Note
Click here to download the full example code
Importing data from fNIRS devices¶
fNIRS devices consist of two kinds of optodes: light sources (AKA “emitters” or “transmitters”) and light detectors (AKA “receivers”). Channels are defined as source-detector pairs, and channel locations are defined as the midpoint between source and detector.
MNE-Python provides functions for reading fNIRS data and optode locations from several file formats. Regardless of the device manufacturer or file format, MNE-Python’s fNIRS functions will internally store the measurement data and its metadata in the same way (e.g., data values are always converted into SI units). Supported measurement types include amplitude, optical density, oxyhaemoglobin concentration, and deoxyhemoglobin concentration (for continuous wave fNIRS), and additionally AC amplitude and phase (for frequency domain fNIRS).
Warning
MNE-Python stores metadata internally with a specific structure, and internal functions expect specific naming conventions. Manual modification of channel names and metadata is not recommended.
Standardized data¶
SNIRF (.snirf)¶
The Shared Near Infrared Spectroscopy Format
(SNIRF)
is designed by the fNIRS community in an effort to facilitate
sharing and analysis of fNIRS data. And is the official format of the
Society for functional near-infrared spectroscopy (SfNIRS).
SNIRF is the preferred format for reading data in to MNE-Python.
Data stored in the SNIRF format can be read in
using mne.io.read_raw_snirf().
Note
The SNIRF format has provisions for many different types of fNIRS recordings. MNE-Python currently only supports reading continuous wave data stored in the .snirf format.
Continuous Wave Devices¶
NIRx (directory or hdr)¶
NIRx produce continuous wave fNIRS devices.
NIRx recordings can be read in using mne.io.read_raw_nirx().
The NIRx device stores data directly to a directory with multiple file types,
MNE-Python extracts the appropriate information from each file.
MNE-Python only supports NIRx files recorded with NIRStar
version 15.0 and above.
MNE-Python supports reading data from NIRScout and NIRSport 1 devices.
Hitachi (.csv)¶
Hitachi produce continuous wave fNIRS devices.
Hitachi fNIRS recordings can be read using mne.io.read_raw_hitachi().
No optode information is stored so you’ll need to set the montage manually,
see the Notes section of mne.io.read_raw_hitachi().
Frequency Domain Devices¶
BOXY (.txt)¶
BOXY recordings can be read in using mne.io.read_raw_boxy().
The BOXY software and ISS Imagent I and II devices are frequency domain
systems that store data in a single .txt file containing what they call
(with MNE-Python’s name for that type of data in parens):
- DC
All light collected by the detector (
fnirs_cw_amplitude)
- AC
High-frequency modulated light intensity (
fnirs_fd_ac_amplitude)
- Phase
Phase of the modulated light (
fnirs_fd_phase)
DC data is stored as the type fnirs_cw_amplitude because it
collects both the modulated and any unmodulated light, and hence is analogous
to what is collected by continuous wave systems such as NIRx. This helps with
conformance to SNIRF standard types.
These raw data files can be saved by the acquisition devices as parsed or
unparsed .txt files, which affects how the data in the file is organised.
MNE-Python will read either file type and extract the raw DC, AC,
and Phase data. If triggers are sent using the digaux port of the
recording hardware, MNE-Python will also read the digaux data and
create annotations for any triggers.
Custom Data Import¶
Loading legacy data in CSV or TSV format¶
Warning
This method is not supported and users are discouraged to use it.
You should convert your data to the
SNIRF format using the tools
provided by the Society for functional Near-Infrared Spectroscopy,
and then load it using mne.io.read_raw_snirf().
fNIRS measurements may be stored in a non-standardised format that is not supported by MNE-Python and cannot be converted easily into SNIRF. This legacy data is often in CSV or TSV format, we show here a way to load it even though it is not officially supported by MNE-Python due to the lack of standardisation of the file format (the naming and ordering of channels, the type and scaling of data, and specification of sensor positions varies between each vendor). You will likely have to adapt this depending on the system from which your CSV originated.
import os.path as op
import numpy as np
import pandas as pd
import mne
First, we generate an example CSV file which will then be loaded in to MNE-Python. This step would be skipped if you have actual data you wish to load. We simulate 16 channels with 100 samples of data and save this to a file called fnirs.csv.
pd.DataFrame(np.random.normal(size=(16, 100))).to_csv("fnirs.csv")
Warning
The channels must be ordered in haemoglobin pairs, such that for a single channel all the types are in subsequent indices. The type order must be ‘hbo’ then ‘hbr’. The data below is already in the correct order and may be used as a template for how data must be stored. If the order that your data is stored is different to the mandatory formatting, then you must first read the data with channel naming according to the data structure, then reorder the channels to match the required format.
Next, we will load the example CSV file.
data = pd.read_csv('fnirs.csv')
Then, the metadata must be specified manually as the CSV file does not contain information about channel names, types, sample rate etc.
Warning
In MNE-Python the naming of channels MUST follow the structure
S#_D# type where # is replaced by the appropriate source and
detector numbers and type is either hbo, hbr or the
wavelength.
ch_names = ['S1_D1 hbo', 'S1_D1 hbr', 'S2_D1 hbo', 'S2_D1 hbr',
'S3_D1 hbo', 'S3_D1 hbr', 'S4_D1 hbo', 'S4_D1 hbr',
'S5_D2 hbo', 'S5_D2 hbr', 'S6_D2 hbo', 'S6_D2 hbr',
'S7_D2 hbo', 'S7_D2 hbr', 'S8_D2 hbo', 'S8_D2 hbr']
ch_types = ['hbo', 'hbr', 'hbo', 'hbr',
'hbo', 'hbr', 'hbo', 'hbr',
'hbo', 'hbr', 'hbo', 'hbr',
'hbo', 'hbr', 'hbo', 'hbr']
sfreq = 10. # in Hz
Finally, the data can be converted in to an MNE-Python data structure.
The metadata above is used to create an mne.Info data structure,
and this is combined with the data to create an MNE-Python
Raw object. For more details on the info structure
see The Info data structure, and for additional details on how continuous data
is stored in MNE-Python see The Raw data structure: continuous data.
For a more extensive description of how to create MNE-Python data structures
from raw array data see Creating MNE-Python data structures from scratch.
Out:
Creating RawArray with float64 data, n_channels=16, n_times=101
Range : 0 ... 100 = 0.000 ... 10.000 secs
Ready.
Applying standard sensor locations to imported data¶
Having information about optode locations may assist in your analysis. Beyond the general benefits this provides (e.g. creating regions of interest, etc), this is may be particularly important for fNIRS as information about the optode locations is required to convert the optical density data in to an estimate of the haemoglobin concentrations. MNE-Python provides methods to load standard sensor configurations (montages) from some vendors, and this is demonstrated below. Some handy tutorials for understanding sensor locations, coordinate systems, and how to store and view this information in MNE-Python are: Working with sensor locations, Source alignment and coordinate frames, and Plotting EEG sensors on the scalp.
Below is an example of how to load the optode positions for an Artinis OctaMon device.
Note
It is also possible to create a custom montage from a file for
fNIRS with mne.channels.read_custom_montage() by setting
coord_frame to 'mri'.
montage = mne.channels.make_standard_montage('artinis-octamon')
raw.set_montage(montage)
# View the position of optodes in 2D to confirm the positions are correct.
raw.plot_sensors()
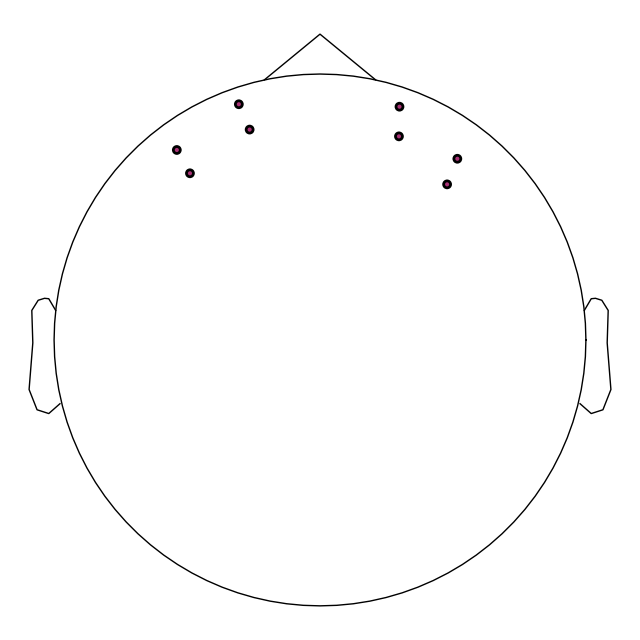
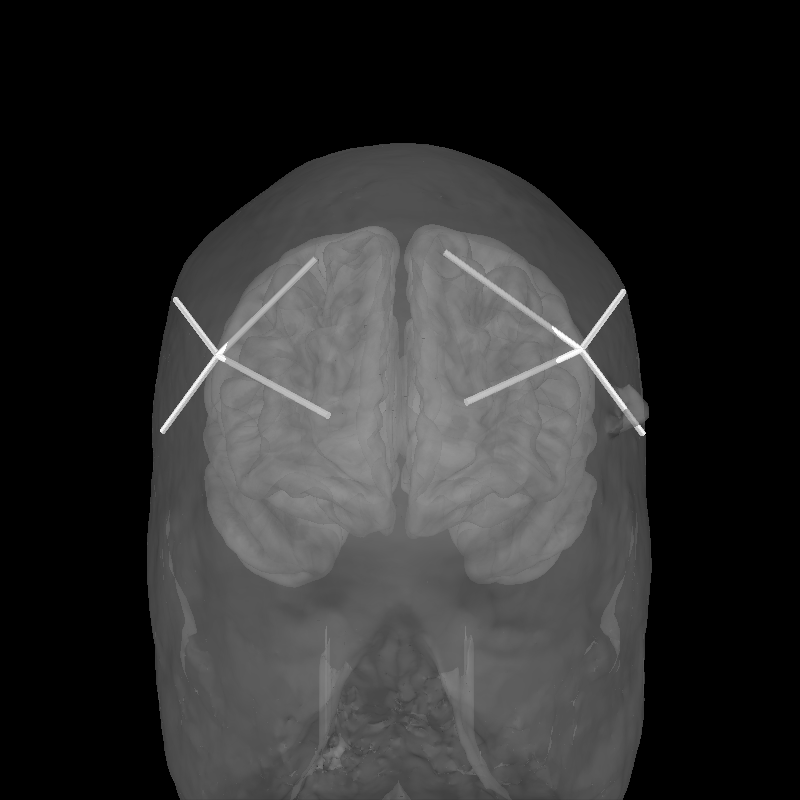
To validate the positions were loaded correctly it is also possible to view the location of the sources (red), detectors (black), and channels (white lines and orange dots) in a 3D representation. The ficiduals are marked in blue, green and red. See Source alignment and coordinate frames for more details.
subjects_dir = op.join(mne.datasets.sample.data_path(), 'subjects')
mne.datasets.fetch_fsaverage(subjects_dir=subjects_dir)
brain = mne.viz.Brain('fsaverage', subjects_dir=subjects_dir,
alpha=0.5, cortex='low_contrast')
brain.add_head()
brain.add_sensors(raw.info, trans='fsaverage')
brain.enable_depth_peeling()
brain.show_view(azimuth=90, elevation=90, distance=500)
Out:
0 files missing from root.txt in /home/circleci/mne_data/MNE-sample-data/subjects
0 files missing from bem.txt in /home/circleci/mne_data/MNE-sample-data/subjects/fsaverage
Using fsaverage-head-dense.fif for head surface.
1 BEM surfaces found
Reading a surface...
[done]
1 BEM surfaces read
Channel types:: hbo: 8, hbr: 8
Total running time of the script: ( 0 minutes 12.589 seconds)
Estimated memory usage: 65 MB