones(1) * 1e-11, raw.ch_names, raw.info["bads"], raw.info["projs"], nfree=0
)
raw = mne.simulation.add_noise(
raw,
cov,
iir_filter=[1.0, -0.58853134, -0.29575669, -0.52246482, 0.38735476, 0.02428681],
)
design_matrix = make_first_level_design_matrix(
raw, stim_dur=5.0, drift_order=1, drift_model="polynomial"
)
glm_est = run_glm(raw, design_matrix)
fig, ax = plt.subplots(constrained_layout=True)
ax.plot(raw.times, raw_noise_free.get_data().T * 1e6)
ax.plot(raw.times, raw.get_data().T * 1e6, alpha=0.3)
ax.plot(raw.times, glm_est.theta()[0][0] * design_matrix["A"].values * 1e6)
ax.set(xlabel="Time (s)", ylabel="Haemoglobin (μM)")
ax.legend(["Clean Data", "Noisy Data", "GLM Estimate"])
print_results(glm_est, amp)
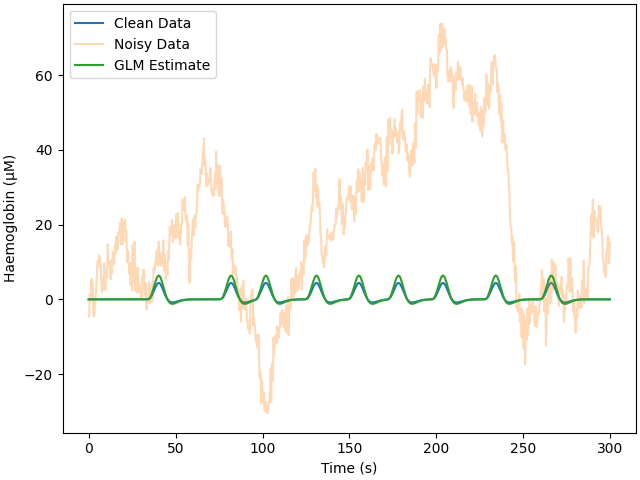
Adding noise to 1/1 channels (1 channels in cov)
Estimate: [5.7962519e-06] MSE: 4.702233956265054e-10 Error (uM): [1.7962519]
How does increasing the measurement length affect estimation accuracy?#
The easiest way to reduce error in your response estimate is to collect more data. Here we simulated increasing the recording time to 30 minutes. We run the same analysis and observe that the error is reduced from approximately 0.6 uM for 5 minutes of data to 0.25 uM for 30 minutes of data.
raw = mne_nirs.simulation.simulate_nirs_raw(
sfreq=sfreq, sig_dur=60 * 30, amplitude=amp, isi_min=15.0, isi_max=45.0
)
cov = mne.Covariance(
np.ones(1) * 1e-11, raw.ch_names, raw.info["bads"], raw.info["projs"], nfree=0
)
raw = mne.simulation.add_noise(
raw,
cov,
iir_filter=[1.0, -0.58853134, -0.29575669, -0.52246482, 0.38735476, 0.02428681],
)
design_matrix = make_first_level_design_matrix(
raw, stim_dur=5.0, drift_order=1, drift_model="polynomial"
)
glm_est = run_glm(raw, design_matrix)
fig, ax = plt.subplots(constrained_layout=True)
ax.plot(raw.times, raw.get_data().T * 1e6, alpha=0.3)
ax.plot(raw.times, glm_est.theta()[0][0] * design_matrix["A"].values * 1e6)
ax.set(xlabel="Time (s)", ylabel="Haemoglobin (μM)")
ax.legend(["Noisy Data", "GLM Estimate"])
print_results(glm_est, amp)
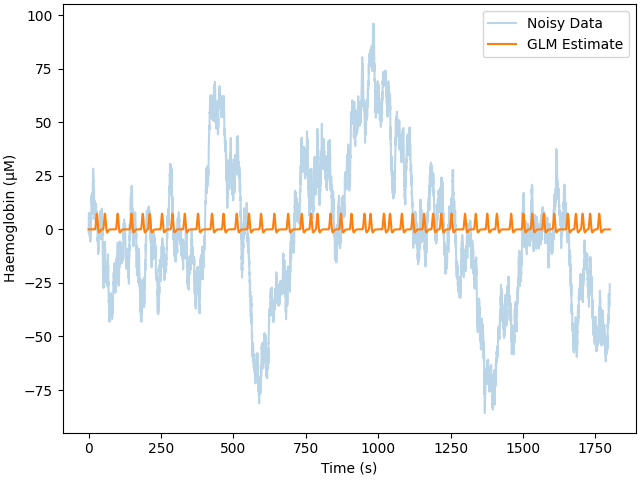
Adding noise to 1/1 channels (1 channels in cov)
Estimate: [6.68015442e-06] MSE: 1.1413529856049852e-09 Error (uM): [2.68015442]
Using autoregressive models in the GLM to account for noise structure#
An auto regressive noise model can be used account for temporal structure in the noise. To account for the noise properties in the example above, a fifth order auto regressive model is used below. Given this is a simulation, we can verify if the correct estimate of the noise properties was extracted from the data and if this improved the response estimate.
glm_est = run_glm(raw, design_matrix, noise_model="ar5")
fig, ax = plt.subplots(figsize=(15, 6), constrained_layout=True)
# actual values from model above
ax.plot([-0.58853134, -0.29575669, -0.52246482, 0.38735476, 0.02428681])
ax.plot(glm_est.model()[0].rho * -1.0) # estimates
ax.legend(["Simulation AR coefficients", "Estimated AR coefficients"])
ax.set_xlabel("Coefficient")
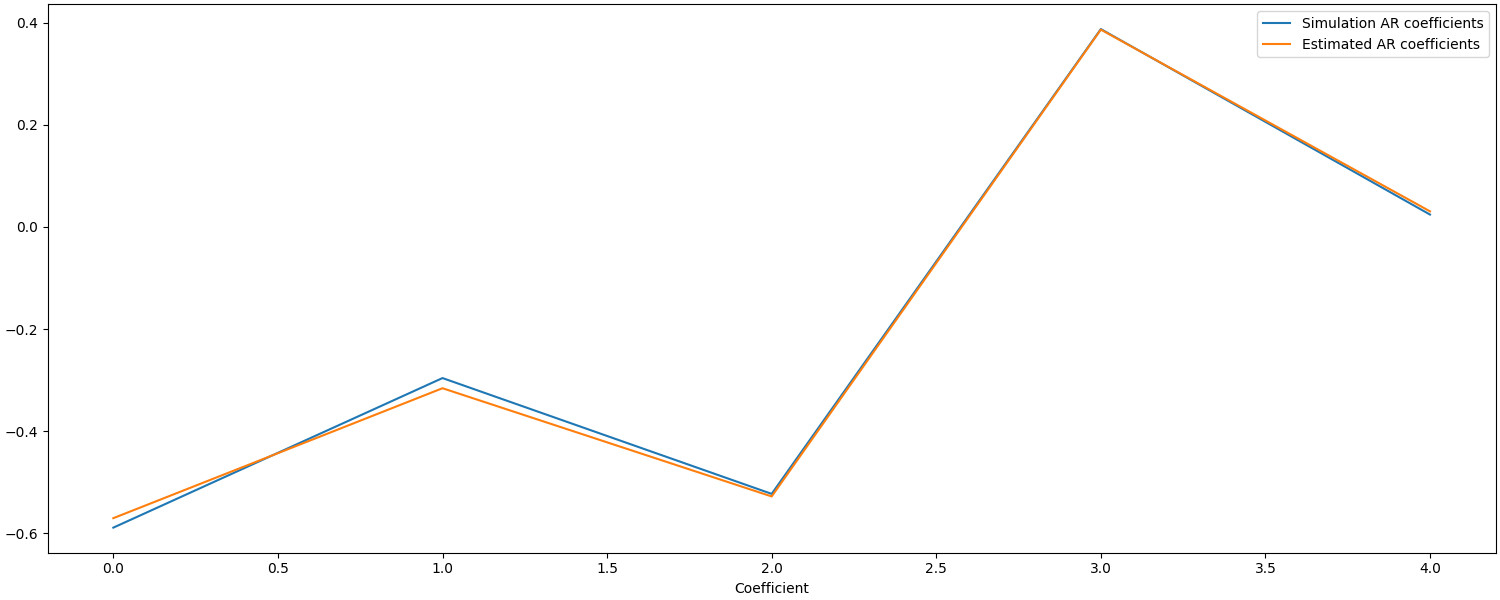
Text(0.5, 18.167, 'Coefficient')
We can see that the estimates from the GLM AR model are quite accurate, but how does this affect the accuracy of the response estimate?
Estimate: [4.41889913e-06] MSE: 9.881737675188427e-12 Error (uM): [0.41889913]
The response estimate using the AR(5) model is more accurate than the AR(1) model (error of 0.25 vs 2.8 uM).
Conclusion?#
In this example we have generated a noise free signal containing simulated haemodynamic responses. We were then able to accurately estimate the amplitude of the simulated signal. We then added noise and illustrated that the estimate provided by the GLM was correct, but contained some error. We observed that as the measurement time was increased, the estimated error decreased. We also observed in this idealised example that including an appropriate model of the noise can improve the accuracy of the response estimate.
Total running time of the script: (0 minutes 5.386 seconds)
Estimated memory usage: 433 MB