Note
Go to the end to download the full example code.
Blind Source Separation and ICA Equivalence.#
This example demonstrates how Nonlinear DSS can perform Blind Source Separation (BSS), effectively recovering independent sources from mixed signals. It explicitly shows the equivalence between DSS with specific nonlinearities and ICA.
It covers synthetic blind source separation, the link between DSS nonlinearities and FastICA, and a real MEG decomposition that exposes both artifact and brain-like components.
- Authors: Sina Esmaeili (sina.esmaeili@umontreal.ca)
Hamza Abdelhedi (hamza.abdelhedi@umontreal.ca)
import matplotlib.pyplot as plt
import mne
import numpy as np
from mne.datasets import sample
from scipy import stats
from mne_denoise.dss import IterativeDSS, KurtosisDenoiser, TanhMaskDenoiser, beta_tanh
from mne_denoise.viz import (
plot_component_summary,
plot_component_time_series,
plot_signal_overlay,
)
print(__doc__)
Part 1: Synthetic Blind Source Separation#
We generate synthetic sources with different statistical properties (Super-Gaussian, Sub-Gaussian) and mix them linearly. We then attempt to recover them using DSS and FastICA.
print("\n--- 1. Creating Synthetic Mixed Data ---")
n_samples = 2000
time = np.linspace(0, 8, n_samples)
# 1. Super-Gaussian (Laplace) - "Sparse" / "Bursty"
s1 = stats.laplace.rvs(size=n_samples)
s1 /= s1.std()
# 2. Super-Gaussian (Square Wave) - High Kurtosis
s2 = np.sign(np.sin(3 * time))
s2 /= s2.std()
# 3. Sub-Gaussian (Sinusoid) - Low Kurtosis
s3 = np.sin(10 * time)
s3 /= s3.std()
# 4. Gaussian Noise
s4 = np.random.randn(n_samples)
# Stack true sources
S_true = np.c_[s1, s2, s3, s4].T
n_sources = S_true.shape[0]
# Mix sources
np.random.seed(42)
A = np.random.randn(n_sources, n_sources) # Mixing matrix
X = np.dot(A, S_true) # Mixed signals
# Visualize
fig, axes = plt.subplots(3, 1, figsize=(10, 8), sharex=True)
axes[0].plot(time, S_true.T + np.arange(n_sources) * 5)
axes[0].set_title("True Sources")
axes[0].set_yticks(np.arange(n_sources) * 5)
axes[0].set_yticklabels([f"S{i}" for i in range(n_sources)])
axes[1].plot(time, X.T + np.arange(n_sources) * 5)
axes[1].set_title("Mixed Signals (Input)")
axes[1].set_yticks(np.arange(n_sources) * 5)
plt.tight_layout()
plt.show()
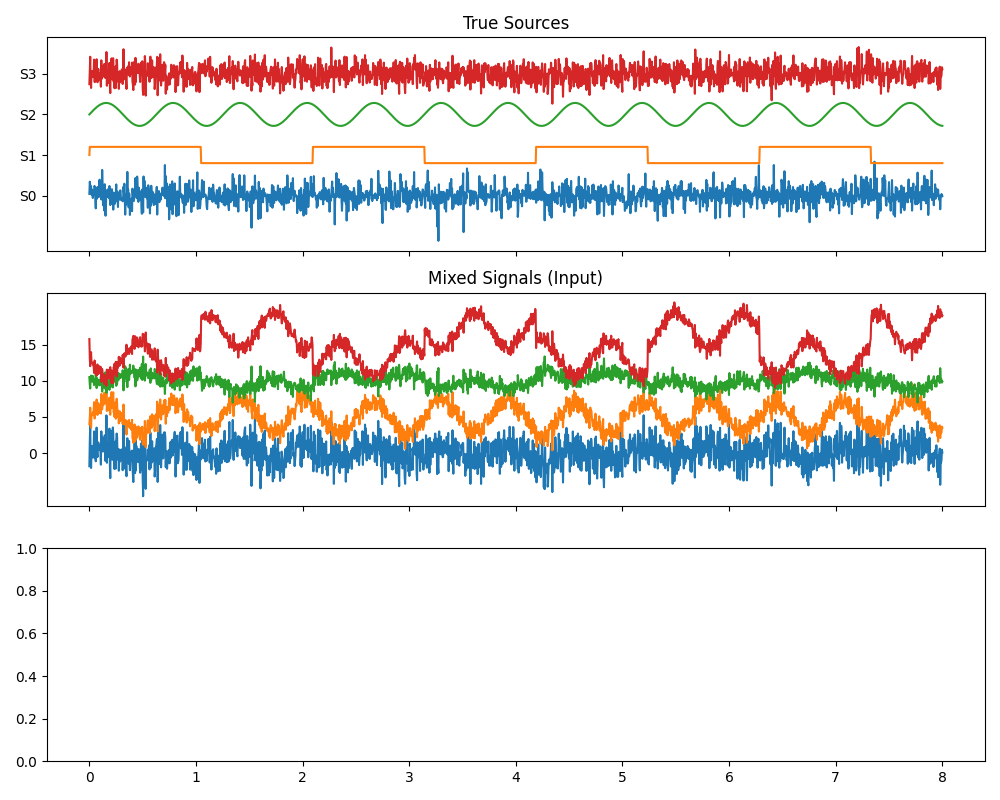
--- 1. Creating Synthetic Mixed Data ---
Run DSS with Tanh Nonlinearity (Robust ICA)#
The TanhMaskDenoiser implements the tanh nonlinearity, which is robust to outliers.
This section compares the Newton-style update (beta=beta_tanh) with plain gradient ascent (beta=None). The faster convergence is the same idea that makes FastICA efficient in practice.
print("\nRunning DSS with Tanh Nonlinearity (Robust)...")
# 1. Gradient Ascent (Slow)
print(" Fitting with Gradient Ascent (beta=None)...")
dss_grad = IterativeDSS(
denoiser=TanhMaskDenoiser(),
method="deflation",
n_components=n_sources,
beta=None, # Gradient ascent
random_state=42,
verbose=False,
)
dss_grad.fit(X)
# 2. Newton Method (Fast - FastICA style)
print(" Fitting with Newton Method (beta=beta_tanh)...")
dss_tanh = IterativeDSS(
denoiser=TanhMaskDenoiser(),
method="deflation",
n_components=n_sources,
beta=beta_tanh, # Newton step
random_state=42,
verbose=False,
)
dss_tanh.fit(X)
S_dss_tanh = dss_tanh.transform(X)
# Compare iterations
iters_grad = dss_grad.convergence_info_[:, 0].sum()
iters_newton = dss_tanh.convergence_info_[:, 0].sum()
print(f" Gradient Iterations: {iters_grad:.0f}")
print(
f" Newton Iterations: {iters_newton:.0f} "
f"(Speedup: {iters_grad / iters_newton:.1f}x)"
)
Running DSS with Tanh Nonlinearity (Robust)...
Fitting with Gradient Ascent (beta=None)...
Fitting with Newton Method (beta=beta_tanh)...
Gradient Iterations: 140
Newton Iterations: 20 (Speedup: 7.0x)
Run DSS with Kurtosis Nonlinearity (Standard FastICA)#
KurtosisDenoiser with nonlinearity=’cube’ maximizes kurtosis ($s^3$), which is the classic definition of FastICA.
print("Running DSS with Kurtosis Nonlinearity (FastICA standard)...")
dss_kurt = IterativeDSS(
denoiser=KurtosisDenoiser(nonlinearity="cube"),
method="deflation",
n_components=n_sources,
beta=-3.0, # Newton step for kurtosis
random_state=42,
verbose=False,
)
dss_kurt.fit(X)
S_dss_kurt = dss_kurt.transform(X)
Running DSS with Kurtosis Nonlinearity (FastICA standard)...
Comparison with sklearn FastICA#
We run sklearn.decomposition.FastICA to serve as a ground truth benchmark.
from sklearn.decomposition import FastICA
print("Running sklearn FastICA (Benchmark)...")
ica = FastICA(
n_components=n_sources, algorithm="deflation", fun="logcosh", random_state=42
)
S_fastica = ica.fit_transform(X.T).T
Running sklearn FastICA (Benchmark)...
Evaluate Performance (Correlation with True Sources)#
We compute the absolute correlation matrix between recovered components and true sources. A perfect recovery would have one 1.0 per row/column (permutation matrix).
def match_sources(S_est, S_true):
"""Calculate best correlation match for each source."""
n_est = S_est.shape[0]
n_true = S_true.shape[0]
corr = np.zeros((n_est, n_true))
for i in range(n_est):
for j in range(n_true):
corr[i, j] = np.abs(np.corrcoef(S_est[i], S_true[j])[0, 1])
return corr
print("\n--- Evaluation ---")
corr_tanh = match_sources(S_dss_tanh, S_true)
corr_kurt = match_sources(S_dss_kurt, S_true)
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
im0 = axes[0].imshow(corr_tanh, vmin=0, vmax=1, cmap="Greens")
axes[0].set_title(
f"DSS (Tanh) Match\nMean Max Corr: {np.mean(np.max(corr_tanh, axis=1)):.3f}"
)
axes[0].set_ylabel("Recovered")
axes[0].set_xlabel("True")
plt.colorbar(im0, ax=axes[0])
im1 = axes[1].imshow(corr_kurt, vmin=0, vmax=1, cmap="Blues")
axes[1].set_title(
f"DSS (Kurtosis) Match\nMean Max Corr: {np.mean(np.max(corr_kurt, axis=1)):.3f}"
)
axes[1].set_xlabel("True")
plt.colorbar(im1, ax=axes[1])
corr_ica = match_sources(S_fastica, S_true)
im2 = axes[2].imshow(corr_ica, vmin=0, vmax=1, cmap="Oranges")
axes[2].set_title(
f"sklearn FastICA Match\nMean Max Corr: {np.mean(np.max(corr_ica, axis=1)):.3f}"
)
axes[2].set_xlabel("True")
plt.colorbar(im2, ax=axes[2])
plt.suptitle("Source Recovery Quality (Abs Correlation)")
plt.tight_layout()
plt.show()
# Plot recovered time series using viz module
print("Visualizing Recovered Sources (Stacked)...")
# We treat the sources as "components" of the estimator
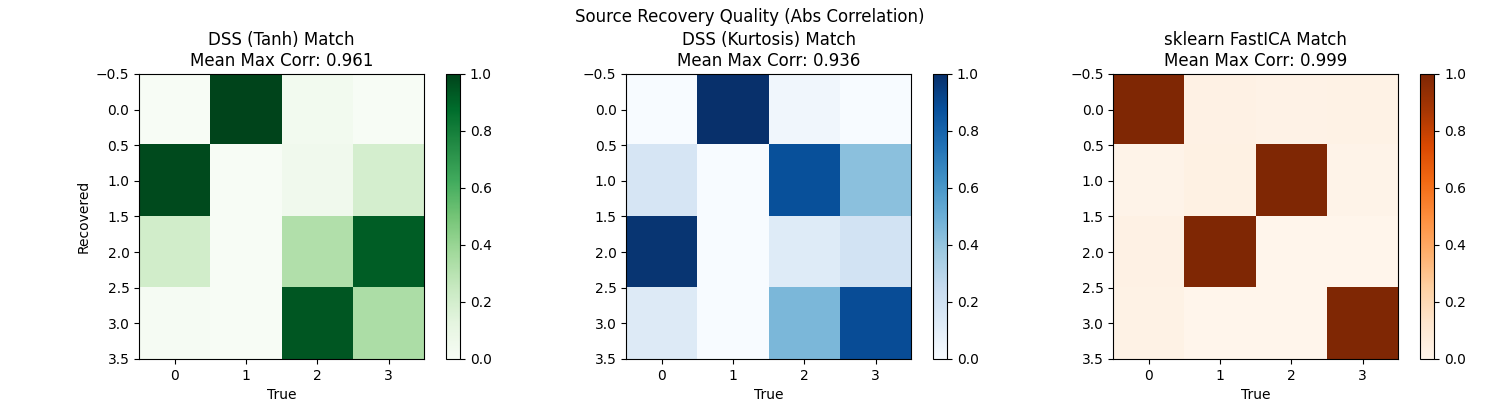
--- Evaluation ---
Visualizing Recovered Sources (Stacked)...
Recovered Source Time Series#
plot_component_time_series(dss_tanh, data=X, show=False)
plt.gcf().suptitle("Recovered Sources (DSS Tanh) - Newton Optimization")
plt.show()
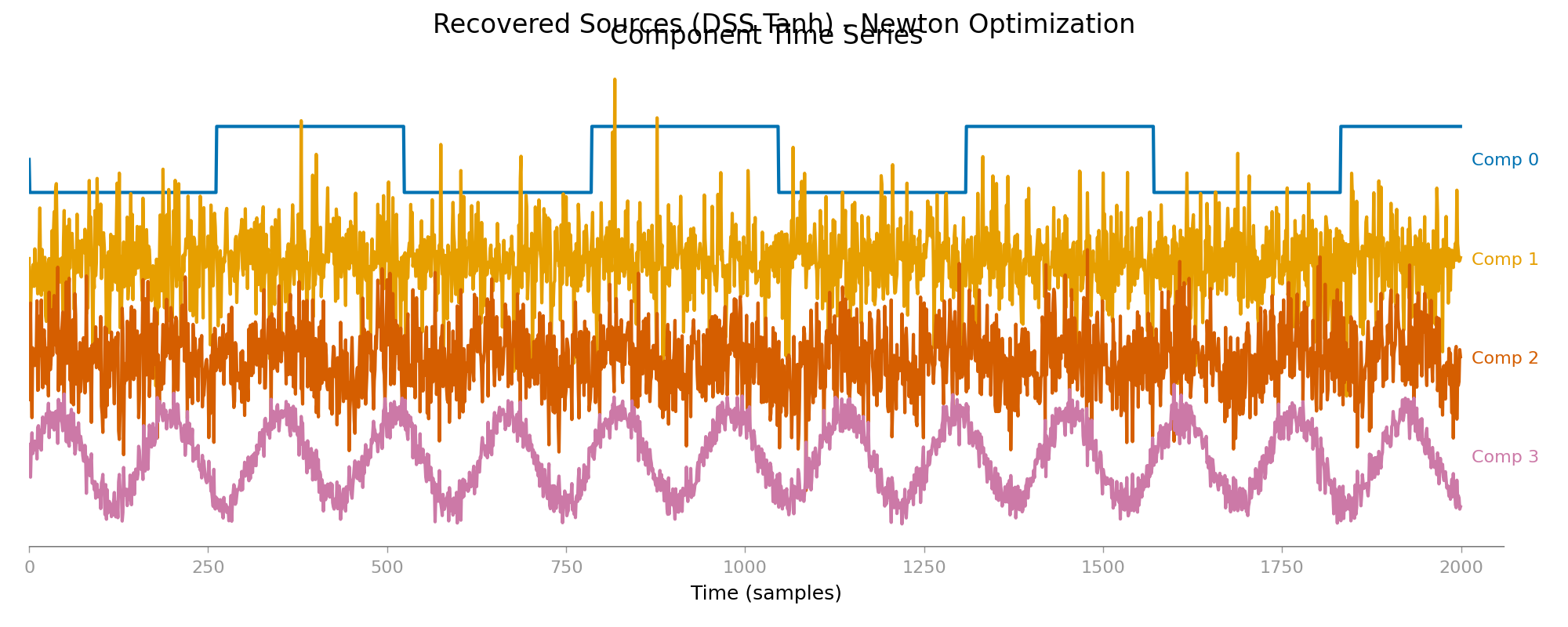
Part 2: Blind Separation of Real MEG Data#
We apply nonlinear DSS to the MNE sample dataset (MEG channels) to blindly extract artifacts (EOG, ECG) and brain sources. This is similar to running mne.preprocessing.ICA.
print("\n--- 2. Real MEG Data (Blind Separation) ---")
data_path = sample.data_path()
raw_fname = data_path / "MEG" / "sample" / "sample_audvis_raw.fif"
raw = mne.io.read_raw_fif(
raw_fname, verbose=False
) # list_url=[] prevents download print spam usually
raw.crop(0, 60).pick_types(meg="grad", eeg=False, eog=True, stim=False).load_data()
# Filter to remove drifts and high freq noise
raw.filter(1, 40, verbose=False)
# Prepare MEG-only data for BSS
# We want to find artifacts *in the MEG channels*, ensuring we
# don't just pick up the EOG channel itself.
raw_meg = raw.copy().pick_types(meg="grad", eeg=False, eog=False, stim=False)
print(f"Data shape (MEG only): {raw_meg.get_data().shape}")
# Fit DSS-Tanh (Blind Decomposition)
print("Fitting Blind DSS (this may take a moment)...")
n_components = 15
dss_meg = IterativeDSS(
denoiser=TanhMaskDenoiser(),
method="deflation",
n_components=n_components,
beta=beta_tanh,
verbose=True,
)
dss_meg.fit(raw_meg)
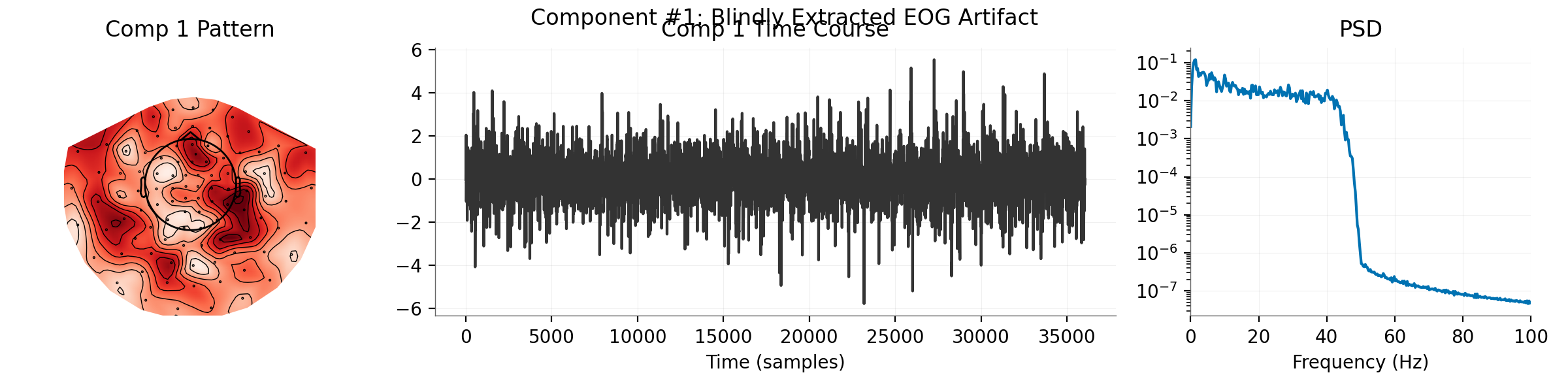
# Identify Artifacts by correlation with EOG channel
# We use the separate EOG channel to validate which extracted
# source corresponds to blinks.
eog_ch = raw.get_data(picks="eog")[0]
sources = dss_meg.transform(raw_meg)
corrs = [np.abs(np.corrcoef(s, eog_ch)[0, 1]) for s in sources]
blink_idx = np.argmax(corrs)
print(f"\nMost likely EOG component: #{blink_idx} (Corr: {corrs[blink_idx]:.3f})")
# Visualize the Blink Component
print("Visualizing Blink Component...")
plot_component_summary(
dss_meg,
data=raw_meg,
info=raw_meg.info,
picks=mne.pick_types(raw_meg.info, meg="grad", eeg=False, eog=False, stim=False),
n_components=[blink_idx],
show=False,
)
plt.gcf().suptitle(f"Component #{blink_idx}: Blindly Extracted EOG Artifact")
plt.show()
# Visualize a Brain Component (candidate)
# We look for a component that is NOT the blink argmax
candidate_indices = [i for i in range(n_components) if i != blink_idx]
brain_idx = candidate_indices[1] # Pick arbitrary one, e.g. 2nd candidate
print(f"Visualizing Candidate Brain Component #{brain_idx}...")
--- 2. Real MEG Data (Blind Separation) ---
NOTE: pick_types() is a legacy function. New code should use inst.pick(...).
Reading 0 ... 36037 = 0.000 ... 60.000 secs...
NOTE: pick_types() is a legacy function. New code should use inst.pick(...).
Data shape (MEG only): (203, 36038)
Fitting Blind DSS (this may take a moment)...
Component 1: 9 iterations (converged)
Component 2: 9 iterations (converged)
Component 3: 8 iterations (converged)
Component 4: 7 iterations (converged)
Component 5: 8 iterations (converged)
Component 6: 8 iterations (converged)
Component 7: 55 iterations (converged)
Component 8: 48 iterations (converged)
Component 9: 9 iterations (converged)
Component 10: 24 iterations (converged)
Component 11: 75 iterations (converged)
Component 12: 8 iterations (converged)
Component 13: 8 iterations (converged)
Component 14: 8 iterations (converged)
Component 15: 8 iterations (converged)
Most likely EOG component: #0 (Corr: 0.834)
Visualizing Blink Component...
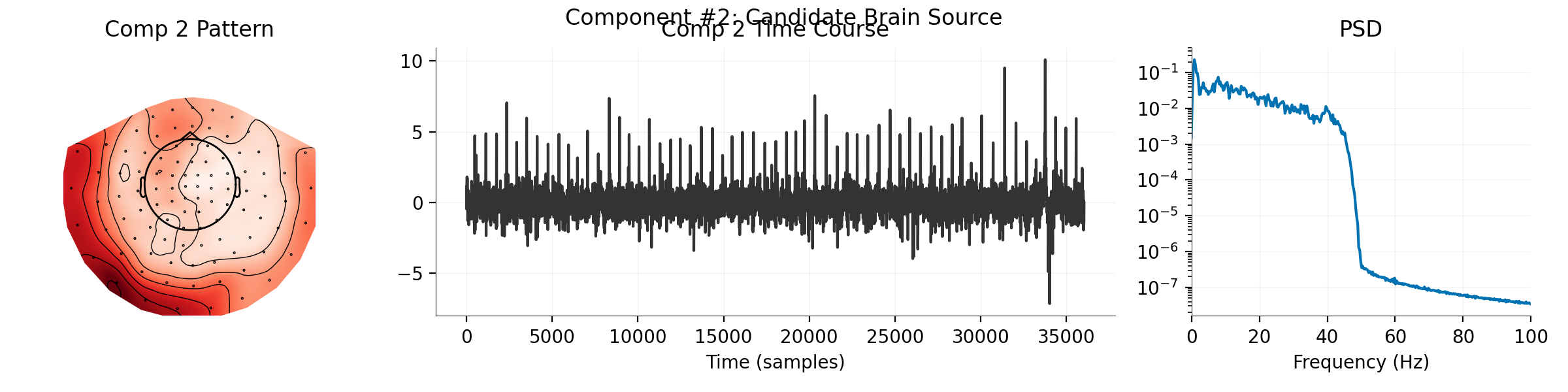
Visualizing Candidate Brain Component #2...
Candidate Brain Component#
plot_component_summary(
dss_meg,
data=raw_meg,
info=raw_meg.info,
picks=mne.pick_types(raw_meg.info, meg="grad", eeg=False, eog=False, stim=False),
n_components=[brain_idx],
show=False,
)
plt.gcf().suptitle(f"Component #{brain_idx}: Candidate Brain Source")
plt.show()
# Overlay comparison for EOG
# Show how the extracted component matches the EOG channel
eog_raw = mne.io.RawArray(
eog_ch[None, :], mne.create_info(["EOG"], raw.info["sfreq"], "eog")
)
comp_raw = mne.io.RawArray(
sources[blink_idx : blink_idx + 1], mne.create_info(1, raw.info["sfreq"], "misc")
)
Creating RawArray with float64 data, n_channels=1, n_times=36038
Range : 0 ... 36037 = 0.000 ... 60.000 secs
Ready.
Creating RawArray with float64 data, n_channels=1, n_times=36038
Range : 0 ... 36037 = 0.000 ... 60.000 secs
Ready.
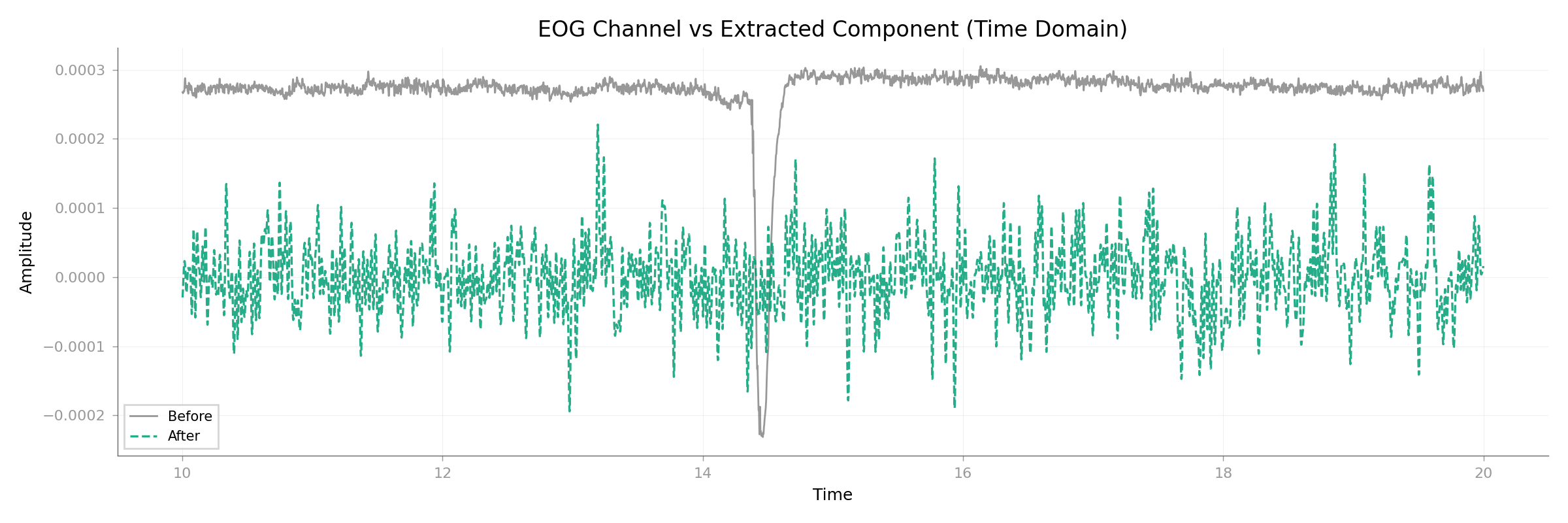
EOG Overlay#
plot_signal_overlay(
eog_raw,
comp_raw,
times=eog_raw.times,
start=10,
stop=20,
title="EOG Channel vs Extracted Component (Time Domain)",
show=False,
)
plt.show()
print("\nBlind Source Separation complete!")
Blind Source Separation complete!
Total running time of the script: (0 minutes 4.197 seconds)