Note
Go to the end to download the full example code.
Decoding sensor space data with generalization across time and conditions#
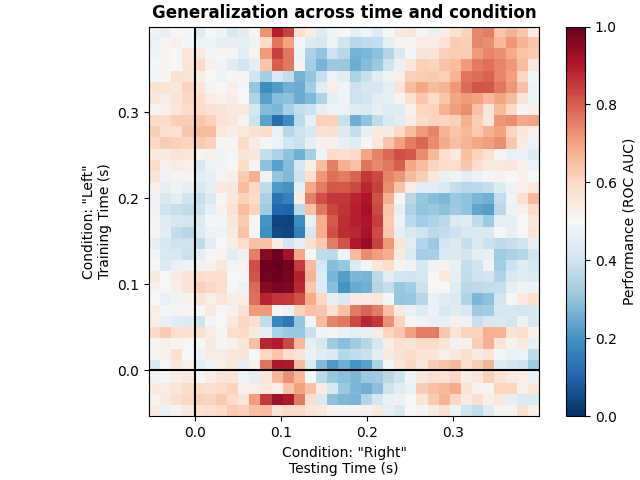
This example runs the analysis described in [1]. It illustrates how one can fit a linear classifier to identify a discriminatory topography at a given time instant and subsequently assess whether this linear model can accurately predict all of the time samples of a second set of conditions.
# Authors: Jean-Rémi King <jeanremi.king@gmail.com>
# Alexandre Gramfort <alexandre.gramfort@inria.fr>
# Denis Engemann <denis.engemann@gmail.com>
#
# License: BSD-3-Clause
# Copyright the MNE-Python contributors.
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
import mne
from mne.datasets import sample
from mne.decoding import GeneralizingEstimator
# Preprocess data
data_path = sample.data_path()
# Load and filter data, set up epochs
meg_path = data_path / "MEG" / "sample"
raw_fname = meg_path / "sample_audvis_filt-0-40_raw.fif"
events_fname = meg_path / "sample_audvis_filt-0-40_raw-eve.fif"
raw = mne.io.read_raw_fif(raw_fname, preload=True)
picks = mne.pick_types(raw.info, meg=True, exclude="bads") # Pick MEG channels
raw.filter(1.0, 30.0, fir_design="firwin") # Band pass filtering signals
events = mne.read_events(events_fname)
event_id = {
"Auditory/Left": 1,
"Auditory/Right": 2,
"Visual/Left": 3,
"Visual/Right": 4,
}
tmin = -0.050
tmax = 0.400
# decimate to make the example faster to run, but then use verbose='error' in
# the Epochs constructor to suppress warning about decimation causing aliasing
decim = 2
epochs = mne.Epochs(
raw,
events,
event_id=event_id,
tmin=tmin,
tmax=tmax,
proj=True,
picks=picks,
baseline=None,
preload=True,
reject=dict(mag=5e-12),
decim=decim,
verbose="error",
)
Opening raw data file /home/circleci/mne_data/MNE-sample-data/MEG/sample/sample_audvis_filt-0-40_raw.fif...
Read a total of 4 projection items:
PCA-v1 (1 x 102) idle
PCA-v2 (1 x 102) idle
PCA-v3 (1 x 102) idle
Average EEG reference (1 x 60) idle
Range : 6450 ... 48149 = 42.956 ... 320.665 secs
Ready.
Reading 0 ... 41699 = 0.000 ... 277.709 secs...
Filtering raw data in 1 contiguous segment
Setting up band-pass filter from 1 - 30 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 1.00
- Lower transition bandwidth: 1.00 Hz (-6 dB cutoff frequency: 0.50 Hz)
- Upper passband edge: 30.00 Hz
- Upper transition bandwidth: 7.50 Hz (-6 dB cutoff frequency: 33.75 Hz)
- Filter length: 497 samples (3.310 s)
We will train the classifier on all left visual vs auditory trials and test on all right visual vs auditory trials.
clf = make_pipeline(
StandardScaler(),
LogisticRegression(solver="liblinear"), # liblinear is faster than lbfgs
)
time_gen = GeneralizingEstimator(clf, scoring="roc_auc", n_jobs=None, verbose=True)
# Fit classifiers on the epochs where the stimulus was presented to the left.
# Note that the experimental condition y indicates auditory or visual
time_gen.fit(X=epochs["Left"].get_data(copy=False), y=epochs["Left"].events[:, 2] > 2)
0%| | Fitting GeneralizingEstimator : 0/35 [00:00<?, ?it/s]
3%|▎ | Fitting GeneralizingEstimator : 1/35 [00:00<00:01, 29.02it/s]
6%|▌ | Fitting GeneralizingEstimator : 2/35 [00:00<00:01, 29.22it/s]
11%|█▏ | Fitting GeneralizingEstimator : 4/35 [00:00<00:00, 39.67it/s]
14%|█▍ | Fitting GeneralizingEstimator : 5/35 [00:00<00:00, 36.83it/s]
17%|█▋ | Fitting GeneralizingEstimator : 6/35 [00:00<00:00, 35.25it/s]
26%|██▌ | Fitting GeneralizingEstimator : 9/35 [00:00<00:00, 45.15it/s]
31%|███▏ | Fitting GeneralizingEstimator : 11/35 [00:00<00:00, 47.33it/s]
37%|███▋ | Fitting GeneralizingEstimator : 13/35 [00:00<00:00, 48.92it/s]
46%|████▌ | Fitting GeneralizingEstimator : 16/35 [00:00<00:00, 54.25it/s]
51%|█████▏ | Fitting GeneralizingEstimator : 18/35 [00:00<00:00, 54.79it/s]
57%|█████▋ | Fitting GeneralizingEstimator : 20/35 [00:00<00:00, 55.25it/s]
63%|██████▎ | Fitting GeneralizingEstimator : 22/35 [00:00<00:00, 55.68it/s]
69%|██████▊ | Fitting GeneralizingEstimator : 24/35 [00:00<00:00, 55.93it/s]
74%|███████▍ | Fitting GeneralizingEstimator : 26/35 [00:00<00:00, 56.26it/s]
80%|████████ | Fitting GeneralizingEstimator : 28/35 [00:00<00:00, 56.54it/s]
89%|████████▊ | Fitting GeneralizingEstimator : 31/35 [00:00<00:00, 59.28it/s]
94%|█████████▍| Fitting GeneralizingEstimator : 33/35 [00:00<00:00, 59.29it/s]
100%|██████████| Fitting GeneralizingEstimator : 35/35 [00:00<00:00, 60.82it/s]
100%|██████████| Fitting GeneralizingEstimator : 35/35 [00:00<00:00, 58.04it/s]
Score on the epochs where the stimulus was presented to the right.
scores = time_gen.score(
X=epochs["Right"].get_data(copy=False), y=epochs["Right"].events[:, 2] > 2
)
0%| | Scoring GeneralizingEstimator : 0/1225 [00:00<?, ?it/s]
0%| | Scoring GeneralizingEstimator : 3/1225 [00:00<00:14, 82.89it/s]
1%| | Scoring GeneralizingEstimator : 7/1225 [00:00<00:12, 100.61it/s]
1%| | Scoring GeneralizingEstimator : 11/1225 [00:00<00:11, 106.80it/s]
1%| | Scoring GeneralizingEstimator : 13/1225 [00:00<00:12, 94.17it/s]
1%| | Scoring GeneralizingEstimator : 15/1225 [00:00<00:13, 86.52it/s]
2%|▏ | Scoring GeneralizingEstimator : 19/1225 [00:00<00:13, 92.48it/s]
2%|▏ | Scoring GeneralizingEstimator : 20/1225 [00:00<00:14, 82.12it/s]
2%|▏ | Scoring GeneralizingEstimator : 24/1225 [00:00<00:13, 87.50it/s]
2%|▏ | Scoring GeneralizingEstimator : 26/1225 [00:00<00:14, 83.54it/s]
2%|▏ | Scoring GeneralizingEstimator : 29/1225 [00:00<00:14, 84.19it/s]
3%|▎ | Scoring GeneralizingEstimator : 31/1225 [00:00<00:14, 81.31it/s]
3%|▎ | Scoring GeneralizingEstimator : 34/1225 [00:00<00:14, 81.96it/s]
3%|▎ | Scoring GeneralizingEstimator : 35/1225 [00:00<00:15, 76.67it/s]
3%|▎ | Scoring GeneralizingEstimator : 35/1225 [00:00<00:15, 79.04it/s]
Plot
fig, ax = plt.subplots(layout="constrained")
im = ax.matshow(
scores,
vmin=0,
vmax=1.0,
cmap="RdBu_r",
origin="lower",
extent=epochs.times[[0, -1, 0, -1]],
)
ax.axhline(0.0, color="k")
ax.axvline(0.0, color="k")
ax.xaxis.set_ticks_position("bottom")
ax.set_xlabel(
'Condition: "Right"\nTesting Time (s)',
)
ax.set_ylabel('Condition: "Left"\nTraining Time (s)')
ax.set_title("Generalization across time and condition", fontweight="bold")
fig.colorbar(im, ax=ax, label="Performance (ROC AUC)")
plt.show()
References#
Total running time of the script: (0 minutes 3.332 seconds)