Note
Go to the end to download the full example code.
Receptive Field Estimation and Prediction#
This example reproduces figures from Lalor et al.’s mTRF toolbox in
MATLAB [1]. We will show how the
mne.decoding.ReceptiveField class
can perform a similar function along with scikit-learn. We will first fit a
linear encoding model using the continuously-varying speech envelope to predict
activity of a 128 channel EEG system. Then, we will take the reverse approach
and try to predict the speech envelope from the EEG (known in the literature
as a decoding model, or simply stimulus reconstruction).
# Authors: Chris Holdgraf <choldgraf@gmail.com>
# Eric Larson <larson.eric.d@gmail.com>
# Nicolas Barascud <nicolas.barascud@ens.fr>
#
# License: BSD-3-Clause
# Copyright the MNE-Python contributors.
from os.path import join
import matplotlib.pyplot as plt
import numpy as np
from scipy.io import loadmat
from sklearn.model_selection import KFold
from sklearn.preprocessing import scale
import mne
from mne.decoding import ReceptiveField
Load the data from the publication#
First we will load the data collected in [1]. In this experiment subjects listened to natural speech. Raw EEG and the speech stimulus are provided. We will load these below, downsampling the data in order to speed up computation since we know that our features are primarily low-frequency in nature. Then we’ll visualize both the EEG and speech envelope.
path = mne.datasets.mtrf.data_path()
decim = 2
data = loadmat(join(path, "speech_data.mat"))
raw = data["EEG"].T
speech = data["envelope"].T
sfreq = float(data["Fs"].item())
sfreq /= decim
speech = mne.filter.resample(speech, down=decim, method="polyphase")
raw = mne.filter.resample(raw, down=decim, method="polyphase")
# Read in channel positions and create our MNE objects from the raw data
montage = mne.channels.make_standard_montage("biosemi128")
info = mne.create_info(montage.ch_names, sfreq, "eeg").set_montage(montage)
raw = mne.io.RawArray(raw, info)
n_channels = len(raw.ch_names)
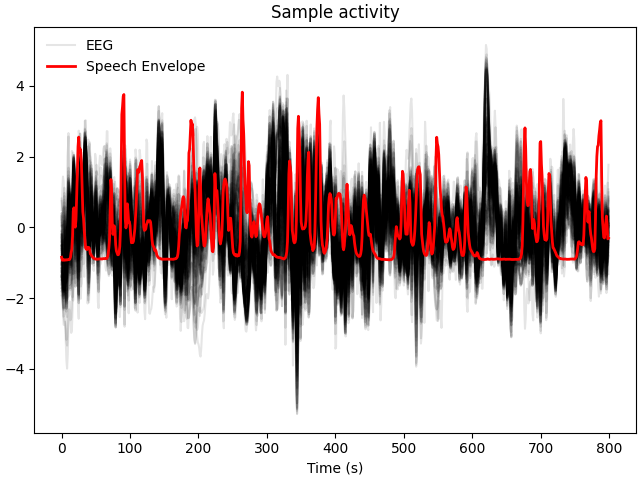
# Plot a sample of brain and stimulus activity
fig, ax = plt.subplots(layout="constrained")
lns = ax.plot(scale(raw[:, :800][0].T), color="k", alpha=0.1)
ln1 = ax.plot(scale(speech[0, :800]), color="r", lw=2)
ax.legend([lns[0], ln1[0]], ["EEG", "Speech Envelope"], frameon=False)
ax.set(title="Sample activity", xlabel="Time (s)")
Polyphase resampling neighborhood: ±2 input samples
Polyphase resampling neighborhood: ±2 input samples
Creating RawArray with float64 data, n_channels=128, n_times=7677
Range : 0 ... 7676 = 0.000 ... 119.938 secs
Ready.
Create and fit a receptive field model#
We will construct an encoding model to find the linear relationship between a time-delayed version of the speech envelope and the EEG signal. This allows us to make predictions about the response to new stimuli.
# Define the delays that we will use in the receptive field
tmin, tmax = -0.2, 0.4
# Initialize the model
rf = ReceptiveField(
tmin, tmax, sfreq, feature_names=["envelope"], estimator=1.0, scoring="corrcoef"
)
# We'll have (tmax - tmin) * sfreq delays
# and an extra 2 delays since we are inclusive on the beginning / end index
n_delays = int((tmax - tmin) * sfreq) + 2
n_splits = 3
cv = KFold(n_splits)
# Prepare model data (make time the first dimension)
speech = speech.T
Y, _ = raw[:] # Outputs for the model
Y = Y.T
# Iterate through splits, fit the model, and predict/test on held-out data
coefs = np.zeros((n_splits, n_channels, n_delays))
scores = np.zeros((n_splits, n_channels))
for ii, (train, test) in enumerate(cv.split(speech)):
print(f"split {ii + 1} / {n_splits}")
rf.fit(speech[train], Y[train])
scores[ii] = rf.score(speech[test], Y[test])
# coef_ is shape (n_outputs, n_features, n_delays). we only have 1 feature
coefs[ii] = rf.coef_[:, 0, :]
times = rf.delays_ / float(rf.sfreq)
# Average scores and coefficients across CV splits
mean_coefs = coefs.mean(axis=0)
mean_scores = scores.mean(axis=0)
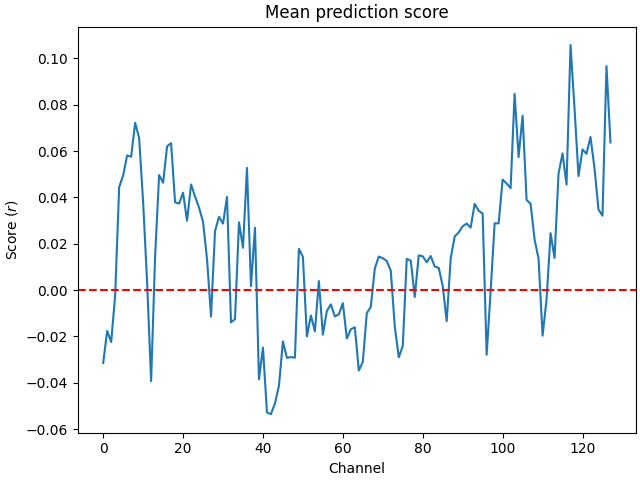
# Plot mean prediction scores across all channels
fig, ax = plt.subplots(layout="constrained")
ix_chs = np.arange(n_channels)
ax.plot(ix_chs, mean_scores)
ax.axhline(0, ls="--", color="r")
ax.set(title="Mean prediction score", xlabel="Channel", ylabel="Score ($r$)")
split 1 / 3
Fitting 1 epochs, 1 channels
0%| | Sample : 0/2 [00:00<?, ?it/s]
50%|█████ | Sample : 1/2 [00:06<00:06, 6.71s/it]split 2 / 3
Fitting 1 epochs, 1 channels
0%| | Sample : 0/2 [00:00<?, ?it/s]
100%|██████████| Sample : 2/2 [00:00<00:00, 71.72it/s]
100%|██████████| Sample : 2/2 [00:00<00:00, 71.09it/s]
split 3 / 3
Fitting 1 epochs, 1 channels
0%| | Sample : 0/2 [00:00<?, ?it/s]
100%|██████████| Sample : 2/2 [00:00<00:00, 71.99it/s]
100%|██████████| Sample : 2/2 [00:00<00:00, 71.38it/s]
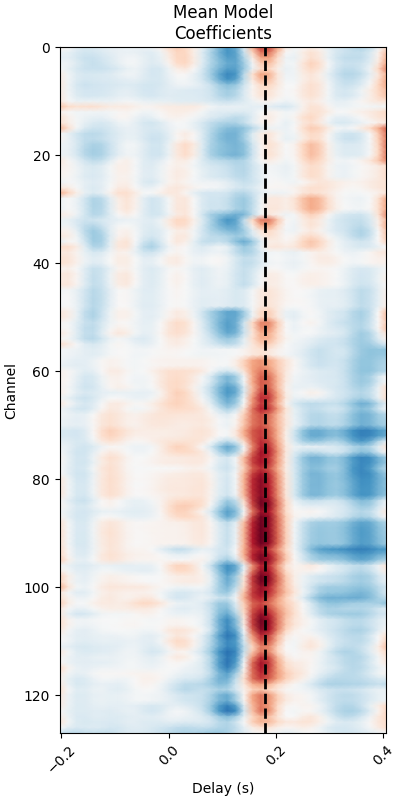
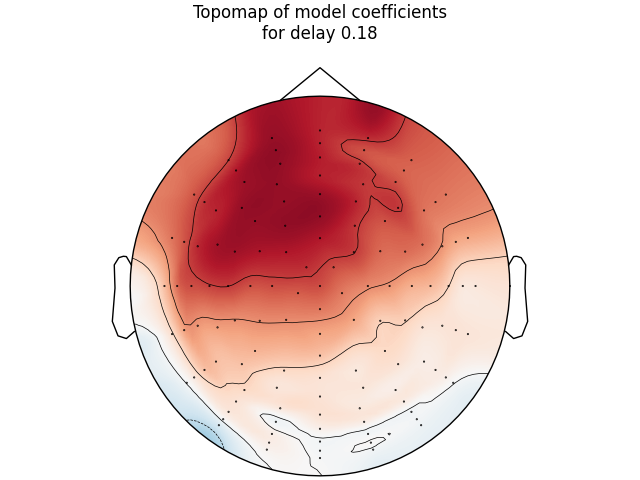
Investigate model coefficients#
Finally, we will look at how the linear coefficients (sometimes referred to as beta values) are distributed across time delays as well as across the scalp. We will recreate figure 1 and figure 2 from [1].
# Print mean coefficients across all time delays / channels (see Fig 1)
time_plot = 0.180 # For highlighting a specific time.
fig, ax = plt.subplots(figsize=(4, 8), layout="constrained")
max_coef = mean_coefs.max()
ax.pcolormesh(
times,
ix_chs,
mean_coefs,
cmap="RdBu_r",
vmin=-max_coef,
vmax=max_coef,
shading="gouraud",
)
ax.axvline(time_plot, ls="--", color="k", lw=2)
ax.set(
xlabel="Delay (s)",
ylabel="Channel",
title="Mean Model\nCoefficients",
xlim=times[[0, -1]],
ylim=[len(ix_chs) - 1, 0],
xticks=np.arange(tmin, tmax + 0.2, 0.2),
)
plt.setp(ax.get_xticklabels(), rotation=45)
# Make a topographic map of coefficients for a given delay (see Fig 2C)
ix_plot = np.argmin(np.abs(time_plot - times))
fig, ax = plt.subplots(layout="constrained")
mne.viz.plot_topomap(
mean_coefs[:, ix_plot], pos=info, axes=ax, show=False, vlim=(-max_coef, max_coef)
)
ax.set(title=f"Topomap of model coefficients\nfor delay {time_plot}")
Create and fit a stimulus reconstruction model#
We will now demonstrate another use case for the for the
mne.decoding.ReceptiveField class as we try to predict the stimulus
activity from the EEG data. This is known in the literature as a decoding, or
stimulus reconstruction model [1].
A decoding model aims to find the
relationship between the speech signal and a time-delayed version of the EEG.
This can be useful as we exploit all of the available neural data in a
multivariate context, compared to the encoding case which treats each M/EEG
channel as an independent feature. Therefore, decoding models might provide a
better quality of fit (at the expense of not controlling for stimulus
covariance), especially for low SNR stimuli such as speech.
# We use the same lags as in :footcite:`CrosseEtAl2016`. Negative lags now
# index the relationship
# between the neural response and the speech envelope earlier in time, whereas
# positive lags would index how a unit change in the amplitude of the EEG would
# affect later stimulus activity (obviously this should have an amplitude of
# zero).
tmin, tmax = -0.2, 0.0
# Initialize the model. Here the features are the EEG data. We also specify
# ``patterns=True`` to compute inverse-transformed coefficients during model
# fitting (cf. next section and :footcite:`HaufeEtAl2014`).
# We'll use a ridge regression estimator with an alpha value similar to
# Crosse et al.
sr = ReceptiveField(
tmin,
tmax,
sfreq,
feature_names=raw.ch_names,
estimator=1e4,
scoring="corrcoef",
patterns=True,
)
# We'll have (tmax - tmin) * sfreq delays
# and an extra 2 delays since we are inclusive on the beginning / end index
n_delays = int((tmax - tmin) * sfreq) + 2
n_splits = 3
cv = KFold(n_splits)
# Iterate through splits, fit the model, and predict/test on held-out data
coefs = np.zeros((n_splits, n_channels, n_delays))
patterns = coefs.copy()
scores = np.zeros((n_splits,))
for ii, (train, test) in enumerate(cv.split(speech)):
print(f"split {ii + 1} / {n_splits}")
sr.fit(Y[train], speech[train])
scores[ii] = sr.score(Y[test], speech[test])[0]
# coef_ is shape (n_outputs, n_features, n_delays). We have 128 features
coefs[ii] = sr.coef_[0, :, :]
patterns[ii] = sr.patterns_[0, :, :]
times = sr.delays_ / float(sr.sfreq)
# Average scores and coefficients across CV splits
mean_coefs = coefs.mean(axis=0)
mean_patterns = patterns.mean(axis=0)
mean_scores = scores.mean(axis=0)
max_coef = np.abs(mean_coefs).max()
max_patterns = np.abs(mean_patterns).max()
split 1 / 3
Fitting 1 epochs, 128 channels
0%| | Sample : 0/8384 [00:00<?, ?it/s]
0%| | Sample : 16/8384 [00:00<00:08, 996.82it/s]
2%|▏ | Sample : 147/8384 [00:00<00:01, 4675.16it/s]
3%|▎ | Sample : 278/8384 [00:00<00:01, 5901.66it/s]
5%|▍ | Sample : 409/8384 [00:00<00:01, 6515.65it/s]
6%|▋ | Sample : 538/8384 [00:00<00:01, 6848.02it/s]
8%|▊ | Sample : 667/8384 [00:00<00:01, 7069.99it/s]
10%|▉ | Sample : 798/8384 [00:00<00:01, 7251.42it/s]
11%|█ | Sample : 929/8384 [00:00<00:01, 7385.09it/s]
13%|█▎ | Sample : 1057/8384 [00:00<00:00, 7463.45it/s]
14%|█▍ | Sample : 1184/8384 [00:00<00:00, 7520.89it/s]
16%|█▌ | Sample : 1308/8384 [00:00<00:00, 7544.50it/s]
17%|█▋ | Sample : 1430/8384 [00:00<00:00, 7547.54it/s]
19%|█▊ | Sample : 1553/8384 [00:00<00:00, 7558.77it/s]
20%|█▉ | Sample : 1675/8384 [00:00<00:00, 7560.71it/s]
21%|██▏ | Sample : 1799/8384 [00:00<00:00, 7577.99it/s]
23%|██▎ | Sample : 1923/8384 [00:00<00:00, 7589.69it/s]
24%|██▍ | Sample : 2045/8384 [00:00<00:00, 7589.89it/s]
26%|██▌ | Sample : 2172/8384 [00:00<00:00, 7617.83it/s]
27%|██▋ | Sample : 2299/8384 [00:00<00:00, 7638.81it/s]
29%|██▉ | Sample : 2428/8384 [00:00<00:00, 7667.46it/s]
30%|███ | Sample : 2555/8384 [00:00<00:00, 7685.14it/s]
32%|███▏ | Sample : 2681/8384 [00:00<00:00, 7695.05it/s]
33%|███▎ | Sample : 2804/8384 [00:00<00:00, 7689.79it/s]
35%|███▍ | Sample : 2930/8384 [00:00<00:00, 7702.29it/s]
36%|███▋ | Sample : 3056/8384 [00:00<00:00, 7711.84it/s]
38%|███▊ | Sample : 3183/8384 [00:00<00:00, 7723.74it/s]
39%|███▉ | Sample : 3306/8384 [00:00<00:00, 7721.33it/s]
41%|████ | Sample : 3431/8384 [00:00<00:00, 7724.40it/s]
42%|████▏ | Sample : 3557/8384 [00:00<00:00, 7733.84it/s]
44%|████▍ | Sample : 3680/8384 [00:00<00:00, 7727.46it/s]
45%|████▌ | Sample : 3804/8384 [00:00<00:00, 7728.70it/s]
47%|████▋ | Sample : 3930/8384 [00:00<00:00, 7734.94it/s]
48%|████▊ | Sample : 4053/8384 [00:00<00:00, 7730.88it/s]
50%|████▉ | Sample : 4178/8384 [00:00<00:00, 7734.23it/s]
51%|█████▏ | Sample : 4303/8384 [00:00<00:00, 7735.58it/s]
53%|█████▎ | Sample : 4427/8384 [00:00<00:00, 7733.94it/s]
54%|█████▍ | Sample : 4557/8384 [00:00<00:00, 7755.53it/s]
56%|█████▌ | Sample : 4687/8384 [00:00<00:00, 7776.09it/s]
57%|█████▋ | Sample : 4819/8384 [00:00<00:00, 7801.66it/s]
59%|█████▉ | Sample : 4950/8384 [00:00<00:00, 7822.42it/s]
61%|██████ | Sample : 5082/8384 [00:00<00:00, 7844.50it/s]
62%|██████▏ | Sample : 5215/8384 [00:00<00:00, 7868.61it/s]
64%|██████▎ | Sample : 5344/8384 [00:00<00:00, 7878.26it/s]
65%|██████▌ | Sample : 5476/8384 [00:00<00:00, 7897.92it/s]
67%|██████▋ | Sample : 5611/8384 [00:00<00:00, 7924.21it/s]
69%|██████▊ | Sample : 5745/8384 [00:00<00:00, 7947.73it/s]
70%|███████ | Sample : 5879/8384 [00:00<00:00, 7970.02it/s]
72%|███████▏ | Sample : 6011/8384 [00:00<00:00, 7982.14it/s]
73%|███████▎ | Sample : 6143/8384 [00:00<00:00, 7995.48it/s]
75%|███████▍ | Sample : 6277/8384 [00:00<00:00, 8012.92it/s]
76%|███████▋ | Sample : 6412/8384 [00:00<00:00, 8034.00it/s]
78%|███████▊ | Sample : 6546/8384 [00:00<00:00, 8052.09it/s]
80%|███████▉ | Sample : 6680/8384 [00:00<00:00, 8068.84it/s]
81%|████████▏ | Sample : 6814/8384 [00:00<00:00, 8084.70it/s]
83%|████████▎ | Sample : 6947/8384 [00:00<00:00, 8095.18it/s]
84%|████████▍ | Sample : 7082/8384 [00:00<00:00, 8110.89it/s]
86%|████████▌ | Sample : 7217/8384 [00:00<00:00, 8125.91it/s]
88%|████████▊ | Sample : 7351/8384 [00:00<00:00, 8137.49it/s]
89%|████████▉ | Sample : 7486/8384 [00:00<00:00, 8151.01it/s]
91%|█████████ | Sample : 7621/8384 [00:00<00:00, 8165.65it/s]
92%|█████████▏| Sample : 7754/8384 [00:00<00:00, 8171.36it/s]
94%|█████████▍| Sample : 7889/8384 [00:00<00:00, 8182.89it/s]
96%|█████████▌| Sample : 8022/8384 [00:01<00:00, 8186.64it/s]
97%|█████████▋| Sample : 8156/8384 [00:01<00:00, 8196.34it/s]
99%|█████████▉| Sample : 8289/8384 [00:01<00:00, 8199.59it/s]
100%|██████████| Sample : 8384/8384 [00:01<00:00, 7942.92it/s]
split 2 / 3
Fitting 1 epochs, 128 channels
0%| | Sample : 0/8384 [00:00<?, ?it/s]
0%| | Sample : 10/8384 [00:00<00:13, 624.51it/s]
2%|▏ | Sample : 140/8384 [00:00<00:01, 4454.62it/s]
3%|▎ | Sample : 270/8384 [00:00<00:01, 5724.29it/s]
5%|▍ | Sample : 397/8384 [00:00<00:01, 6314.91it/s]
6%|▋ | Sample : 524/8384 [00:00<00:01, 6663.58it/s]
8%|▊ | Sample : 649/8384 [00:00<00:01, 6878.59it/s]
9%|▉ | Sample : 778/8384 [00:00<00:01, 7068.62it/s]
11%|█ | Sample : 907/8384 [00:00<00:01, 7211.90it/s]
12%|█▏ | Sample : 1035/8384 [00:00<00:01, 7316.37it/s]
14%|█▍ | Sample : 1165/8384 [00:00<00:00, 7416.73it/s]
15%|█▌ | Sample : 1293/8384 [00:00<00:00, 7478.08it/s]
17%|█▋ | Sample : 1417/8384 [00:00<00:00, 7501.70it/s]
18%|█▊ | Sample : 1543/8384 [00:00<00:00, 7536.65it/s]
20%|█▉ | Sample : 1671/8384 [00:00<00:00, 7576.30it/s]
21%|██▏ | Sample : 1794/8384 [00:00<00:00, 7583.99it/s]
23%|██▎ | Sample : 1916/8384 [00:00<00:00, 7586.98it/s]
24%|██▍ | Sample : 2037/8384 [00:00<00:00, 7581.39it/s]
26%|██▌ | Sample : 2161/8384 [00:00<00:00, 7592.66it/s]
27%|██▋ | Sample : 2283/8384 [00:00<00:00, 7592.90it/s]
29%|██▊ | Sample : 2407/8384 [00:00<00:00, 7600.77it/s]
30%|███ | Sample : 2536/8384 [00:00<00:00, 7634.85it/s]
32%|███▏ | Sample : 2666/8384 [00:00<00:00, 7670.30it/s]
33%|███▎ | Sample : 2793/8384 [00:00<00:00, 7689.03it/s]
35%|███▍ | Sample : 2922/8384 [00:00<00:00, 7714.57it/s]
36%|███▋ | Sample : 3054/8384 [00:00<00:00, 7747.96it/s]
38%|███▊ | Sample : 3187/8384 [00:00<00:00, 7785.00it/s]
40%|███▉ | Sample : 3321/8384 [00:00<00:00, 7821.09it/s]
41%|████ | Sample : 3455/8384 [00:00<00:00, 7853.64it/s]
43%|████▎ | Sample : 3586/8384 [00:00<00:00, 7871.21it/s]
44%|████▍ | Sample : 3714/8384 [00:00<00:00, 7877.61it/s]
46%|████▌ | Sample : 3843/8384 [00:00<00:00, 7888.33it/s]
47%|████▋ | Sample : 3977/8384 [00:00<00:00, 7915.06it/s]
49%|████▉ | Sample : 4109/8384 [00:00<00:00, 7932.89it/s]
51%|█████ | Sample : 4239/8384 [00:00<00:00, 7943.42it/s]
52%|█████▏ | Sample : 4372/8384 [00:00<00:00, 7965.28it/s]
54%|█████▎ | Sample : 4505/8384 [00:00<00:00, 7983.43it/s]
55%|█████▌ | Sample : 4640/8384 [00:00<00:00, 8006.46it/s]
57%|█████▋ | Sample : 4775/8384 [00:00<00:00, 8030.53it/s]
59%|█████▊ | Sample : 4910/8384 [00:00<00:00, 8051.94it/s]
60%|██████ | Sample : 5045/8384 [00:00<00:00, 8073.68it/s]
62%|██████▏ | Sample : 5179/8384 [00:00<00:00, 8089.48it/s]
63%|██████▎ | Sample : 5309/8384 [00:00<00:00, 8088.50it/s]
65%|██████▍ | Sample : 5443/8384 [00:00<00:00, 8104.50it/s]
67%|██████▋ | Sample : 5578/8384 [00:00<00:00, 8122.77it/s]
68%|██████▊ | Sample : 5713/8384 [00:00<00:00, 8137.94it/s]
70%|██████▉ | Sample : 5847/8384 [00:00<00:00, 8148.47it/s]
71%|███████▏ | Sample : 5980/8384 [00:00<00:00, 8156.09it/s]
73%|███████▎ | Sample : 6112/8384 [00:00<00:00, 8158.35it/s]
74%|███████▍ | Sample : 6245/8384 [00:00<00:00, 8165.00it/s]
76%|███████▌ | Sample : 6380/8384 [00:00<00:00, 8178.39it/s]
78%|███████▊ | Sample : 6514/8384 [00:00<00:00, 8187.32it/s]
79%|███████▉ | Sample : 6649/8384 [00:00<00:00, 8199.49it/s]
81%|████████ | Sample : 6784/8384 [00:00<00:00, 8210.80it/s]
83%|████████▎ | Sample : 6918/8384 [00:00<00:00, 8218.03it/s]
84%|████████▍ | Sample : 7052/8384 [00:00<00:00, 8224.54it/s]
86%|████████▌ | Sample : 7187/8384 [00:00<00:00, 8233.39it/s]
87%|████████▋ | Sample : 7322/8384 [00:00<00:00, 8241.16it/s]
89%|████████▉ | Sample : 7458/8384 [00:00<00:00, 8252.43it/s]
91%|█████████ | Sample : 7594/8384 [00:00<00:00, 8263.62it/s]
92%|█████████▏| Sample : 7730/8384 [00:00<00:00, 8273.17it/s]
94%|█████████▍| Sample : 7863/8384 [00:00<00:00, 8274.34it/s]
95%|█████████▌| Sample : 7998/8384 [00:00<00:00, 8280.61it/s]
97%|█████████▋| Sample : 8133/8384 [00:01<00:00, 8287.44it/s]
99%|█████████▊| Sample : 8266/8384 [00:01<00:00, 8287.21it/s]
100%|██████████| Sample : 8384/8384 [00:01<00:00, 8044.16it/s]
split 3 / 3
Fitting 1 epochs, 128 channels
0%| | Sample : 0/8384 [00:00<?, ?it/s]
0%| | Sample : 9/8384 [00:00<00:14, 561.60it/s]
2%|▏ | Sample : 137/8384 [00:00<00:01, 4361.44it/s]
3%|▎ | Sample : 266/8384 [00:00<00:01, 5641.47it/s]
5%|▍ | Sample : 394/8384 [00:00<00:01, 6264.56it/s]
6%|▌ | Sample : 520/8384 [00:00<00:01, 6611.81it/s]
8%|▊ | Sample : 642/8384 [00:00<00:01, 6798.87it/s]
9%|▉ | Sample : 767/8384 [00:00<00:01, 6963.99it/s]
11%|█ | Sample : 894/8384 [00:00<00:01, 7101.62it/s]
12%|█▏ | Sample : 1020/8384 [00:00<00:01, 7204.31it/s]
14%|█▎ | Sample : 1151/8384 [00:00<00:00, 7322.00it/s]
15%|█▌ | Sample : 1277/8384 [00:00<00:00, 7380.68it/s]
17%|█▋ | Sample : 1405/8384 [00:00<00:00, 7445.56it/s]
18%|█▊ | Sample : 1534/8384 [00:00<00:00, 7506.91it/s]
20%|█▉ | Sample : 1667/8384 [00:00<00:00, 7581.48it/s]
21%|██▏ | Sample : 1800/8384 [00:00<00:00, 7646.13it/s]
23%|██▎ | Sample : 1928/8384 [00:00<00:00, 7675.47it/s]
25%|██▍ | Sample : 2059/8384 [00:00<00:00, 7716.62it/s]
26%|██▌ | Sample : 2189/8384 [00:00<00:00, 7748.23it/s]
28%|██▊ | Sample : 2315/8384 [00:00<00:00, 7754.65it/s]
29%|██▉ | Sample : 2443/8384 [00:00<00:00, 7771.43it/s]
31%|███ | Sample : 2573/8384 [00:00<00:00, 7794.74it/s]
32%|███▏ | Sample : 2704/8384 [00:00<00:00, 7819.72it/s]
34%|███▍ | Sample : 2833/8384 [00:00<00:00, 7836.73it/s]
35%|███▌ | Sample : 2960/8384 [00:00<00:00, 7842.95it/s]
37%|███▋ | Sample : 3089/8384 [00:00<00:00, 7854.18it/s]
38%|███▊ | Sample : 3220/8384 [00:00<00:00, 7873.38it/s]
40%|███▉ | Sample : 3351/8384 [00:00<00:00, 7894.09it/s]
42%|████▏ | Sample : 3484/8384 [00:00<00:00, 7921.16it/s]
43%|████▎ | Sample : 3615/8384 [00:00<00:00, 7938.05it/s]
45%|████▍ | Sample : 3741/8384 [00:00<00:00, 7933.48it/s]
46%|████▌ | Sample : 3873/8384 [00:00<00:00, 7951.77it/s]
48%|████▊ | Sample : 4002/8384 [00:00<00:00, 7958.10it/s]
49%|████▉ | Sample : 4133/8384 [00:00<00:00, 7968.85it/s]
51%|█████ | Sample : 4262/8384 [00:00<00:00, 7972.54it/s]
52%|█████▏ | Sample : 4394/8384 [00:00<00:00, 7987.46it/s]
54%|█████▍ | Sample : 4526/8384 [00:00<00:00, 7999.70it/s]
56%|█████▌ | Sample : 4658/8384 [00:00<00:00, 8010.91it/s]
57%|█████▋ | Sample : 4792/8384 [00:00<00:00, 8030.97it/s]
59%|█████▉ | Sample : 4928/8384 [00:00<00:00, 8056.24it/s]
60%|██████ | Sample : 5063/8384 [00:00<00:00, 8077.44it/s]
62%|██████▏ | Sample : 5198/8384 [00:00<00:00, 8097.16it/s]
64%|██████▎ | Sample : 5331/8384 [00:00<00:00, 8108.13it/s]
65%|██████▌ | Sample : 5464/8384 [00:00<00:00, 8118.82it/s]
67%|██████▋ | Sample : 5599/8384 [00:00<00:00, 8134.66it/s]
68%|██████▊ | Sample : 5734/8384 [00:00<00:00, 8150.67it/s]
70%|███████ | Sample : 5869/8384 [00:00<00:00, 8163.44it/s]
72%|███████▏ | Sample : 6001/8384 [00:00<00:00, 8167.13it/s]
73%|███████▎ | Sample : 6134/8384 [00:00<00:00, 8172.46it/s]
75%|███████▍ | Sample : 6265/8384 [00:00<00:00, 8171.34it/s]
76%|███████▋ | Sample : 6398/8384 [00:00<00:00, 8176.18it/s]
78%|███████▊ | Sample : 6532/8384 [00:00<00:00, 8183.77it/s]
80%|███████▉ | Sample : 6667/8384 [00:00<00:00, 8195.40it/s]
81%|████████ | Sample : 6801/8384 [00:00<00:00, 8203.28it/s]
83%|████████▎ | Sample : 6935/8384 [00:00<00:00, 8212.07it/s]
84%|████████▍ | Sample : 7069/8384 [00:00<00:00, 8217.73it/s]
86%|████████▌ | Sample : 7204/8384 [00:00<00:00, 8226.43it/s]
88%|████████▊ | Sample : 7339/8384 [00:00<00:00, 8234.88it/s]
89%|████████▉ | Sample : 7473/8384 [00:00<00:00, 8238.65it/s]
91%|█████████ | Sample : 7608/8384 [00:00<00:00, 8247.58it/s]
92%|█████████▏| Sample : 7741/8384 [00:00<00:00, 8248.38it/s]
94%|█████████▍| Sample : 7874/8384 [00:00<00:00, 8251.30it/s]
95%|█████████▌| Sample : 8005/8384 [00:00<00:00, 8246.45it/s]
97%|█████████▋| Sample : 8140/8384 [00:01<00:00, 8254.09it/s]
99%|█████████▊| Sample : 8272/8384 [00:01<00:00, 8253.18it/s]
100%|██████████| Sample : 8384/8384 [00:01<00:00, 8049.34it/s]
Visualize stimulus reconstruction#
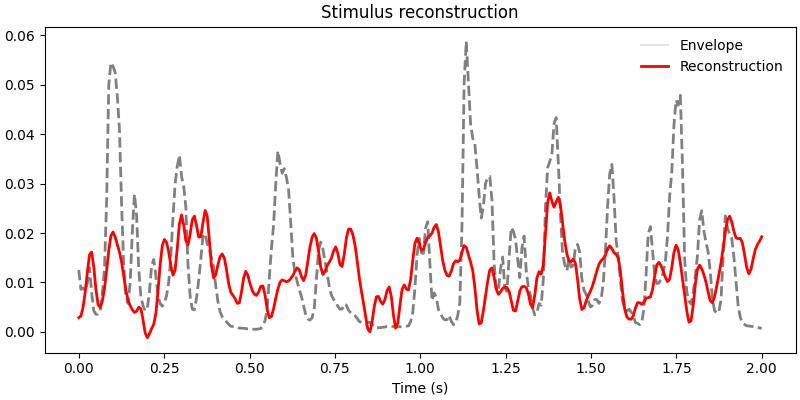
To get a sense of our model performance, we can plot the actual and predicted stimulus envelopes side by side.
y_pred = sr.predict(Y[test])
time = np.linspace(0, 2.0, 5 * int(sfreq))
fig, ax = plt.subplots(figsize=(8, 4), layout="constrained")
ax.plot(
time, speech[test][sr.valid_samples_][: int(5 * sfreq)], color="grey", lw=2, ls="--"
)
ax.plot(time, y_pred[sr.valid_samples_][: int(5 * sfreq)], color="r", lw=2)
ax.legend([lns[0], ln1[0]], ["Envelope", "Reconstruction"], frameon=False)
ax.set(title="Stimulus reconstruction")
ax.set_xlabel("Time (s)")
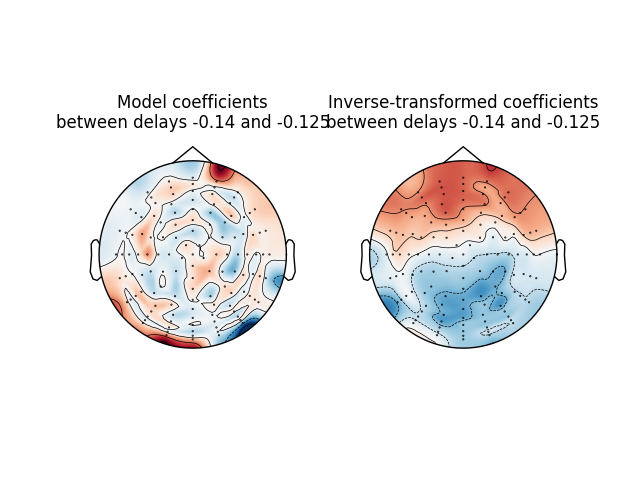
Investigate model coefficients#
Finally, we will look at how the decoding model coefficients are distributed across the scalp. We will attempt to recreate figure 5 from [1]. The decoding model weights reflect the channels that contribute most toward reconstructing the stimulus signal, but are not directly interpretable in a neurophysiological sense. Here we also look at the coefficients obtained via an inversion procedure [2], which have a more straightforward interpretation as their value (and sign) directly relates to the stimulus signal’s strength (and effect direction).
time_plot = (-0.140, -0.125) # To average between two timepoints.
ix_plot = np.arange(
np.argmin(np.abs(time_plot[0] - times)), np.argmin(np.abs(time_plot[1] - times))
)
fig, ax = plt.subplots(1, 2)
mne.viz.plot_topomap(
np.mean(mean_coefs[:, ix_plot], axis=1),
pos=info,
axes=ax[0],
show=False,
vlim=(-max_coef, max_coef),
)
ax[0].set(title=f"Model coefficients\nbetween delays {time_plot[0]} and {time_plot[1]}")
mne.viz.plot_topomap(
np.mean(mean_patterns[:, ix_plot], axis=1),
pos=info,
axes=ax[1],
show=False,
vlim=(-max_patterns, max_patterns),
)
ax[1].set(
title=(
f"Inverse-transformed coefficients\nbetween delays {time_plot[0]} and "
f"{time_plot[1]}"
)
)
References#
Total running time of the script: (0 minutes 15.521 seconds)