Note
Go to the end to download the full example code.
Repeated measures ANOVA on source data with spatio-temporal clustering#
This example illustrates how to make use of the clustering functions for arbitrary, self-defined contrasts beyond standard t-tests. In this case we will tests if the differences in evoked responses between stimulation modality (visual VS auditory) depend on the stimulus location (left vs right) for a group of subjects (simulated here using one subject’s data). For this purpose we will compute an interaction effect using a repeated measures ANOVA. The multiple comparisons problem is addressed with a cluster-level permutation test across space and time.
# Authors: Alexandre Gramfort <alexandre.gramfort@inria.fr>
# Eric Larson <larson.eric.d@gmail.com>
# Denis Engemannn <denis.engemann@gmail.com>
#
# License: BSD-3-Clause
# Copyright the MNE-Python contributors.
import matplotlib.pyplot as plt
import numpy as np
from numpy.random import randn
import mne
from mne.datasets import sample
from mne.minimum_norm import apply_inverse, read_inverse_operator
from mne.stats import (
f_mway_rm,
f_threshold_mway_rm,
spatio_temporal_cluster_test,
summarize_clusters_stc,
)
print(__doc__)
Set parameters#
data_path = sample.data_path()
meg_path = data_path / "MEG" / "sample"
raw_fname = meg_path / "sample_audvis_filt-0-40_raw.fif"
event_fname = meg_path / "sample_audvis_filt-0-40_raw-eve.fif"
subjects_dir = data_path / "subjects"
src_fname = subjects_dir / "fsaverage" / "bem" / "fsaverage-ico-5-src.fif"
tmin = -0.2
tmax = 0.3 # Use a lower tmax to reduce multiple comparisons
# Setup for reading the raw data
raw = mne.io.read_raw_fif(raw_fname)
events = mne.read_events(event_fname)
Opening raw data file /home/circleci/mne_data/MNE-sample-data/MEG/sample/sample_audvis_filt-0-40_raw.fif...
Read a total of 4 projection items:
PCA-v1 (1 x 102) idle
PCA-v2 (1 x 102) idle
PCA-v3 (1 x 102) idle
Average EEG reference (1 x 60) idle
Range : 6450 ... 48149 = 42.956 ... 320.665 secs
Ready.
Read epochs for all channels, removing a bad one#
raw.info["bads"] += ["MEG 2443"]
picks = mne.pick_types(raw.info, meg=True, eog=True, exclude="bads")
# we'll load all four conditions that make up the 'two ways' of our ANOVA
event_id = dict(l_aud=1, r_aud=2, l_vis=3, r_vis=4)
reject = dict(grad=1000e-13, mag=4000e-15, eog=150e-6)
epochs = mne.Epochs(
raw,
events,
event_id,
tmin,
tmax,
picks=picks,
baseline=(None, 0),
reject=reject,
preload=True,
)
# Equalize trial counts to eliminate bias (which would otherwise be
# introduced by the abs() performed below)
epochs.equalize_event_counts(event_id)
Not setting metadata
288 matching events found
Setting baseline interval to [-0.19979521315838786, 0.0] s
Applying baseline correction (mode: mean)
Created an SSP operator (subspace dimension = 3)
3 projection items activated
Loading data for 288 events and 76 original time points ...
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on MAG : ['MEG 1711']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on GRAD : ['MEG 1333', 'MEG 1342']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
33 bad epochs dropped
Dropped 15 epochs: 0, 13, 14, 32, 33, 35, 52, 151, 166, 168, 198, 199, 200, 201, 222
Transform to source space#
fname_inv = meg_path / "sample_audvis-meg-oct-6-meg-inv.fif"
snr = 3.0
lambda2 = 1.0 / snr**2
method = "dSPM" # use dSPM method (could also be MNE, sLORETA, or eLORETA)
inverse_operator = read_inverse_operator(fname_inv)
# we'll only use one hemisphere to speed up this example
# instead of a second vertex array we'll pass an empty array
sample_vertices = [inverse_operator["src"][0]["vertno"], np.array([], int)]
# Let's average and compute inverse, then resample to speed things up
conditions = []
for cond in ["l_aud", "r_aud", "l_vis", "r_vis"]: # order is important
evoked = epochs[cond].average()
evoked.resample(30).crop(0.0, None)
condition = apply_inverse(evoked, inverse_operator, lambda2, method)
# Let's only deal with t > 0, cropping to reduce multiple comparisons
condition.crop(0, None)
conditions.append(condition)
tmin = conditions[0].tmin
tstep = conditions[0].tstep * 1000 # convert to milliseconds
Reading inverse operator decomposition from /home/circleci/mne_data/MNE-sample-data/MEG/sample/sample_audvis-meg-oct-6-meg-inv.fif...
Reading inverse operator info...
[done]
Reading inverse operator decomposition...
[done]
305 x 305 full covariance (kind = 1) found.
Read a total of 4 projection items:
PCA-v1 (1 x 102) active
PCA-v2 (1 x 102) active
PCA-v3 (1 x 102) active
Average EEG reference (1 x 60) active
Noise covariance matrix read.
22494 x 22494 diagonal covariance (kind = 2) found.
Source covariance matrix read.
22494 x 22494 diagonal covariance (kind = 6) found.
Orientation priors read.
22494 x 22494 diagonal covariance (kind = 5) found.
Depth priors read.
Did not find the desired covariance matrix (kind = 3)
Reading a source space...
Computing patch statistics...
Patch information added...
Distance information added...
[done]
Reading a source space...
Computing patch statistics...
Patch information added...
Distance information added...
[done]
2 source spaces read
Read a total of 4 projection items:
PCA-v1 (1 x 102) active
PCA-v2 (1 x 102) active
PCA-v3 (1 x 102) active
Average EEG reference (1 x 60) active
Source spaces transformed to the inverse solution coordinate frame
Preparing the inverse operator for use...
Scaled noise and source covariance from nave = 1 to nave = 60
Created the regularized inverter
Created an SSP operator (subspace dimension = 3)
Created the whitener using a noise covariance matrix with rank 302 (3 small eigenvalues omitted)
Computing noise-normalization factors (dSPM)...
[done]
Applying inverse operator to "l_aud"...
Picked 305 channels from the data
Computing inverse...
Eigenleads need to be weighted ...
Computing residual...
Explained 74.9% variance
Combining the current components...
dSPM...
[done]
Preparing the inverse operator for use...
Scaled noise and source covariance from nave = 1 to nave = 60
Created the regularized inverter
Created an SSP operator (subspace dimension = 3)
Created the whitener using a noise covariance matrix with rank 302 (3 small eigenvalues omitted)
Computing noise-normalization factors (dSPM)...
[done]
Applying inverse operator to "r_aud"...
Picked 305 channels from the data
Computing inverse...
Eigenleads need to be weighted ...
Computing residual...
Explained 71.6% variance
Combining the current components...
dSPM...
[done]
Preparing the inverse operator for use...
Scaled noise and source covariance from nave = 1 to nave = 60
Created the regularized inverter
Created an SSP operator (subspace dimension = 3)
Created the whitener using a noise covariance matrix with rank 302 (3 small eigenvalues omitted)
Computing noise-normalization factors (dSPM)...
[done]
Applying inverse operator to "l_vis"...
Picked 305 channels from the data
Computing inverse...
Eigenleads need to be weighted ...
Computing residual...
Explained 74.5% variance
Combining the current components...
dSPM...
[done]
Preparing the inverse operator for use...
Scaled noise and source covariance from nave = 1 to nave = 60
Created the regularized inverter
Created an SSP operator (subspace dimension = 3)
Created the whitener using a noise covariance matrix with rank 302 (3 small eigenvalues omitted)
Computing noise-normalization factors (dSPM)...
[done]
Applying inverse operator to "r_vis"...
Picked 305 channels from the data
Computing inverse...
Eigenleads need to be weighted ...
Computing residual...
Explained 78.9% variance
Combining the current components...
dSPM...
[done]
Transform to common cortical space#
Normally you would read in estimates across several subjects and morph them to the same cortical space (e.g. fsaverage). For example purposes, we will simulate this by just having each “subject” have the same response (just noisy in source space) here.
We’ll only consider the left hemisphere in this tutorial.
n_vertices_sample, n_times = conditions[0].lh_data.shape
n_subjects = 6
print(f"Simulating data for {n_subjects} subjects.")
# Let's make sure our results replicate, so set the seed.
np.random.seed(0)
X = randn(n_vertices_sample, n_times, n_subjects, 4) * 10
for ii, condition in enumerate(conditions):
X[:, :, :, ii] += condition.lh_data[:, :, np.newaxis]
Simulating data for 6 subjects.
It’s a good idea to spatially smooth the data, and for visualization purposes, let’s morph these to fsaverage, which is a grade 5 ICO source space with vertices 0:10242 for each hemisphere. Usually you’d have to morph each subject’s data separately, but here since all estimates are on ‘sample’ we can use one morph matrix for all the heavy lifting.
# Read the source space we are morphing to (just left hemisphere)
src = mne.read_source_spaces(src_fname)
fsave_vertices = [src[0]["vertno"], []]
morph_mat = mne.compute_source_morph(
src=inverse_operator["src"],
subject_to="fsaverage",
spacing=fsave_vertices,
subjects_dir=subjects_dir,
smooth=20,
).morph_mat
morph_mat = morph_mat[:, :n_vertices_sample] # just left hemi from src
n_vertices_fsave = morph_mat.shape[0]
# We have to change the shape for the dot() to work properly
X = X.reshape(n_vertices_sample, n_times * n_subjects * 4)
print("Morphing data.")
X = morph_mat.dot(X) # morph_mat is a sparse matrix
X = X.reshape(n_vertices_fsave, n_times, n_subjects, 4)
Reading a source space...
[done]
Reading a source space...
[done]
2 source spaces read
surface source space present ...
Computing morph matrix...
Left-hemisphere map read.
Right-hemisphere map read.
20 smooth iterations done.
20 smooth iterations done.
[done]
[done]
Morphing data.
Now we need to prepare the group matrix for the ANOVA statistic. To make the clustering function work correctly with the ANOVA function X needs to be a list of multi-dimensional arrays (one per condition) of shape: samples (subjects) × time × space.
First we permute dimensions, then split the array into a list of conditions and discard the empty dimension resulting from the split using numpy squeeze.
X = np.transpose(X, [2, 1, 0, 3]) #
X = [np.squeeze(x) for x in np.split(X, 4, axis=-1)]
Prepare function for arbitrary contrast#
As our ANOVA function is a multi-purpose tool we need to apply a few modifications to integrate it with the clustering function. This includes reshaping data, setting default arguments and processing the return values. For this reason we’ll write a tiny dummy function.
We will tell the ANOVA how to interpret the data matrix in terms of factors. This is done via the factor levels argument which is a list of the number factor levels for each factor.
factor_levels = [2, 2]
Finally we will pick the interaction effect by passing ‘A:B’.
(this notation is borrowed from the R formula language).
As an aside, note that in this particular example, we cannot use the A*B
notation which return both the main and the interaction effect. The reason
is that the clustering function expects stat_fun to return a 1-D array.
To get clusters for both, you must create a loop.
effects = "A:B"
# Tell the ANOVA not to compute p-values which we don't need for clustering
return_pvals = False
# a few more convenient bindings
n_times = X[0].shape[1]
n_conditions = 4
A stat_fun must deal with a variable number of input arguments.
Inside the clustering function each condition will be passed as flattened array, necessitated by the clustering procedure. The ANOVA however expects an input array of dimensions: subjects × conditions × observations (optional).
The following function catches the list input and swaps the first and the second dimension, and finally calls ANOVA.
Note
For further details on this ANOVA function consider the corresponding time-frequency tutorial.
def stat_fun(*args):
# get f-values only.
return f_mway_rm(
np.swapaxes(args, 1, 0),
factor_levels=factor_levels,
effects=effects,
return_pvals=return_pvals,
)[0]
Compute clustering statistic#
To use an algorithm optimized for spatio-temporal clustering, we just pass the spatial adjacency matrix (instead of spatio-temporal).
# as we only have one hemisphere we need only need half the adjacency
print("Computing adjacency.")
adjacency = mne.spatial_src_adjacency(src[:1])
# Now let's actually do the clustering. Please relax, on a small
# notebook and one single thread only this will take a couple of minutes ...
pthresh = 0.005
f_thresh = f_threshold_mway_rm(n_subjects, factor_levels, effects, pthresh)
# To speed things up a bit we will ...
n_permutations = 50 # ... run way fewer permutations (reduces sensitivity)
print("Clustering.")
F_obs, clusters, cluster_p_values, H0 = clu = spatio_temporal_cluster_test(
X,
adjacency=adjacency,
n_jobs=None,
threshold=f_thresh,
stat_fun=stat_fun,
n_permutations=n_permutations,
buffer_size=None,
)
# Now select the clusters that are sig. at p < 0.05 (note that this value
# is multiple-comparisons corrected).
good_cluster_inds = np.where(cluster_p_values < 0.05)[0]
Computing adjacency.
-- number of adjacent vertices : 10242
Clustering.
stat_fun(H1): min=1.9303783368756912e-10 max=1782.8512814494816
Running initial clustering …
Found 444 clusters
0%| | Permuting : 0/49 [00:00<?, ?it/s]
2%|▏ | Permuting : 1/49 [00:00<00:04, 9.93it/s]
4%|▍ | Permuting : 2/49 [00:00<00:03, 11.98it/s]
6%|▌ | Permuting : 3/49 [00:00<00:04, 11.17it/s]
8%|▊ | Permuting : 4/49 [00:00<00:03, 11.81it/s]
10%|█ | Permuting : 5/49 [00:00<00:03, 11.30it/s]
12%|█▏ | Permuting : 6/49 [00:00<00:03, 10.96it/s]
14%|█▍ | Permuting : 7/49 [00:00<00:03, 10.67it/s]
16%|█▋ | Permuting : 8/49 [00:00<00:03, 10.56it/s]
18%|█▊ | Permuting : 9/49 [00:00<00:03, 10.99it/s]
20%|██ | Permuting : 10/49 [00:00<00:03, 10.85it/s]
22%|██▏ | Permuting : 11/49 [00:00<00:03, 11.20it/s]
24%|██▍ | Permuting : 12/49 [00:01<00:03, 11.05it/s]
27%|██▋ | Permuting : 13/49 [00:01<00:03, 11.35it/s]
29%|██▊ | Permuting : 14/49 [00:01<00:03, 11.19it/s]
31%|███ | Permuting : 15/49 [00:01<00:02, 11.46it/s]
33%|███▎ | Permuting : 16/49 [00:01<00:02, 11.70it/s]
35%|███▍ | Permuting : 17/49 [00:01<00:02, 11.51it/s]
37%|███▋ | Permuting : 18/49 [00:01<00:02, 10.94it/s]
39%|███▉ | Permuting : 19/49 [00:01<00:02, 10.25it/s]
41%|████ | Permuting : 20/49 [00:01<00:02, 9.96it/s]
43%|████▎ | Permuting : 21/49 [00:02<00:02, 9.48it/s]
45%|████▍ | Permuting : 22/49 [00:02<00:02, 9.29it/s]
47%|████▋ | Permuting : 23/49 [00:02<00:02, 8.93it/s]
49%|████▉ | Permuting : 24/49 [00:02<00:02, 8.80it/s]
51%|█████ | Permuting : 25/49 [00:02<00:02, 8.52it/s]
53%|█████▎ | Permuting : 26/49 [00:02<00:02, 8.43it/s]
55%|█████▌ | Permuting : 27/49 [00:03<00:02, 8.21it/s]
57%|█████▋ | Permuting : 28/49 [00:03<00:02, 8.15it/s]
59%|█████▉ | Permuting : 29/49 [00:03<00:02, 8.10it/s]
61%|██████ | Permuting : 30/49 [00:03<00:02, 8.06it/s]
63%|██████▎ | Permuting : 31/49 [00:03<00:02, 8.01it/s]
65%|██████▌ | Permuting : 32/49 [00:03<00:02, 7.98it/s]
67%|██████▋ | Permuting : 33/49 [00:03<00:02, 7.94it/s]
69%|██████▉ | Permuting : 34/49 [00:03<00:01, 7.76it/s]
71%|███████▏ | Permuting : 35/49 [00:04<00:01, 7.70it/s]
73%|███████▎ | Permuting : 36/49 [00:04<00:01, 7.68it/s]
76%|███████▌ | Permuting : 37/49 [00:04<00:01, 7.67it/s]
78%|███████▊ | Permuting : 38/49 [00:04<00:01, 7.65it/s]
80%|███████▉ | Permuting : 39/49 [00:04<00:01, 7.64it/s]
82%|████████▏ | Permuting : 40/49 [00:04<00:01, 7.63it/s]
84%|████████▎ | Permuting : 41/49 [00:04<00:01, 7.62it/s]
86%|████████▌ | Permuting : 42/49 [00:05<00:00, 7.83it/s]
88%|████████▊ | Permuting : 43/49 [00:05<00:00, 7.93it/s]
90%|████████▉ | Permuting : 44/49 [00:05<00:00, 8.14it/s]
92%|█████████▏| Permuting : 45/49 [00:05<00:00, 8.22it/s]
94%|█████████▍| Permuting : 46/49 [00:05<00:00, 8.43it/s]
96%|█████████▌| Permuting : 47/49 [00:05<00:00, 8.63it/s]
98%|█████████▊| Permuting : 48/49 [00:05<00:00, 8.69it/s]
100%|██████████| Permuting : 49/49 [00:05<00:00, 8.96it/s]
100%|██████████| Permuting : 49/49 [00:05<00:00, 8.80it/s]
Visualize the clusters#
print("Visualizing clusters.")
# Now let's build a convenient representation of each cluster, where each
# cluster becomes a "time point" in the SourceEstimate
stc_all_cluster_vis = summarize_clusters_stc(
clu, tstep=tstep, vertices=fsave_vertices, subject="fsaverage"
)
# Let's actually plot the first "time point" in the SourceEstimate, which
# shows all the clusters, weighted by duration
subjects_dir = data_path / "subjects"
# The brighter the color, the stronger the interaction between
# stimulus modality and stimulus location
brain = stc_all_cluster_vis.plot(
subjects_dir=subjects_dir,
views="lat",
time_label="temporal extent (ms)",
clim=dict(kind="value", lims=[0, 1, 40]),
)
brain.save_image("cluster-lh.png")
brain.show_view("medial")
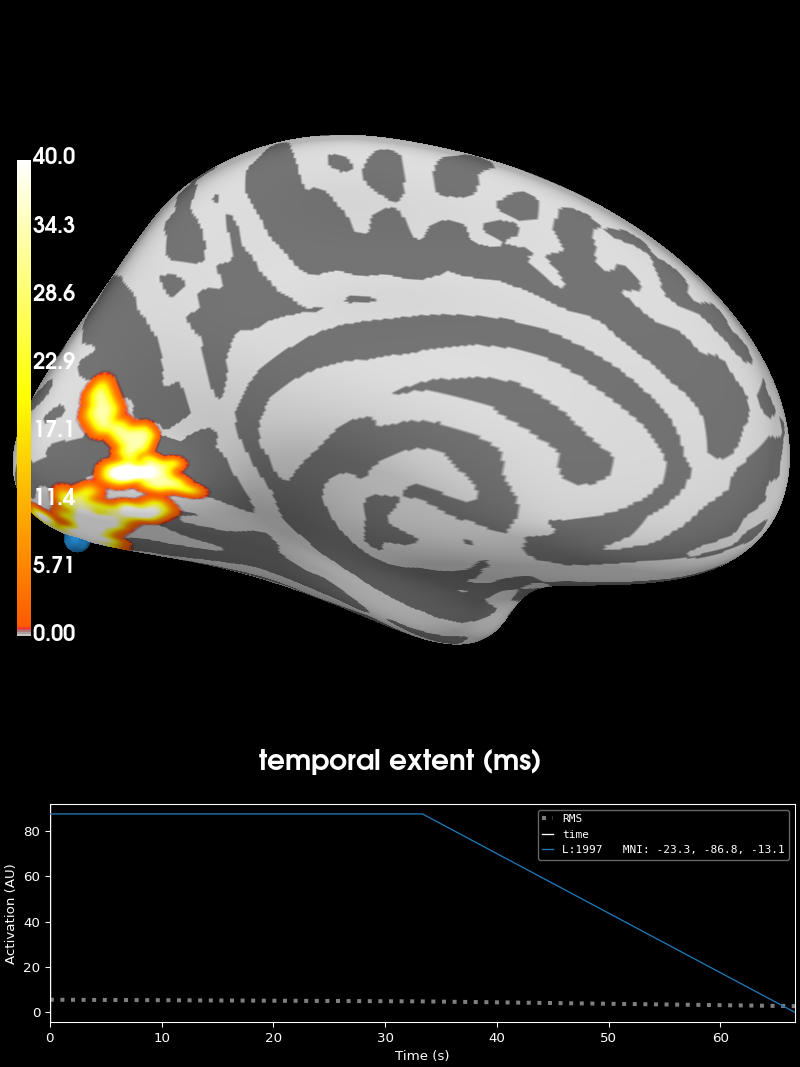
Visualizing clusters.
Finally, let’s investigate interaction effect by reconstructing the time courses:
inds_t, inds_v = [
(clusters[cluster_ind]) for ii, cluster_ind in enumerate(good_cluster_inds)
][0] # first cluster
times = np.arange(X[0].shape[1]) * tstep * 1e3
plt.figure()
colors = ["y", "b", "g", "purple"]
event_ids = ["l_aud", "r_aud", "l_vis", "r_vis"]
for ii, (condition, color, eve_id) in enumerate(zip(X, colors, event_ids)):
# extract time course at cluster vertices
condition = condition[:, :, inds_v]
# normally we would normalize values across subjects but
# here we use data from the same subject so we're good to just
# create average time series across subjects and vertices.
mean_tc = condition.mean(axis=2).mean(axis=0)
std_tc = condition.std(axis=2).std(axis=0)
plt.plot(times, mean_tc.T, color=color, label=eve_id)
plt.fill_between(
times, mean_tc + std_tc, mean_tc - std_tc, color="gray", alpha=0.5, label=""
)
ymin, ymax = mean_tc.min() - 5, mean_tc.max() + 5
plt.xlabel("Time (ms)")
plt.ylabel("Activation (F-values)")
plt.xlim(times[[0, -1]])
plt.ylim(ymin, ymax)
plt.fill_betweenx(
(ymin, ymax), times[inds_t[0]], times[inds_t[-1]], color="orange", alpha=0.3
)
plt.legend()
plt.title("Interaction between stimulus-modality and location.")
plt.show()
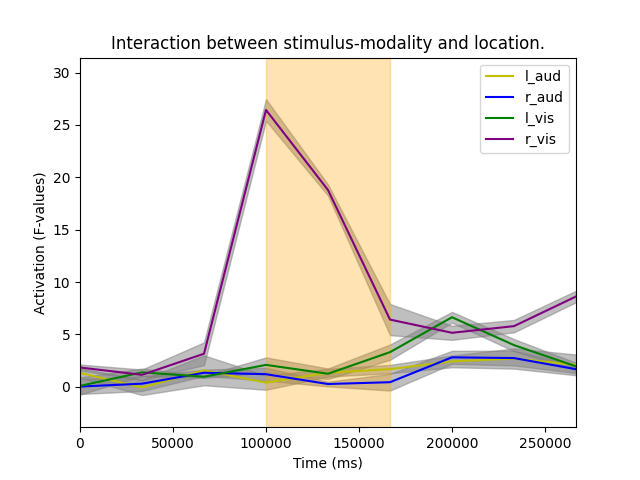
Total running time of the script: (0 minutes 14.109 seconds)