mne.time_frequency.EpochsTFR#
- class mne.time_frequency.EpochsTFR(info, data, times, freqs, comment=None, method=None, events=None, event_id=None, selection=None, drop_log=None, metadata=None, verbose=None)[source]#
Container for Time-Frequency data on epochs.
Can for example store induced power at sensor level.
- Parameters
- info
mne.Info The
mne.Infoobject with information about the sensors and methods of measurement.- data
ndarray, shape (n_epochs, n_channels, n_freqs, n_times) The data.
- times
ndarray, shape (n_times,) The time values in seconds.
- freqs
ndarray, shape (n_freqs,) The frequencies in Hz.
- comment
str|None, defaultNone Comment on the data, e.g., the experimental condition.
- method
str|None, defaultNone Comment on the method used to compute the data, e.g., morlet wavelet.
- events
ndarray, shape (n_events, 3) |None The events as stored in the Epochs class. If None (default), all event values are set to 1 and event time-samples are set to range(n_epochs).
- event_id
dict|None Example: dict(auditory=1, visual=3). They keys can be used to access associated events. If None, all events will be used and a dict is created with string integer names corresponding to the event id integers.
- selectioniterable |
None Iterable of indices of selected epochs. If
None, will be automatically generated, corresponding to all non-zero events.New in version 0.23.
- drop_log
tuple|None Tuple of tuple of strings indicating which epochs have been marked to be ignored.
New in version 0.23.
- metadatainstance of
pandas.DataFrame|None A
pandas.DataFramecontaining pertinent information for each trial. Seemne.Epochsfor further details.- verbosebool |
str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- info
- Attributes
- info
mne.Info The
mne.Infoobject with information about the sensors and methods of measurement.ch_nameslistChannel names.
- data
ndarray, shape (n_epochs, n_channels, n_freqs, n_times) The data array.
- times
ndarray, shape (n_times,) The time values in seconds.
- freqs
ndarray, shape (n_freqs,) The frequencies in Hz.
- comment
str Comment on dataset. Can be the condition.
- method
str|None, defaultNone Comment on the method used to compute the data, e.g., morlet wavelet.
- events
ndarray, shape (n_events, 3) |None Array containing sample information as event_id
- event_id
dict|None Names of conditions correspond to event_ids
- selection
array List of indices of selected events (not dropped or ignored etc.). For example, if the original event array had 4 events and the second event has been dropped, this attribute would be np.array([0, 2, 3]).
- drop_log
tupleoftuple A tuple of the same length as the event array used to initialize the
EpochsTFRobject. If the i-th original event is still part of the selection, drop_log[i] will be an empty tuple; otherwise it will be a tuple of the reasons the event is not longer in the selection, e.g.:'IGNORED'If it isn’t part of the current subset defined by the user
'NO_DATA'or'TOO_SHORT'If epoch didn’t contain enough data names of channels that exceeded the amplitude threshold
'EQUALIZED_COUNTS'
'USER'For user-defined reasons (see
drop()).
metadatapandas.DataFrame, shape (n_events, n_cols) |NoneGet the metadata.
- Notes
- —–
- .. versionadded:: 0.13.0
- info
Methods
__contains__(ch_type)Check channel type membership.
__getitem__(item)Return an Epochs object with a copied subset of epochs.
__iter__()Facilitate iteration over epochs.
__len__()Return the number of epochs.
add_channels(add_list[, force_update_info])Append new channels to the instance.
add_reference_channels(ref_channels)Add reference channels to data that consists of all zeros.
apply_baseline(baseline[, mode, verbose])Baseline correct the data.
average([method, dim, copy])Average the data across epochs.
copy()Return a copy of the instance.
crop([tmin, tmax, fmin, fmax, include_tmax])Crop data to a given time interval in place.
drop_channels(ch_names)Drop channel(s).
get_channel_types([picks, unique, only_data_chs])Get a list of channel type for each channel.
next([return_event_id])Iterate over epoch data.
pick(picks[, exclude, verbose])Pick a subset of channels.
pick_channels(ch_names[, ordered])Pick some channels.
pick_types([meg, eeg, stim, eog, ecg, emg, ...])Pick some channels by type and names.
reorder_channels(ch_names)Reorder channels.
save(fname[, overwrite, verbose])Save TFR object to hdf5 file.
to_data_frame([picks, index, long_format, ...])Export data in tabular structure as a pandas DataFrame.
- __contains__(ch_type)[source]#
Check channel type membership.
- Parameters
- ch_type
str Channel type to check for. Can be e.g. ‘meg’, ‘eeg’, ‘stim’, etc.
- ch_type
- Returns
- inbool
Whether or not the instance contains the given channel type.
Examples
Channel type membership can be tested as:
>>> 'meg' in inst True >>> 'seeg' in inst False
- __getitem__(item)[source]#
Return an Epochs object with a copied subset of epochs.
- Parameters
- item
slice, array-like,str, orlist See below for use cases.
- item
- Returns
- epochsinstance of
Epochs See below for use cases.
- epochsinstance of
Notes
Epochs can be accessed as
epochs[...]in several ways:Integer or slice:
epochs[idx]will return anEpochsobject with a subset of epochs chosen by index (supports single index and Python-style slicing).String:
epochs['name']will return anEpochsobject comprising only the epochs labeled'name'(i.e., epochs created around events with the label'name').If there are no epochs labeled
'name'but there are epochs labeled with /-separated tags (e.g.'name/left','name/right'), thenepochs['name']will select the epochs with labels that contain that tag (e.g.,epochs['left']selects epochs labeled'audio/left'and'visual/left', but not'audio_left').If multiple tags are provided as a single string (e.g.,
epochs['name_1/name_2']), this selects epochs containing all provided tags. For example,epochs['audio/left']selects'audio/left'and'audio/quiet/left', but not'audio/right'. Note that tag-based selection is insensitive to order: tags like'audio/left'and'left/audio'will be treated the same way when selecting via tag.List of strings:
epochs[['name_1', 'name_2', ... ]]will return anEpochsobject comprising epochs that match any of the provided names (i.e., the list of names is treated as an inclusive-or condition). If none of the provided names match any epoch labels, aKeyErrorwill be raised.If epoch labels are /-separated tags, then providing multiple tags as separate list entries will likewise act as an inclusive-or filter. For example,
epochs[['audio', 'left']]would select'audio/left','audio/right', and'visual/left', but not'visual/right'.Pandas query:
epochs['pandas query']will return anEpochsobject with a subset of epochs (and matching metadata) selected by the query called withself.metadata.eval, e.g.:epochs["col_a > 2 and col_b == 'foo'"]
would return all epochs whose associated
col_ametadata was greater than two, and whosecol_bmetadata was the string ‘foo’. Query-based indexing only works if Pandas is installed andself.metadatais apandas.DataFrame.New in version 0.16.
- __iter__()[source]#
Facilitate iteration over epochs.
This method resets the object iteration state to the first epoch.
Notes
This enables the use of this Python pattern:
>>> for epoch in epochs: >>> print(epoch)
Where
epochis given by successive outputs ofmne.Epochs.next().
- __len__()[source]#
Return the number of epochs.
- Returns
- n_epochs
int The number of remaining epochs.
- n_epochs
Notes
This function only works if bad epochs have been dropped.
Examples
This can be used as:
>>> epochs.drop_bad() >>> len(epochs) 43 >>> len(epochs.events) 43
- add_channels(add_list, force_update_info=False)[source]#
Append new channels to the instance.
- Parameters
- add_list
list A list of objects to append to self. Must contain all the same type as the current object.
- force_update_infobool
If True, force the info for objects to be appended to match the values in
self. This should generally only be used when adding stim channels for which important metadata won’t be overwritten.New in version 0.12.
- add_list
- Returns
See also
Notes
If
selfis a Raw instance that has been preloaded into anumpy.memmapinstance, the memmap will be resized.
- add_reference_channels(ref_channels)[source]#
Add reference channels to data that consists of all zeros.
Adds reference channels to data that were not included during recording. This is useful when you need to re-reference your data to different channels. These added channels will consist of all zeros.
- Parameters
- Returns
- apply_baseline(baseline, mode='mean', verbose=None)[source]#
Baseline correct the data.
- Parameters
- baselinearray-like, shape (2,)
The time interval to apply rescaling / baseline correction. If None do not apply it. If baseline is (a, b) the interval is between “a (s)” and “b (s)”. If a is None the beginning of the data is used and if b is None then b is set to the end of the interval. If baseline is equal to (None, None) all the time interval is used.
- mode‘mean’ | ‘ratio’ | ‘logratio’ | ‘percent’ | ‘zscore’ | ‘zlogratio’
Perform baseline correction by
subtracting the mean of baseline values (‘mean’)
dividing by the mean of baseline values (‘ratio’)
dividing by the mean of baseline values and taking the log (‘logratio’)
subtracting the mean of baseline values followed by dividing by the mean of baseline values (‘percent’)
subtracting the mean of baseline values and dividing by the standard deviation of baseline values (‘zscore’)
dividing by the mean of baseline values, taking the log, and dividing by the standard deviation of log baseline values (‘zlogratio’)
- verbosebool |
str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- Returns
- instinstance of
AverageTFR The modified instance.
- instinstance of
Examples using
apply_baseline: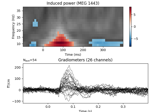
Non-parametric 1 sample cluster statistic on single trial power
Non-parametric 1 sample cluster statistic on single trial power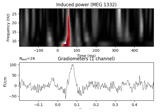
Non-parametric between conditions cluster statistic on single trial power
Non-parametric between conditions cluster statistic on single trial power
Spatiotemporal permutation F-test on full sensor data
Spatiotemporal permutation F-test on full sensor data
Mass-univariate twoway repeated measures ANOVA on single trial power
Mass-univariate twoway repeated measures ANOVA on single trial power
- average(method='mean', dim='epochs', copy=False)[source]#
Average the data across epochs.
- Parameters
- method
str|callable() How to combine the data. If “mean”/”median”, the mean/median are returned. Otherwise, must be a callable which, when passed an array of shape (n_epochs, n_channels, n_freqs, n_time) returns an array of shape (n_channels, n_freqs, n_time). Note that due to file type limitations, the kind for all these will be “average”.
- dim‘epochs’ | ‘freqs’ | ‘times’
The dimension along which to combine the data.
- copybool
Whether to return a copy of the modified instance, or modify in place. Ignored when
dim='epochs'because a new instance must be returned.
- method
- Returns
- aveinstance of
AverageTFR|EpochsTFR The averaged data.
- aveinstance of
Notes
Passing in
np.medianis considered unsafe when there is complex data because NumPy doesn’t compute the marginal median. Numpy currently sorts the complex values by real part and return whatever value is computed. Use with caution. We use the marginal median in the complex case (i.e. the median of each component separately) if one passes inmedian. See a discussion in scipy:https://github.com/scipy/scipy/pull/12676#issuecomment-783370228
Examples using
average:
- property ch_names#
Channel names.
- property compensation_grade#
The current gradient compensation grade.
- copy()[source]#
Return a copy of the instance.
- Returns
- copyinstance of
EpochsTFR| instance ofAverageTFR A copy of the instance.
- copyinstance of
- crop(tmin=None, tmax=None, fmin=None, fmax=None, include_tmax=True)[source]#
Crop data to a given time interval in place.
- Parameters
- tmin
float|None Start time of selection in seconds.
- tmax
float|None End time of selection in seconds.
- fmin
float|None Lowest frequency of selection in Hz.
New in version 0.18.0.
- fmax
float|None Highest frequency of selection in Hz.
New in version 0.18.0.
- include_tmaxbool
If True (default), include tmax. If False, exclude tmax (similar to how Python indexing typically works).
New in version 0.19.
- tmin
- Returns
- instinstance of
AverageTFR The modified instance.
- instinstance of
Examples using
crop:
Non-parametric 1 sample cluster statistic on single trial power
Non-parametric 1 sample cluster statistic on single trial power
- drop_channels(ch_names)[source]#
Drop channel(s).
- Parameters
- Returns
See also
Notes
New in version 0.9.0.
- get_channel_types(picks=None, unique=False, only_data_chs=False)[source]#
Get a list of channel type for each channel.
- Parameters
- picks
str|list|slice|None Channels to include. Slices and lists of integers will be interpreted as channel indices. In lists, channel type strings (e.g.,
['meg', 'eeg']) will pick channels of those types, channel name strings (e.g.,['MEG0111', 'MEG2623']will pick the given channels. Can also be the string values “all” to pick all channels, or “data” to pick data channels. None (default) will pick all channels. Note that channels ininfo['bads']will be included if their names or indices are explicitly provided.- uniquebool
Whether to return only unique channel types. Default is
False.- only_data_chsbool
Whether to ignore non-data channels. Default is
False.
- picks
- Returns
- channel_types
list The channel types.
- channel_types
- property metadata#
Get the metadata.
- pick(picks, exclude=(), *, verbose=None)[source]#
Pick a subset of channels.
- Parameters
- picks
str|list|slice|None Channels to include. Slices and lists of integers will be interpreted as channel indices. In lists, channel type strings (e.g.,
['meg', 'eeg']) will pick channels of those types, channel name strings (e.g.,['MEG0111', 'MEG2623']will pick the given channels. Can also be the string values “all” to pick all channels, or “data” to pick data channels. None (default) will pick all channels. Note that channels ininfo['bads']will be included if their names or indices are explicitly provided.- exclude
list|str Set of channels to exclude, only used when picking based on types (e.g., exclude=”bads” when picks=”meg”).
- verbosebool |
str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.New in version 0.24.0.
- picks
- Returns
- pick_channels(ch_names, ordered=False)[source]#
Pick some channels.
- Parameters
- Returns
See also
Notes
The channel names given are assumed to be a set, i.e. the order does not matter. The original order of the channels is preserved. You can use
reorder_channelsto set channel order if necessary.New in version 0.9.0.
- pick_types(meg=False, eeg=False, stim=False, eog=False, ecg=False, emg=False, ref_meg='auto', misc=False, resp=False, chpi=False, exci=False, ias=False, syst=False, seeg=False, dipole=False, gof=False, bio=False, ecog=False, fnirs=False, csd=False, dbs=False, include=(), exclude='bads', selection=None, verbose=None)[source]#
Pick some channels by type and names.
- Parameters
- megbool |
str If True include MEG channels. If string it can be ‘mag’, ‘grad’, ‘planar1’ or ‘planar2’ to select only magnetometers, all gradiometers, or a specific type of gradiometer.
- eegbool
If True include EEG channels.
- stimbool
If True include stimulus channels.
- eogbool
If True include EOG channels.
- ecgbool
If True include ECG channels.
- emgbool
If True include EMG channels.
- ref_megbool |
str If True include CTF / 4D reference channels. If ‘auto’, reference channels are included if compensations are present and
megis not False. Can also be the string options for themegparameter.- miscbool
If True include miscellaneous analog channels.
- respbool
If
Trueinclude respiratory channels.- chpibool
If True include continuous HPI coil channels.
- excibool
Flux excitation channel used to be a stimulus channel.
- iasbool
Internal Active Shielding data (maybe on Triux only).
- systbool
System status channel information (on Triux systems only).
- seegbool
Stereotactic EEG channels.
- dipolebool
Dipole time course channels.
- gofbool
Dipole goodness of fit channels.
- biobool
Bio channels.
- ecogbool
Electrocorticography channels.
- fnirsbool |
str Functional near-infrared spectroscopy channels. If True include all fNIRS channels. If False (default) include none. If string it can be ‘hbo’ (to include channels measuring oxyhemoglobin) or ‘hbr’ (to include channels measuring deoxyhemoglobin).
- csdbool
EEG-CSD channels.
- dbsbool
Deep brain stimulation channels.
- include
listofstr List of additional channels to include. If empty do not include any.
- exclude
listofstr|str List of channels to exclude. If ‘bads’ (default), exclude channels in
info['bads'].- selection
listofstr Restrict sensor channels (MEG, EEG) to this list of channel names.
- verbosebool |
str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- megbool |
- Returns
See also
Notes
New in version 0.9.0.
- reorder_channels(ch_names)[source]#
Reorder channels.
- Parameters
- ch_names
list The desired channel order.
- ch_names
- Returns
See also
Notes
Channel names must be unique. Channels that are not in
ch_namesare dropped.New in version 0.16.0.
- save(fname, overwrite=False, *, verbose=None)[source]#
Save TFR object to hdf5 file.
- Parameters
- fname
str The file name, which should end with
-tfr.h5.- overwritebool
If True (default False), overwrite the destination file if it exists.
- verbosebool |
str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- fname
See also
- to_data_frame(picks=None, index=None, long_format=False, time_format='ms', *, verbose=None)[source]#
Export data in tabular structure as a pandas DataFrame.
Channels are converted to columns in the DataFrame. By default, additional columns
'time','freq','epoch', and'condition'(epoch event description) are added, unlessindexis notNone(in which case the columns specified inindexwill be used to form the DataFrame’s index instead).'epoch', and'condition'are not supported forAverageTFR.- Parameters
- picks
str|list|slice|None Channels to include. Slices and lists of integers will be interpreted as channel indices. In lists, channel type strings (e.g.,
['meg', 'eeg']) will pick channels of those types, channel name strings (e.g.,['MEG0111', 'MEG2623']will pick the given channels. Can also be the string values “all” to pick all channels, or “data” to pick data channels. None (default) will pick all channels. Note that channels ininfo['bads']will be included if their names or indices are explicitly provided.- index
str|listofstr|None Kind of index to use for the DataFrame. If
None, a sequential integer index (pandas.RangeIndex) will be used. If'time', apandas.Float64Index,pandas.Int64Index, orpandas.TimedeltaIndexwill be used (depending on the value oftime_format). If a list of two or more string values, apandas.MultiIndexwill be created. Valid string values are'time','freq','epoch', and'condition'forEpochsTFRand'time'and'freq'forAverageTFR. Defaults toNone.- long_formatbool
If True, the DataFrame is returned in long format where each row is one observation of the signal at a unique combination of time point, channel, epoch number, and condition. For convenience, a
ch_typecolumn is added to facilitate subsetting the resulting DataFrame. Defaults toFalse.- time_format
str|None Desired time format. If
None, no conversion is applied, and time values remain as float values in seconds. If'ms', time values will be rounded to the nearest millisecond and converted to integers. If'timedelta', time values will be converted topandas.Timedeltavalues. Default is'ms'in version 0.22, and will change toNonein version 0.23.New in version 0.23.
- verbosebool |
str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- picks
- Returns
- dfinstance of
pandas.DataFrame A dataframe suitable for usage with other statistical/plotting/analysis packages.
- dfinstance of
Examples using
to_data_frame:

Examples using mne.time_frequency.EpochsTFR#
Non-parametric 1 sample cluster statistic on single trial power
Non-parametric between conditions cluster statistic on single trial power
Spatiotemporal permutation F-test on full sensor data
Mass-univariate twoway repeated measures ANOVA on single trial power
Time-frequency on simulated data (Multitaper vs. Morlet vs. Stockwell)