Note
Click here to download the full example code
Decoding sensor space data with generalization across time and conditions#
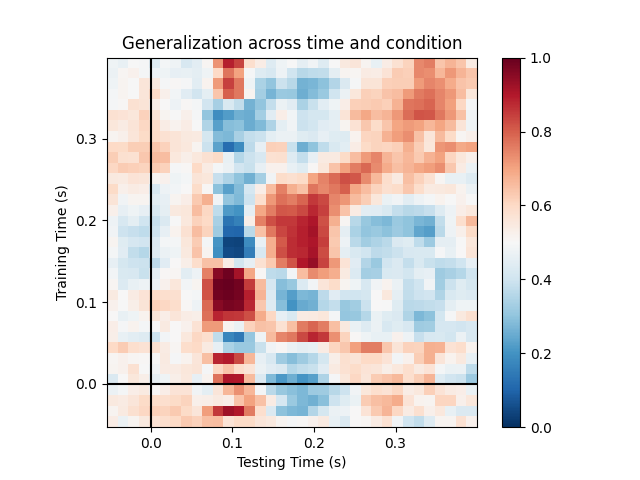
This example runs the analysis described in 1. It illustrates how one can fit a linear classifier to identify a discriminatory topography at a given time instant and subsequently assess whether this linear model can accurately predict all of the time samples of a second set of conditions.
# Authors: Jean-Remi King <jeanremi.king@gmail.com>
# Alexandre Gramfort <alexandre.gramfort@inria.fr>
# Denis Engemann <denis.engemann@gmail.com>
#
# License: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import mne
from mne.datasets import sample
from mne.decoding import GeneralizingEstimator
print(__doc__)
# Preprocess data
data_path = sample.data_path()
# Load and filter data, set up epochs
meg_path = data_path / 'MEG' / 'sample'
raw_fname = meg_path / 'sample_audvis_filt-0-40_raw.fif'
events_fname = meg_path / 'sample_audvis_filt-0-40_raw-eve.fif'
raw = mne.io.read_raw_fif(raw_fname, preload=True)
picks = mne.pick_types(raw.info, meg=True, exclude='bads') # Pick MEG channels
raw.filter(1., 30., fir_design='firwin') # Band pass filtering signals
events = mne.read_events(events_fname)
event_id = {'Auditory/Left': 1, 'Auditory/Right': 2,
'Visual/Left': 3, 'Visual/Right': 4}
tmin = -0.050
tmax = 0.400
# decimate to make the example faster to run, but then use verbose='error' in
# the Epochs constructor to suppress warning about decimation causing aliasing
decim = 2
epochs = mne.Epochs(raw, events, event_id=event_id, tmin=tmin, tmax=tmax,
proj=True, picks=picks, baseline=None, preload=True,
reject=dict(mag=5e-12), decim=decim, verbose='error')
Opening raw data file /home/circleci/mne_data/MNE-sample-data/MEG/sample/sample_audvis_filt-0-40_raw.fif...
Read a total of 4 projection items:
PCA-v1 (1 x 102) idle
PCA-v2 (1 x 102) idle
PCA-v3 (1 x 102) idle
Average EEG reference (1 x 60) idle
Range : 6450 ... 48149 = 42.956 ... 320.665 secs
Ready.
Reading 0 ... 41699 = 0.000 ... 277.709 secs...
Filtering raw data in 1 contiguous segment
Setting up band-pass filter from 1 - 30 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 1.00
- Lower transition bandwidth: 1.00 Hz (-6 dB cutoff frequency: 0.50 Hz)
- Upper passband edge: 30.00 Hz
- Upper transition bandwidth: 7.50 Hz (-6 dB cutoff frequency: 33.75 Hz)
- Filter length: 497 samples (3.310 sec)
We will train the classifier on all left visual vs auditory trials and test on all right visual vs auditory trials.
clf = make_pipeline(
StandardScaler(),
LogisticRegression(solver='liblinear') # liblinear is faster than lbfgs
)
time_gen = GeneralizingEstimator(clf, scoring='roc_auc', n_jobs=1,
verbose=True)
# Fit classifiers on the epochs where the stimulus was presented to the left.
# Note that the experimental condition y indicates auditory or visual
time_gen.fit(X=epochs['Left'].get_data(),
y=epochs['Left'].events[:, 2] > 2)
0%| | Fitting GeneralizingEstimator : 0/35 [00:00<?, ?it/s]
6%|5 | Fitting GeneralizingEstimator : 2/35 [00:00<00:00, 58.14it/s]
11%|#1 | Fitting GeneralizingEstimator : 4/35 [00:00<00:00, 58.64it/s]
17%|#7 | Fitting GeneralizingEstimator : 6/35 [00:00<00:00, 58.84it/s]
26%|##5 | Fitting GeneralizingEstimator : 9/35 [00:00<00:00, 66.88it/s]
34%|###4 | Fitting GeneralizingEstimator : 12/35 [00:00<00:00, 71.68it/s]
43%|####2 | Fitting GeneralizingEstimator : 15/35 [00:00<00:00, 74.87it/s]
51%|#####1 | Fitting GeneralizingEstimator : 18/35 [00:00<00:00, 77.16it/s]
60%|###### | Fitting GeneralizingEstimator : 21/35 [00:00<00:00, 78.89it/s]
69%|######8 | Fitting GeneralizingEstimator : 24/35 [00:00<00:00, 80.23it/s]
74%|#######4 | Fitting GeneralizingEstimator : 26/35 [00:00<00:00, 77.61it/s]
83%|########2 | Fitting GeneralizingEstimator : 29/35 [00:00<00:00, 78.87it/s]
89%|########8 | Fitting GeneralizingEstimator : 31/35 [00:00<00:00, 76.73it/s]
97%|#########7| Fitting GeneralizingEstimator : 34/35 [00:00<00:00, 77.97it/s]
100%|##########| Fitting GeneralizingEstimator : 35/35 [00:00<00:00, 78.39it/s]
Score on the epochs where the stimulus was presented to the right.
scores = time_gen.score(X=epochs['Right'].get_data(),
y=epochs['Right'].events[:, 2] > 2)
0%| | Scoring GeneralizingEstimator : 0/1225 [00:00<?, ?it/s]
1%|1 | Scoring GeneralizingEstimator : 15/1225 [00:00<00:02, 433.29it/s]
3%|2 | Scoring GeneralizingEstimator : 34/1225 [00:00<00:02, 497.41it/s]
4%|4 | Scoring GeneralizingEstimator : 54/1225 [00:00<00:02, 529.25it/s]
6%|6 | Scoring GeneralizingEstimator : 74/1225 [00:00<00:02, 545.55it/s]
8%|7 | Scoring GeneralizingEstimator : 94/1225 [00:00<00:02, 555.27it/s]
9%|9 | Scoring GeneralizingEstimator : 115/1225 [00:00<00:01, 567.17it/s]
11%|#1 | Scoring GeneralizingEstimator : 136/1225 [00:00<00:01, 575.82it/s]
13%|#2 | Scoring GeneralizingEstimator : 157/1225 [00:00<00:01, 582.38it/s]
14%|#4 | Scoring GeneralizingEstimator : 177/1225 [00:00<00:01, 583.47it/s]
16%|#6 | Scoring GeneralizingEstimator : 198/1225 [00:00<00:01, 587.42it/s]
18%|#7 | Scoring GeneralizingEstimator : 218/1225 [00:00<00:01, 587.80it/s]
19%|#9 | Scoring GeneralizingEstimator : 237/1225 [00:00<00:01, 584.96it/s]
21%|## | Scoring GeneralizingEstimator : 256/1225 [00:00<00:01, 582.31it/s]
23%|##2 | Scoring GeneralizingEstimator : 276/1225 [00:00<00:01, 583.18it/s]
24%|##4 | Scoring GeneralizingEstimator : 294/1225 [00:00<00:01, 578.36it/s]
26%|##5 | Scoring GeneralizingEstimator : 313/1225 [00:00<00:01, 576.44it/s]
27%|##7 | Scoring GeneralizingEstimator : 331/1225 [00:00<00:01, 572.64it/s]
29%|##8 | Scoring GeneralizingEstimator : 350/1225 [00:00<00:01, 571.80it/s]
30%|### | Scoring GeneralizingEstimator : 369/1225 [00:00<00:01, 570.98it/s]
32%|###1 | Scoring GeneralizingEstimator : 387/1225 [00:00<00:01, 567.87it/s]
33%|###3 | Scoring GeneralizingEstimator : 406/1225 [00:00<00:01, 567.39it/s]
35%|###4 | Scoring GeneralizingEstimator : 425/1225 [00:00<00:01, 566.67it/s]
36%|###6 | Scoring GeneralizingEstimator : 445/1225 [00:00<00:01, 568.49it/s]
38%|###7 | Scoring GeneralizingEstimator : 464/1225 [00:00<00:01, 567.97it/s]
39%|###9 | Scoring GeneralizingEstimator : 483/1225 [00:00<00:01, 567.32it/s]
41%|#### | Scoring GeneralizingEstimator : 501/1225 [00:00<00:01, 564.66it/s]
42%|####2 | Scoring GeneralizingEstimator : 520/1225 [00:00<00:01, 564.37it/s]
44%|####4 | Scoring GeneralizingEstimator : 539/1225 [00:00<00:01, 563.91it/s]
46%|####5 | Scoring GeneralizingEstimator : 560/1225 [00:00<00:01, 567.49it/s]
47%|####7 | Scoring GeneralizingEstimator : 580/1225 [00:01<00:01, 568.94it/s]
49%|####8 | Scoring GeneralizingEstimator : 600/1225 [00:01<00:01, 570.15it/s]
51%|##### | Scoring GeneralizingEstimator : 620/1225 [00:01<00:01, 571.10it/s]
52%|#####2 | Scoring GeneralizingEstimator : 641/1225 [00:01<00:01, 573.78it/s]
54%|#####3 | Scoring GeneralizingEstimator : 661/1225 [00:01<00:00, 574.88it/s]
56%|#####5 | Scoring GeneralizingEstimator : 682/1225 [00:01<00:00, 577.64it/s]
57%|#####7 | Scoring GeneralizingEstimator : 701/1225 [00:01<00:00, 576.72it/s]
59%|#####8 | Scoring GeneralizingEstimator : 720/1225 [00:01<00:00, 575.59it/s]
60%|###### | Scoring GeneralizingEstimator : 735/1225 [00:01<00:00, 567.73it/s]
62%|######1 | Scoring GeneralizingEstimator : 754/1225 [00:01<00:00, 567.21it/s]
63%|######3 | Scoring GeneralizingEstimator : 775/1225 [00:01<00:00, 570.32it/s]
65%|######4 | Scoring GeneralizingEstimator : 795/1225 [00:01<00:00, 571.52it/s]
67%|######6 | Scoring GeneralizingEstimator : 815/1225 [00:01<00:00, 572.63it/s]
68%|######8 | Scoring GeneralizingEstimator : 834/1225 [00:01<00:00, 571.98it/s]
70%|######9 | Scoring GeneralizingEstimator : 853/1225 [00:01<00:00, 571.14it/s]
71%|#######1 | Scoring GeneralizingEstimator : 875/1225 [00:01<00:00, 575.58it/s]
73%|#######3 | Scoring GeneralizingEstimator : 896/1225 [00:01<00:00, 577.94it/s]
75%|#######4 | Scoring GeneralizingEstimator : 917/1225 [00:01<00:00, 580.25it/s]
77%|#######6 | Scoring GeneralizingEstimator : 939/1225 [00:01<00:00, 584.01it/s]
78%|#######8 | Scoring GeneralizingEstimator : 960/1225 [00:01<00:00, 585.97it/s]
80%|######## | Scoring GeneralizingEstimator : 981/1225 [00:01<00:00, 587.88it/s]
82%|########1 | Scoring GeneralizingEstimator : 1000/1225 [00:01<00:00, 586.52it/s]
83%|########2 | Scoring GeneralizingEstimator : 1015/1225 [00:01<00:00, 578.90it/s]
84%|########4 | Scoring GeneralizingEstimator : 1032/1225 [00:01<00:00, 574.85it/s]
86%|########5 | Scoring GeneralizingEstimator : 1049/1225 [00:01<00:00, 570.97it/s]
87%|########7 | Scoring GeneralizingEstimator : 1068/1225 [00:01<00:00, 570.38it/s]
88%|########8 | Scoring GeneralizingEstimator : 1083/1225 [00:01<00:00, 563.62it/s]
90%|########9 | Scoring GeneralizingEstimator : 1102/1225 [00:01<00:00, 563.45it/s]
92%|#########1| Scoring GeneralizingEstimator : 1121/1225 [00:01<00:00, 563.30it/s]
93%|#########2| Scoring GeneralizingEstimator : 1136/1225 [00:02<00:00, 556.35it/s]
94%|#########4| Scoring GeneralizingEstimator : 1153/1225 [00:02<00:00, 553.28it/s]
96%|#########5| Scoring GeneralizingEstimator : 1171/1225 [00:02<00:00, 552.20it/s]
97%|#########7| Scoring GeneralizingEstimator : 1189/1225 [00:02<00:00, 550.84it/s]
98%|#########8| Scoring GeneralizingEstimator : 1206/1225 [00:02<00:00, 548.30it/s]
100%|#########9| Scoring GeneralizingEstimator : 1221/1225 [00:02<00:00, 541.79it/s]
100%|##########| Scoring GeneralizingEstimator : 1225/1225 [00:02<00:00, 561.38it/s]
Plot
fig, ax = plt.subplots(1)
im = ax.matshow(scores, vmin=0, vmax=1., cmap='RdBu_r', origin='lower',
extent=epochs.times[[0, -1, 0, -1]])
ax.axhline(0., color='k')
ax.axvline(0., color='k')
ax.xaxis.set_ticks_position('bottom')
ax.set_xlabel('Testing Time (s)')
ax.set_ylabel('Training Time (s)')
ax.set_title('Generalization across time and condition')
plt.colorbar(im, ax=ax)
plt.show()
References#
- 1
Jean-Rémi King and Stanislas Dehaene. Characterizing the dynamics of mental representations: the temporal generalization method. Trends in Cognitive Sciences, 18(4):203–210, 2014. doi:10.1016/j.tics.2014.01.002.
Total running time of the script: ( 0 minutes 7.112 seconds)
Estimated memory usage: 129 MB