mne.fit_dipole#
- mne.fit_dipole(evoked, cov, bem, trans=None, min_dist=5.0, n_jobs=None, pos=None, ori=None, rank=None, accuracy='normal', tol=5e-05, verbose=None)[source]#
Fit a dipole.
- Parameters:
- evokedinstance of
Evoked The dataset to fit.
- cov
str| instance ofCovariance The noise covariance.
- bem
str| instance ofConductorModel The BEM filename (str) or conductor model.
- trans
str|None The head<->MRI transform filename. Must be provided unless BEM is a sphere model.
- min_dist
float Minimum distance (in millimeters) from the dipole to the inner skull. Must be positive. Note that because this is a constraint passed to a solver it is not strict but close, i.e. for a
min_dist=5.the fits could be 4.9 mm from the inner skull.- n_jobs
int|None The number of jobs to run in parallel. If
-1, it is set to the number of CPU cores. Requires thejoblibpackage.None(default) is a marker for ‘unset’ that will be interpreted asn_jobs=1(sequential execution) unless the call is performed under ajoblib.parallel_backend()context manager that sets another value forn_jobs. It is used in field computation and fitting.- pos
ndarray, shape (3,) |None Position of the dipole to use. If None (default), sequential fitting (different position and orientation for each time instance) is performed. If a position (in head coords) is given as an array, the position is fixed during fitting.
New in version 0.12.
- ori
ndarray, shape (3,) |None Orientation of the dipole to use. If None (default), the orientation is free to change as a function of time. If an orientation (in head coordinates) is given as an array,
posmust also be provided, and the routine computes the amplitude and goodness of fit of the dipole at the given position and orientation for each time instant.New in version 0.12.
- rank
None| ‘info’ | ‘full’ |dict This controls the rank computation that can be read from the measurement info or estimated from the data. When a noise covariance is used for whitening, this should reflect the rank of that covariance, otherwise amplification of noise components can occur in whitening (e.g., often during source localization).
NoneThe rank will be estimated from the data after proper scaling of different channel types.
'info'The rank is inferred from
info. If data have been processed with Maxwell filtering, the Maxwell filtering header is used. Otherwise, the channel counts themselves are used. In both cases, the number of projectors is subtracted from the (effective) number of channels in the data. For example, if Maxwell filtering reduces the rank to 68, with two projectors the returned value will be 66.'full'The rank is assumed to be full, i.e. equal to the number of good channels. If a
Covarianceis passed, this can make sense if it has been (possibly improperly) regularized without taking into account the true data rank.dictCalculate the rank only for a subset of channel types, and explicitly specify the rank for the remaining channel types. This can be extremely useful if you already know the rank of (part of) your data, for instance in case you have calculated it earlier.
This parameter must be a dictionary whose keys correspond to channel types in the data (e.g.
'meg','mag','grad','eeg'), and whose values are integers representing the respective ranks. For example,{'mag': 90, 'eeg': 45}will assume a rank of90and45for magnetometer data and EEG data, respectively.The ranks for all channel types present in the data, but not specified in the dictionary will be estimated empirically. That is, if you passed a dataset containing magnetometer, gradiometer, and EEG data together with the dictionary from the previous example, only the gradiometer rank would be determined, while the specified magnetometer and EEG ranks would be taken for granted.
The default is
None.New in version 0.20.
- accuracy
str Can be “normal” (default) or “accurate”, which gives the most accurate coil definition but is typically not necessary for real-world data.
New in version 0.24.
- tol
float Final accuracy of the optimization (see
rhoendargument ofscipy.optimize.fmin_cobyla()).New in version 0.24.
- verbosebool |
str|int|None Control verbosity of the logging output. If
None, use the default verbosity level. See the logging documentation andmne.verbose()for details. Should only be passed as a keyword argument.
- evokedinstance of
- Returns:
- dipinstance of
DipoleorDipoleFixed The dipole fits. A
mne.DipoleFixedis returned ifposandoriare both not None, otherwise amne.Dipoleis returned.- residualinstance of
Evoked The M-EEG data channels with the fitted dipolar activity removed.
- dipinstance of
Notes
New in version 0.9.0.
Examples using mne.fit_dipole#
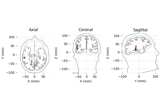
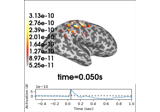
Source localization with equivalent current dipole (ECD) fit


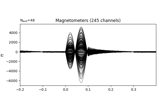

Plot sensor denoising using oversampled temporal projection

Computing source timecourses with an XFit-like multi-dipole model